

FPGA硬件算法(1)长江后浪推前浪之流水线
前言
用长江后浪推前浪来形容流水线,可谓之形象。硬件中的流水线技术,就是将数据一级一级的推进,后一级推进前一级,前一级则更近一层。
为什么要使用流水线?这要从组合逻辑的延迟话题说起,之后引出时序逻辑的核心元素触发器或者寄存器,进而进入流水线的正式内容。
流水线是解决时序问题的关键技术,起到疏导作用,一提到疏导,这关键程度可见一斑。之所以需要疏导,就意味着堵塞了,堵塞了的系统是有问题的,例如人体内的循环堵塞了,那可是要出人命的。
电路也是如此,时序电路一旦堵塞,那它就不可能正常工作,不能正常工作的电路,就是废物。
下面我们慢慢谈起。
组合逻辑的延迟
组合逻辑是有天生的延迟属性,数据从一个电路元件的一端到另外一端需要花费时间,多个元件的组合呢,更不必多说,需要叠加的时间,还有元件之间的布线(可不要小看布线,芯片中的布线延迟不容忽视,也许你认为这么小的芯片中,布线延迟能有多大?试着想一下人体的小肠吧,弯弯曲曲,小小的肚子中小肠可长达4到6米。),信号在这些元素之间传递,类似于人走路,需要时间,这个时间在电路中称之为延迟。
如下图:

信号从输入到输出,经过3段组合逻辑电路,假设忽略布线延迟。每一段组合逻辑的延迟对应为delay1,delay2,delay3等。
那么上面的组合逻辑延迟的叠加就是:
total_delay = delay1 + delay2 + delay3;
如果该组合逻辑是时序逻辑中的一段,那么就需要时序逻辑的时钟周期必须大于该总延迟。
即 T > total_delay = delay1 + delay2 + delay3;
如果这个时间很长,那么时钟周期就会很大,时钟频率就会很低,那么这个设计就不太高效,完成一个任务,需要花费的时间过长。
且如果我们使用了稍快的时钟作为系统时钟,那么多大的组合逻辑延迟会导致设计的时序不过,进而导致功能有问题,也就是一个失败的设计。
如果去改善呢?
下面时序逻辑的主角出场!
D触发器与寄存器
触发器有很多,为什么是D触发器?
因为D触发器最方便使用,无论是ASIC还是FPGA,内部都使用D触发器,而不是其他!
D触发器是时序逻辑的基本组成部分,如下图:
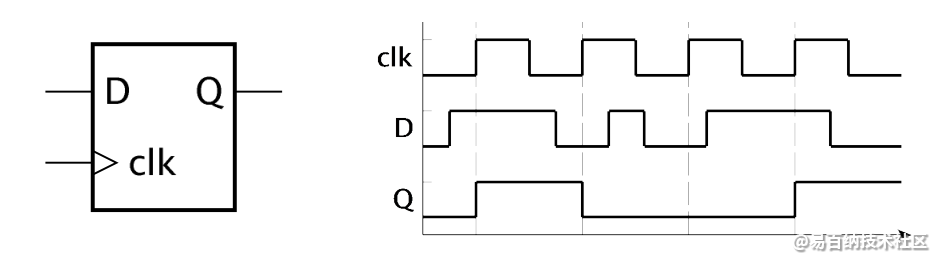
D触发器的特性就是在时钟有效沿采样输入信号作为输出。大多数的场合还是以时钟上升沿为有效沿,例如上图就是以此为例。
在时钟的其他时刻,D触发器都保持着其输出值,只有在时钟有效沿时才更新其输出值。
触发器是1bit的储存单元。
如果需要存储多bit信号,就需要多个触发器,我们称其为寄存器,其实也可以称触发器为寄存器,只不过这个寄存器的位宽为1,我们也经常这么称呼。
如下图:
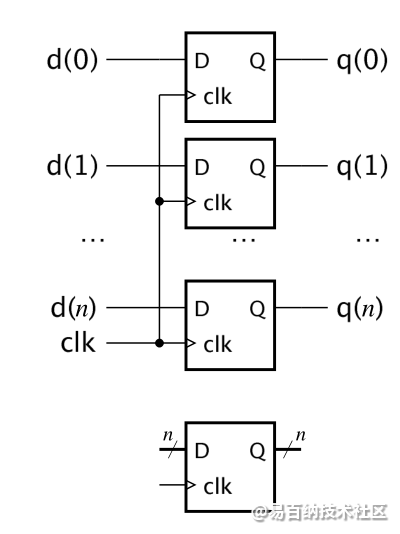
该图显示了多个触发器构成的寄存器的情况。
对其建模,Verilog语言描述为:
wire [n:0] d;
reg [n:0] q;
...
