

AI 之 Dropout与学习率衰减
文章目录
【深度学习】Dropout与学习率衰减
1 概述
2 在Keras中使用Dropout
2.1 输入中使用(噪声)
2.2 Hidden层
3 LR衰减
3.1 线性衰减
3.2 指数衰减
3.3 备注1 概述
开篇明义,dropout是指在深度学习网络的训练过程中,对于神经网络单元,按照一定的概率将其暂时从网络中丢弃。注意是暂时,对于随机梯度下降来说,由于是随机丢弃,故而每一个mini-batch都在训练不同的网络。
之前了解的网络都是在全连接层加dropout层,防止模型过拟合。在看deepfm的模型的时候,发现在每一层都可以加入dropout层
对dropout层的深入理解
做分类的时候,Dropout 层一般加在全连接层 防止过拟合 提升模型泛化能力。而很少见到卷积层后接Drop out (原因主要是 卷积参数少,不易过拟合)
dropout可以让模型训练时,随机让网络的某些节点不工作(输出置零),也不更新权重(但会保存下来,下次训练得要用,只是本次训练不参与bp传播),其他过程不变。我们通常设定一个dropout radio=p,即每个输出节点以概率p置0(不工作,权重不更新),假设每个输出都是独立的,每个输出都服从二项伯努利分布p(1-p),则大约认为训练时,只使用了(1-p)比例的输出,相当于每次训练一个子网络。测试的时候,可以直接去掉Dropout层,将所有输出都使用起来,为此需要将尺度对齐,即比例缩小输出 r=r*(1-p)。
训练的时候需要dropout,测试的时候直接去掉。
如果测试时的时候添加了dropout层,测试的时候直接把前一层的特征结果传到下一层:
dropout层相当于组合了N个网络,测试的时候去掉dropout,相当于N个网络的组合;


2 在Keras中使用Dropout
2.1 输入中使用(噪声)
每个批次随机随机剔除0.20倍数据。
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dropout
from keras.layers import Dense
from keras.optimizers import SGD
from keras.wrappers.scikit_learn import KerasClassifier
from sklearn.model_selection import cross_val_score
from sklearn.model_selection import KFold
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dropout(rate=0.2, input_shape=(4,)))#!!!!!!!!!!!!
model.add(Dense(units=4, activation='relu', kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 定义Dropout
sgd = SGD(lr=0.01, momentum=0.8, decay=0.0, nesterov=False)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
model = KerasClassifier(build_fn=create_model, epochs=200, batch_size=5, verbose=0)
kfold = KFold(n_splits=10, shuffle=True, random_state=seed)
results = cross_val_score(model, x, Y, cv=kfold)
print('Accuracy: %.2f%% (%.2f)' % (results.mean()*100, results.std()))2.2 Hidden层

# 构建模型函数
def create_model(init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init, kernel_constraint=maxnorm(3)))
model.add(Dropout(rate=0.2))
model.add(Dense(units=6, activation='relu', kernel_initializer=init, kernel_constraint=maxnorm(3)))
model.add(Dropout(rate=0.2))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
# 定义Dropout
sgd = SGD(lr=0.01, momentum=0.8, decay=0.0, nesterov=False)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model3 LR衰减
为什么要调整我们的学习率并使用学习率方案
要了解为什么学习率方案是一个有价值的方法,可用于提高模型的准确率并降低loss,考虑到几乎所有神经网络使用的标准权重更新公式:

回想一下,学习率 alpha,控制着我们梯度改变的步长(step)。更大的alpha值意味着更大的步长。如果alpha为0,则网络无法执行任何步骤(因为梯度乘以0为0).
你遇到的大多数初始学习率都是下面的集合中:
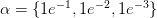
然后,在不改变学习率的条件下,网络训练固定数量的epoch。
这种方法在某些情况下可能效果很好,但是随着时间的推移降低学习率往往是有益的。在训练网络时,我们试图在损失曲面(loss landscape)中找到一些位置(location),网络可以获得合理的准确率。它不一定是全局最小值,甚至不是局部最小值,但在实践中,仅仅找到一个具有相当小的loss landscape区域就是“足够好”。
如果我们不断保持高学习率,我们可能会overshoot这些低loss的区域,因此我们将采取一系列步骤进入低loss的区域。
相反,我们可以做的是降低我们的学习率,从而允许我们的网络采取更小的步长——这种降低的学习率使我们的网络能够下降到“更优化”的loss landscape区域,否则用我们的学习率将完全错过。
因此,我们可以将学习率调整的过程视为:
在训练过程的早期以较高的学习率找到一组合理的“好的”权重。
在后续过程中调整这些权重,以使用较小的学习率找到更优的权重。
3.1 线性衰减


