

【深度学习】如何从结构出发更好的改进一个神经网络(二)
【深度学习】如何从结构出发更好的改进一个神经网络(二)
文章目录
1 空洞卷积(dilated convolution)
2 PReLU
3 LeakyReLU可以解决神经元”死亡“问题
4 ResNet34
5 深度学习网络中backbone
6 实验
6.1 test_binary_crossentropy_bn_LeakyReLU_lr=0.01, decay=2e-5
6.2 test_binary_crossentropy_bn_PReLU_lr=0.01, decay=2e-5
6.3 test_binary_crossentropy_bn_LeakyReLU_lr=0.01, decay=2e-5
7 总结DropOut1 空洞卷积(dilated convolution)
Dilated/Atrous Convolution(中文叫做空洞卷积或者膨胀卷积) 或者是 Convolution with holes 从字面上就很好理解,是在标准的 convolution map 里注入空洞,以此来增加 reception field。相比原来的正常convolution,dilated convolution 多了一个 hyper-parameter 称之为 dilation rate 指的是kernel的间隔数量
空洞卷积存在的问题
潜在问题 1:The Gridding Effect
假设我们仅仅多次叠加 dilation rate 2 的 3 x 3 kernel 的话,则会出现这个问题:
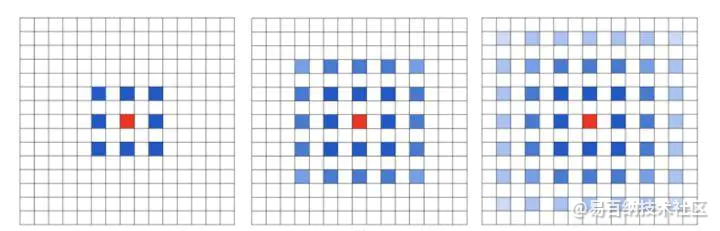
我们发现我们的 kernel 并不连续,也就是并不是所有的 pixel 都用来计算了,因此这里将信息看做 checker-board 的方式会损失信息的连续性。这对 pixel-level dense prediction 的任务来说是致命的。
潜在问题 2:Long-ranged information might be not relevant.
我们从 dilated convolution 的设计背景来看就能推测出这样的设计是用来获取 long-ranged information。然而光采用大 dilation rate 的信息或许只对一些大物体分割有效果,而对小物体来说可能则有弊无利了。如何同时处理不同大小的物体的关系,则是设计好 dilated convolution 网络的关键。
2 PReLU
提出 Parametric Rectified Linear Unit,即 PReLU,其对 ReLU 进行了改进推广。在几乎不增加计算量的前提下,有效的改善了模型的过拟合问题。收敛更快,误差更低。
提出一种更加稳健的初始化方式,其充分考虑到了整流单元的非线性。这种方法使得我们可以直接从零开始训练更深的网络
成就:基于 PReLU 的网络(PReLU-nets),在 ImageNet-2012 分类数据集上取得了 4.94% 的 top-5 误差。首次在计算机视觉识别任务上,超越人类水平!
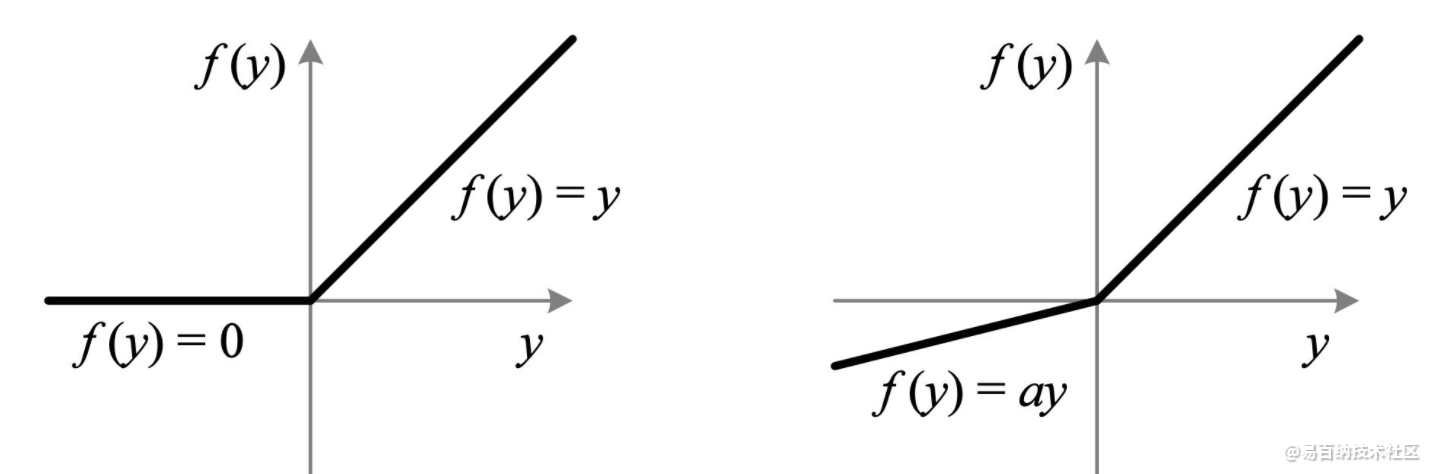
对比实验
我们使用一个 14 层的网络进行试验,网络结构参数如下表所示:
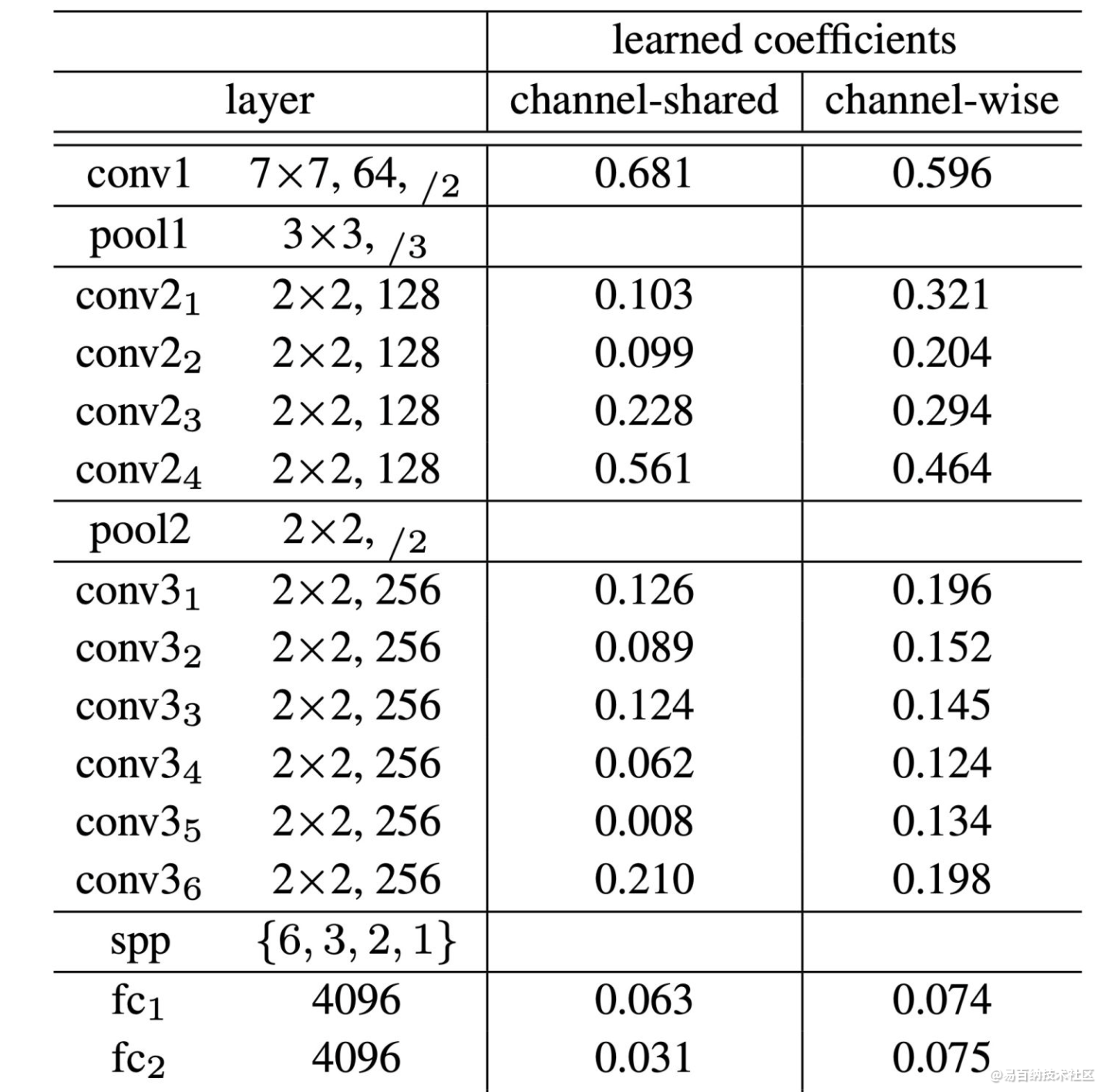
如上表所示,有两个有意思的地方:
第一层卷积层对应的 PReLU 学习后的参数远大于 0,但之后都接近于 0.1。由于第一层卷积层作为图像边缘特征提取器,这就表明,网络同时兼顾了正负响应,有效的提取了低层次信息
对于 channel-wise 的版本,网络的深层通常参数越小。这表明,网络更倾向于在早些层保存更多信息,而在更深层更加可辨别
3 LeakyReLU可以解决神经元”死亡“问题