always @( posedge clk)
q <= d;使用寄存器改善组合延迟
说完寄存器,我们需要赶紧回到上述话题,多长的组合逻辑延迟:
上面也已经说了,这样长的组合延迟会导致时序难以通过,我们的优化方式为:
对每一个组合逻辑电路之间插入一个寄存器,如下:

假设每一个组合逻辑的延迟都不必系统时钟周期大。
我们知道寄存器的特性是时钟有效沿采样输入值,那么看来,这个输入到输出需要3个时钟周期才能完成。
乍一看,好像花费了更多的时间来传递这个信号,其实并非如此,不可如此短视。
我们的输入到输出的数据不可能只有一个,是源源不断的从输入到输出。
数据经过三个周期的时间从输入到输出之后,后面的每个输出数据之间的间隔只有一个时钟周期。
这便是一个简单的流水的实际例子。
通过寄存器切断了多长的组合逻辑,会让寄存器到寄存器之间的延迟变小,这样的话可以允许系统使用更小周期,即更高频率的时钟,设计需要更短的时间来处理数据,提高了效率。
如果固定了时钟频率,那么更短的组合延迟,也会让时序更加轻而易举通过。
输入数据经过每一个寄存器,就像流水一般,一波一波流向下一个寄存器,最终流出最后一个寄存器,走向输出(拍入沙滩)。
流水线设计实战
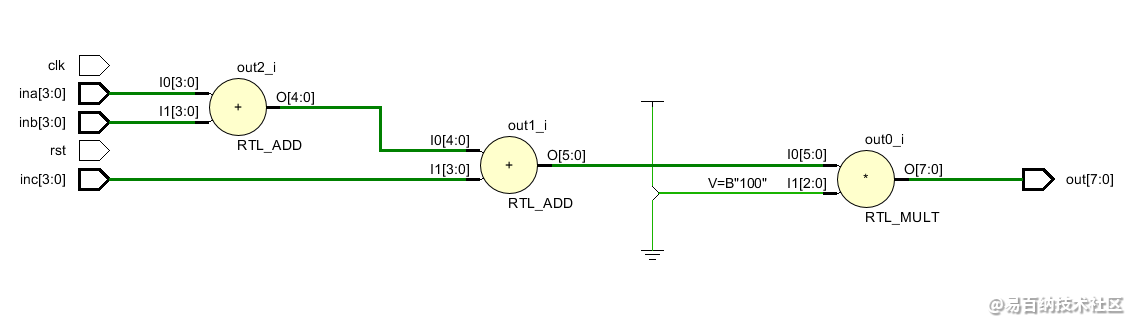
这个例子要求使用流水线的技术实现如下算术表达式:
sum = (a + b + c)* 4;
我一向提倡简单的模块可以先画出来,在设计出来,或者先设计出来,也得知道设计的电路长成什么样子,甚至在FPGA中综合成什么样子?