from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from keras.optimizers import SGD
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 设定随机种子
seed = 7
np.random.seed(seed)
# 构建模型函数
def create_model(init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
#模型优化
learningRate = 0.1
momentum = 0.9
decay_rate = 0.005
sgd = SGD(lr=learningRate, momentum=momentum, decay=decay_rate, nesterov=False)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
epochs = 200
model = KerasClassifier(build_fn=create_model, epochs=epochs, batch_size=5, verbose=1)
model.fit(x, Y)3.2 指数衰减
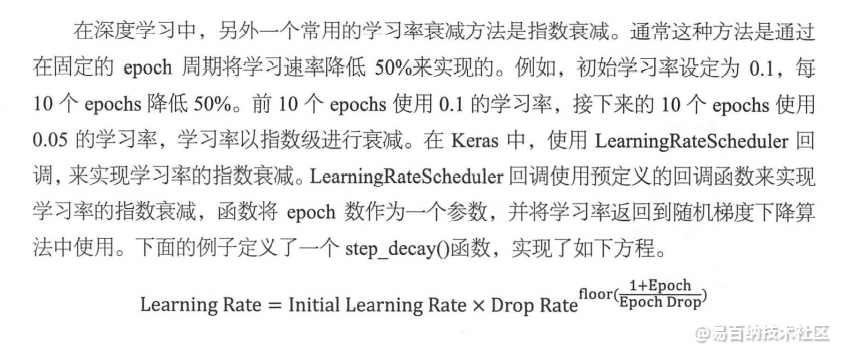
from sklearn import datasets
import numpy as np
from keras.models import Sequential
from keras.layers import Dense
from keras.wrappers.scikit_learn import KerasClassifier
from keras.optimizers import SGD
from keras.callbacks import LearningRateScheduler
from math import pow, floor
# 导入数据
dataset = datasets.load_iris()
x = dataset.data
Y = dataset.target
# 设定随机种子
seed = 7
np.random.seed(seed)
# 计算学习率
def step_decay(epoch):
init_lrate = 0.1
drop = 0.5
epochs_drop = 10
lrate = init_lrate * pow(drop, floor(1 + epoch) / epochs_drop)
return lrate
# 构建模型函数
def create_model(init='glorot_uniform'):
# 构建模型
model = Sequential()
model.add(Dense(units=4, activation='relu', input_dim=4, kernel_initializer=init))
model.add(Dense(units=6, activation='relu', kernel_initializer=init))
model.add(Dense(units=3, activation='softmax', kernel_initializer=init))
#模型优化
learningRate = 0.1
momentum = 0.9
decay_rate = 0.0
sgd = SGD(lr=learningRate, momentum=momentum, decay=decay_rate, nesterov=False)
# 编译模型
model.compile(loss='categorical_crossentropy', optimizer=sgd, metrics=['accuracy'])
return model
lrate = LearningRateScheduler(step_decay)
epochs = 200
model = KerasClassifier(build_fn=create_model, epochs=epochs, batch_size=5, verbose=1, callbacks=[lrate])
model.fit(x, Y)3.3 备注
你应该设置一个大的学习率,这样在网络开始学习时回取得更快的速度,然后不断衰减。
使用一个大的动量,这样当学习率足够小的时候,能继续努力向正确的方向更新网络权重。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5454次2021-05-06 12:40:04
-
浏览量:271次2023-09-08 11:16:44
-
浏览量:7169次2021-08-10 10:06:51
-
浏览量:2244次2018-01-27 13:19:46
-
浏览量:1797次2018-04-25 15:15:09
-
浏览量:7047次2021-06-03 11:03:40
-
浏览量:1853次2018-08-18 10:38:38
-
浏览量:3626次2018-04-16 16:18:53
-
浏览量:7840次2021-04-26 17:26:00
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:1088次2020-08-25 11:56:50
-
浏览量:567次2023-12-25 14:11:19
-
浏览量:5296次2021-02-20 17:09:58
-
浏览量:2200次2020-04-28 16:17:08
-
浏览量:1190次2018-07-18 10:22:58
-
浏览量:2153次2020-04-28 11:25:57
-
浏览量:5492次2021-07-09 11:16:51
-
浏览量:4692次2021-06-07 09:28:15
-
浏览量:6181次2021-05-24 15:13:24

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺



-
241篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