实际中,LeakyReLU的α取值一般为0.01。使用LeakyReLU的好处就是:在反向传播过程中,对于LeakyReLU激活函数输入小于零的部分,也可以计算得到梯度(而不是像ReLU一样值为0),这样就避免了上述梯度方向锯齿问题。
超参数α的取值也已经被很多实验研究过,有一种取值方法是 对α随机取值,α的分布满足均值为0,标准差为1的正态分布,该方法叫做随机LeakyReLU(Randomized LeakyReLU)。原论文指出随机LeakyReLU相比LeakyReLU能得更好的结果,且给出了参数α的经验值1/5.5(好于0.01)。至于为什么随机LeakyReLU能取得更好的结果,解释之一就是随机LeakyReLU小于0部分的随机梯度,为优化方法引入了随机性,这些随机噪声可以帮助参数取值跳出局部最优和鞍点,这部分内容可能需要一整篇文章来阐述。正是由于α的取值至关重要,人们不满足与随机取样α,有论文将α作为了需要学习的参数,该激活函数为PReLU(Parametrized ReLU)。
4 ResNet34
计算过程:
输入image 224x224x3
经过 7x7,conv,c_out=64,stride=2,padding=3 得到feature map:112x112x64,经过BR维度不变。
经过k=3,s=2,padding=1的pool,得到feature map:56x56x64,得到残差层的输入A
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过BR维度不变
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过B维度不变,得到残差B
A + B 得到下一层输入A1
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过BR维度不变
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过B维度不变,得到残差B1
A1 + B1 得到下一层输入A2
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过BR维度不变
经过64x3x3x64,k=3,s=1,p=1的conv,得到 feature map:56x56x64,经过B维度不变,得到残差B2
A2 + B2 得到下一层输入A3
经过64x3x3x128,k=3,s=2,p=1的conv,得到 feature map:28x28x128,经过BR维度不变
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过B维度不变,得到残差B3
用64x1x1x128,s=2的conv将A3的维度变换为2828128
A3 + B3 得到下一层输入A4
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过BR维度不变
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过B维度不变,得到残差B4
A4 + B4 得到下一层输入A5
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过BR维度不变
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过B维度不变,得到残差B5
A5 + B5 得到下一层输入A6
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过BR维度不变
经过128x3x3x128,k=3,s=1,p=1的conv,得到 feature map:28x28x128,经过B维度不变,得到残差B6