如下图,就是我们针对这个问题设计的流水线结构:
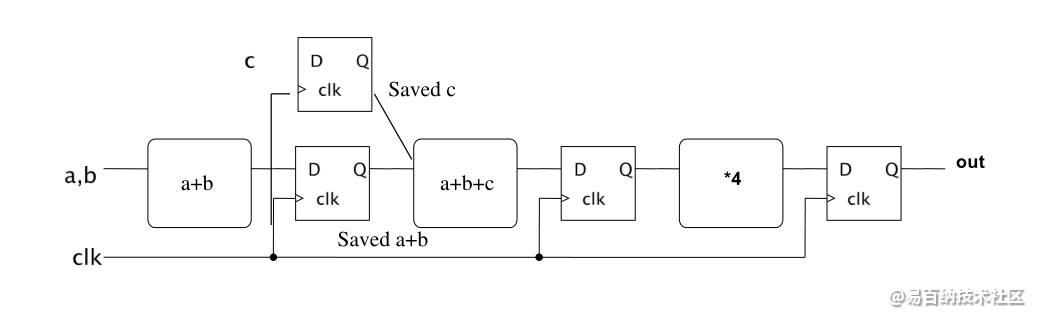
数据从输入到输出需要3个时钟得出结果。
我们实际设计的RTL设计如下:
always@(posedge clk or posedge rst) begin
if(rst) begin
a_plus_b <= 'd0;
c_d1 <= 'd0;
end
else begin
a_plus_b <= ina + inb;
c_d1 <= inc;
end
end
always@(posedge clk or posedge rst) begin
if(rst) begin
a_plus_b_plus_c <= 'd0;
out_mid <= 'd0;
end
else begin
a_plus_b_plus_c <= a_plus_b + c_d1;
out_mid <= a_plus_b_plus_c << 2;
end
endRTL原理图:
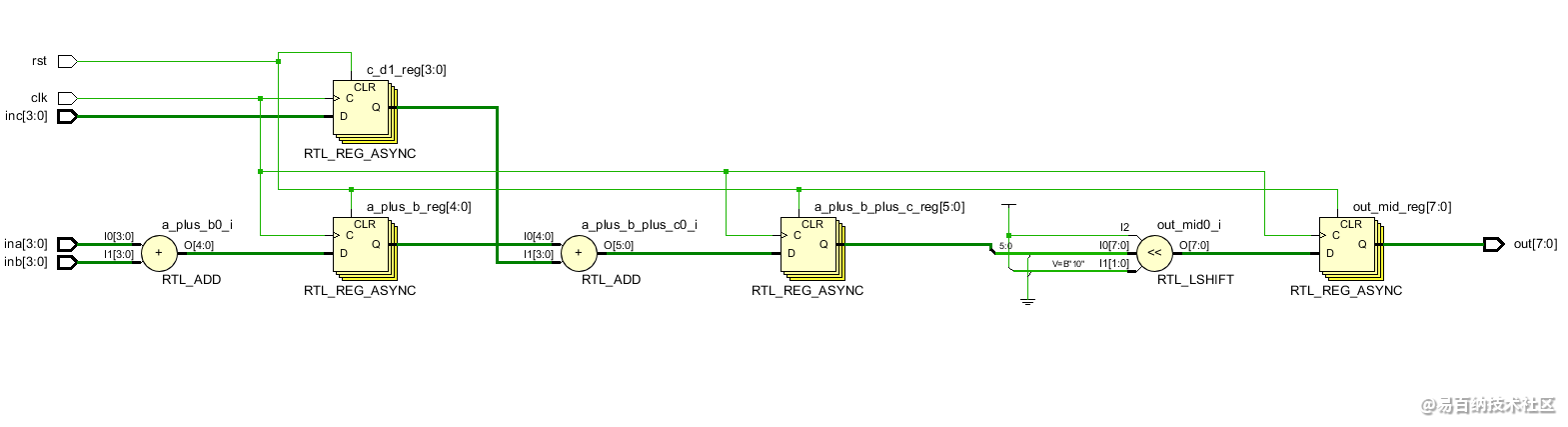
对应Xilinx的综合结果为:
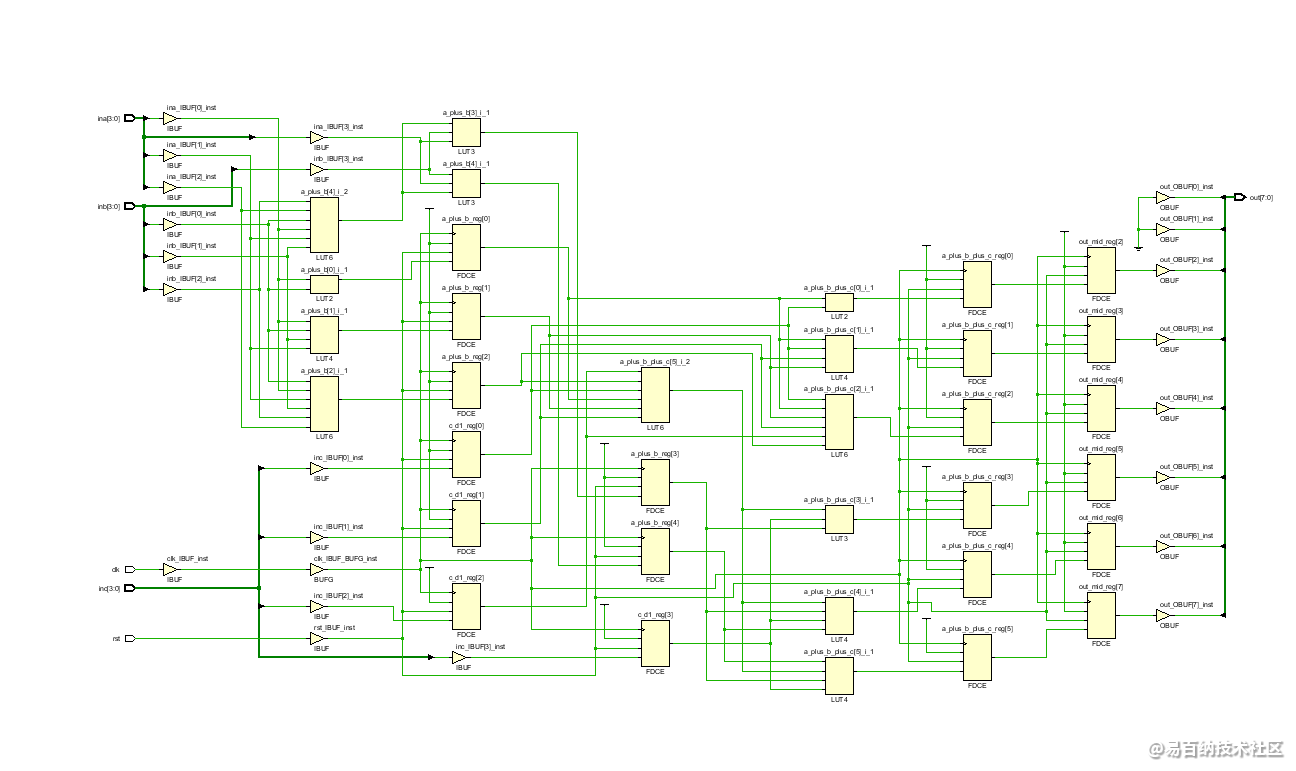
可见,架构还是一致,只不过加法器使用LUT实现了,还有一处细节:
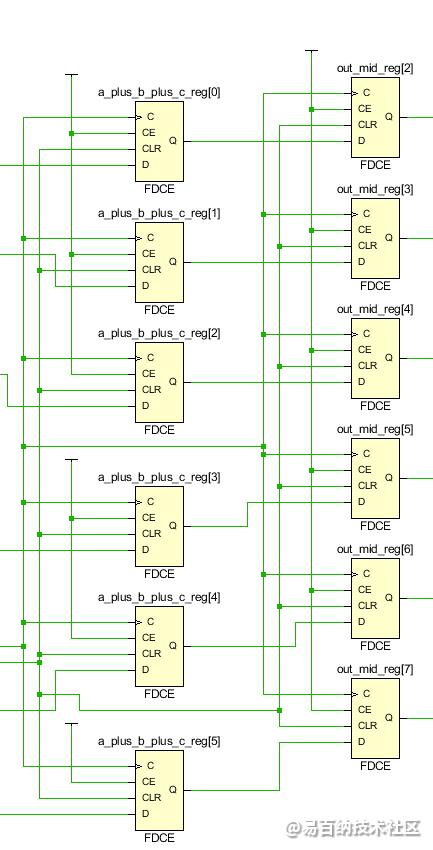
乘4的操作使用了移位寄存器实现,对a_puls_b_plus_c左移了2bit。
既然做到了这里,不如看看实现后的原理图:
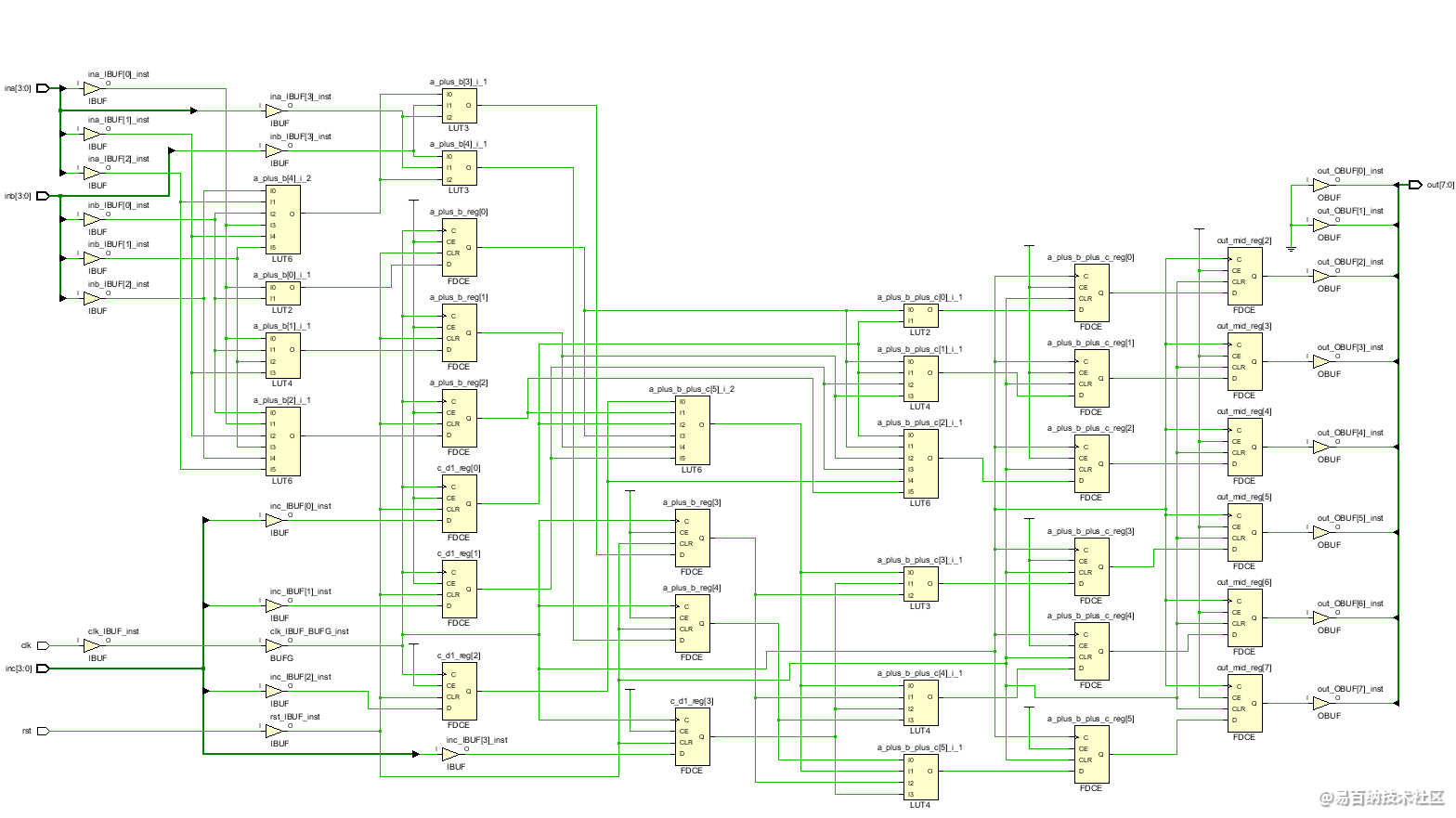
可见,实现后的原理图和综合后的原理图几乎没有差别,一方面是设计过于简单,另一方面是二者的原理图本身差别就不大,综合的综合库,实现的实现库,大同小异。
如果不使用用流水线呢?
例如直接相加再乘4:
assign out = (ina + inb + inc)*4;那么设计的RTL原理图为:
综合原理图:
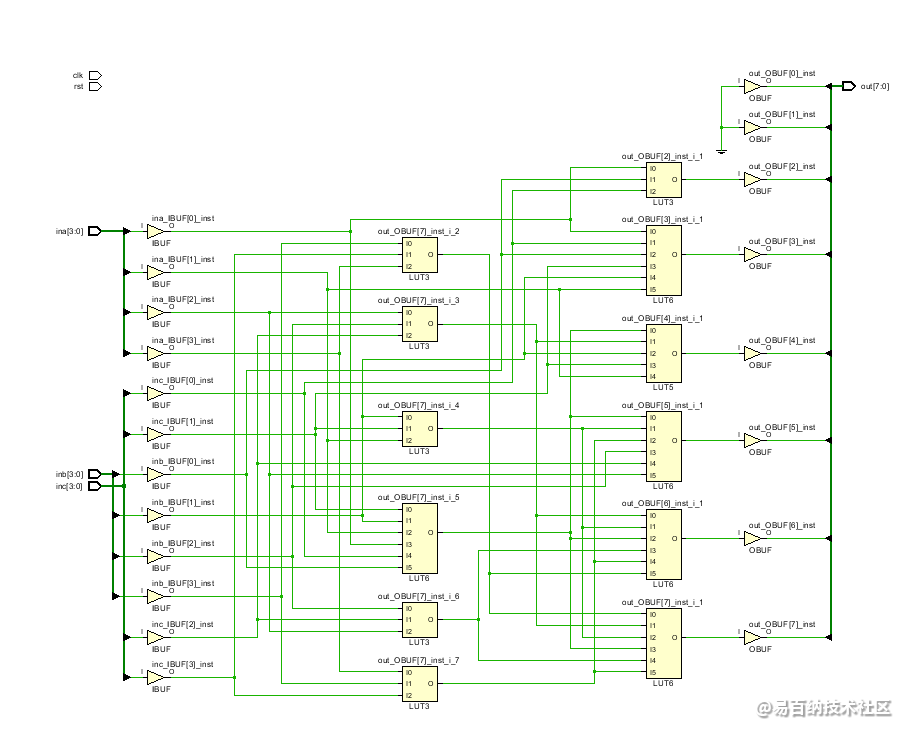
可见,使用了大量的LUT。
如果这样呢?
assign out = (ina + inb + inc) << 2;RTL原理图:
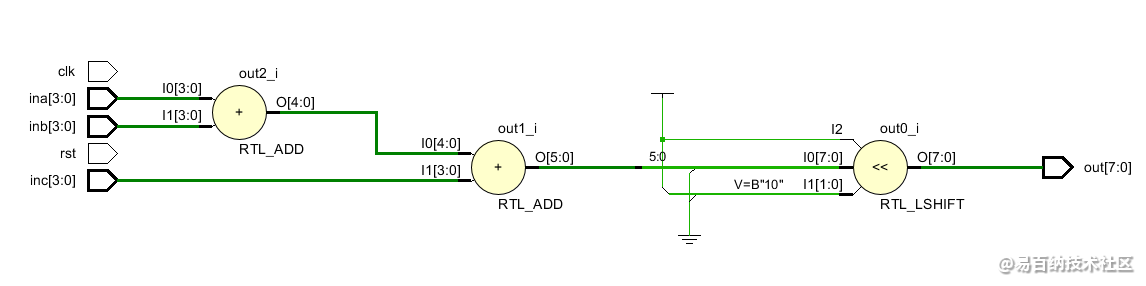
综合原理图:
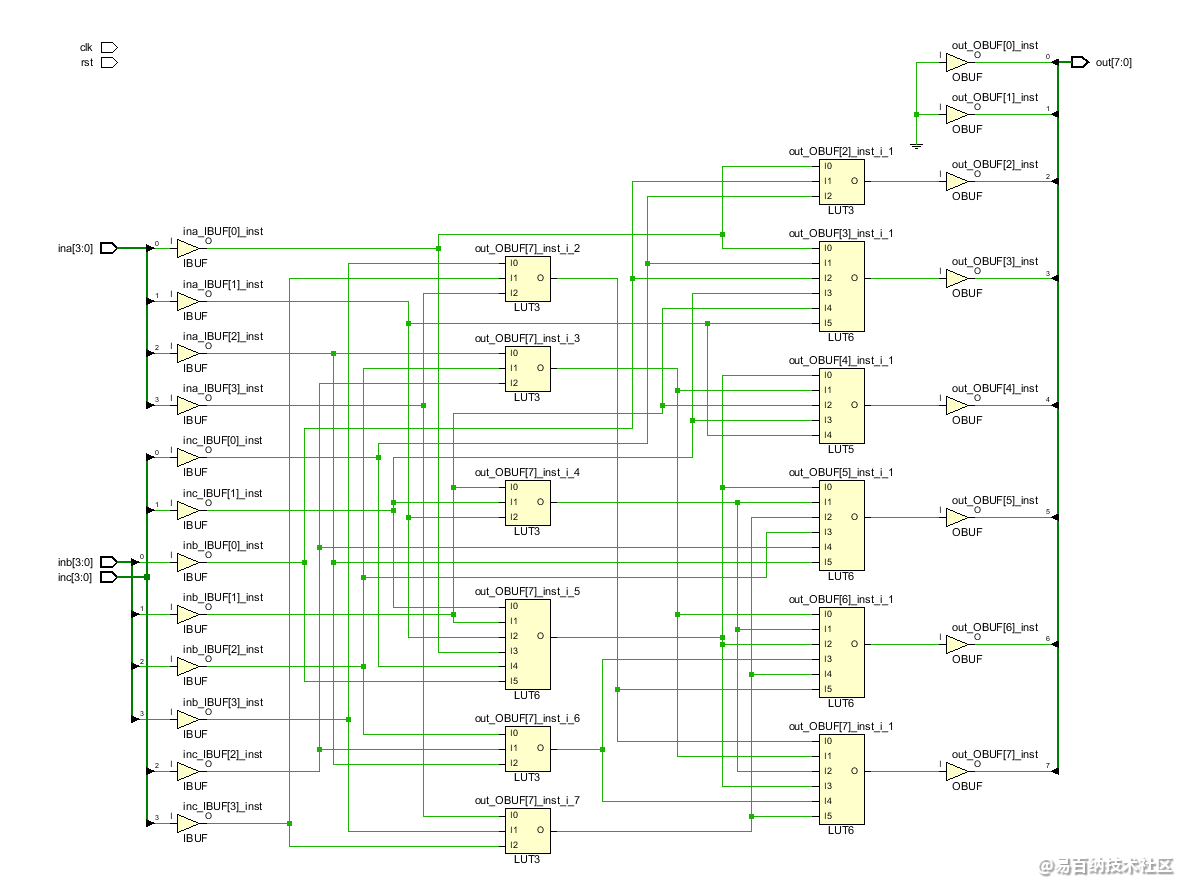
可见,不使用流水线的设计都别无二致,使用了大量的组合逻辑,在FPGA中就体现在LUT中。
有一个细节是,组合逻辑的移位也是通过LUT实现的,因为没有用到时钟。
讨论至此,这么个简单的设计也没有仿真,也不想做了。给出上述RTL设计的完整逻辑:
`timescale 1ns / 1ps
//////////////////////////////////////////////////////////////////////////////////
// Company:
// Engineer: 李锐博恩
//
// Create Date: 2021/04/10 23:03:02
// Design Name:
// Module Name: pipelined_multiplier
//////////////////////////////////////////////////////////////////////////////////
module pipelined_multiplier #(
parameter WIDTH = 4,
MODE = 2'b10
)(
input wire clk,
input wire rst,
input wire [WIDTH - 1 : 0] ina,
input wire [WIDTH - 1 : 0] inb,
input wire [WIDTH - 1 : 0] inc,
output wire [WIDTH + 3 : 0] out
);
reg [WIDTH : 0] a_plus_b;
reg [WIDTH - 1 : 0] c_d1;
reg [WIDTH + 1 : 0] a_plus_b_plus_c;
reg [WIDTH + 3 : 0] out_mid;
generate
if(MODE == 2'b00) begin
//most bad design
assign out = (ina + inb + inc)*4;
end
else if(MODE == 2'b01) begin
//bad design
assign out = (ina + inb + inc) << 2;
end
else begin //pipelining
//recommand
always@(posedge clk or posedge rst) begin
if(rst) begin
a_plus_b <= 'd0;
c_d1 <= 'd0;
end
else begin
a_plus_b <= ina + inb;
c_d1 <= inc;
end
end
always@(posedge clk or posedge rst) begin
if(rst) begin
a_plus_b_plus_c <= 'd0;
out_mid <= 'd0;
end
else begin
a_plus_b_plus_c <= a_plus_b + c_d1;
out_mid <= a_plus_b_plus_c << 2;
end
end
end
endgenerate
assign out = out_mid;
endmodule
逻辑中使用了generate if的语法来判断使用哪种设计方式,关于generate if见博文:
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:10020次2021-04-11 14:45:45
-
浏览量:4850次2021-06-08 22:36:45
-
浏览量:252次2023-09-20 19:02:57
-
浏览量:7079次2021-02-07 00:59:28
-
浏览量:4623次2020-11-04 09:47:48
-
浏览量:14058次2020-12-02 16:57:03
-
浏览量:1289次2020-07-02 16:11:35
-
浏览量:13539次2020-12-06 17:48:56
-
浏览量:1506次2022-01-14 09:00:21
-
浏览量:1596次2019-07-04 12:02:50
-
2024-01-11 15:44:19
-
浏览量:1928次2018-02-11 19:52:32
-
浏览量:20543次2020-12-10 16:21:29
-
浏览量:1948次2020-06-15 11:56:32
-
浏览量:1712次2020-06-18 09:34:12
-
2020-07-01 11:02:45
-
浏览量:4076次2021-06-20 20:10:03
-
浏览量:5194次2022-05-10 09:00:38
-
浏览量:3446次2020-11-09 15:54:12
李锐博恩
一个努力写作的FPGA爱好者、从业者,CSDN博客专家,CSDN上万关注量,百万

-
60篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
李锐博恩

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