A6 + B6 得到下一层输入A7
经过128x3x3x256,k=3,s=2,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B7
用128x1x1x256,s=2的conv将A7的维度变换为1414256
A7 + B7 得到下一层输入A8
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B8
A8 + B8 得到下一层输入A9
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B9
A9 + B9 得到下一层输入A10
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B10
A10 + B10 得到下一层输入A11
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B11
A11 + B11 得到下一层输入A11
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过BR维度不变
经过256x3x3x256,k=3,s=1,p=1的conv,得到 feature map:14x14x256,经过B维度不变,得到残差B11
A11 + B11 得到下一层输入A12
经过256x3x3x512,k=3,s=2,p=1的conv,得到 feature map:7x7x512,经过BR维度不变
经过512x3x3x512,k=3,s=1,p=1的conv,得到 feature map:7x7x512,经过B维度不变,得到残差B12
用256x1x1x512,s=2的conv将A12的维度变换为77512
A12 + B12 得到下一层输入A13
经过256x3x3x512,k=3,s=2,p=1的conv,得到 feature map:7x7x512,经过BR维度不变
经过512x3x3x512,k=3,s=1,p=1的conv,得到 feature map:7x7x512,经过B维度不变,得到残差B13
A13 + B13 得到下一层输入A14
经过256x3x3x512,k=3,s=2,p=1的conv,得到 feature map:7x7x512,经过BR维度不变
经过512x3x3x512,k=3,s=1,p=1的conv,得到 feature map:7x7x512,经过B维度不变,得到残差B14
A14 + B14 得到下一层输入A15
经过256x3x3x512,k=3,s=2,p=1的conv,得到 feature map:7x7x512,经过BR维度不变
经过512x3x3x512,k=3,s=1,p=1的conv,得到 feature map:7x7x512,经过B维度不变,得到残差B15
A15 + B15 得到下一层输入A16
经过一个globle avg_pool将A16处理成1x1x512
经过一个512x1000的fc得到1000维的输出。
5 深度学习网络中backbone
backbone这个单词原意指的是人的脊梁骨,后来引申为支柱,核心的意思。在神经网络中,尤其是CV领域,一般先对图像进行特征提取(常见的有vggnet,resnet,谷歌的inception),这一部分是整个CV任务的根基,因为后续的下游任务都是基于提取出来的图像特征去做文章(比如分类,生成等等)。所以将这一部分网络结构称为backbone十分形象,仿佛是一个人站起来的支柱。
主干网络,用来做特征提取的网络,代表网络的一部分,一般是用于前端提取图片信息,生成特征图feature map,供后面的网络使用。
6 实验
6.1 test_binary_crossentropy_bn_LeakyReLU_lr=0.01, decay=2e-5
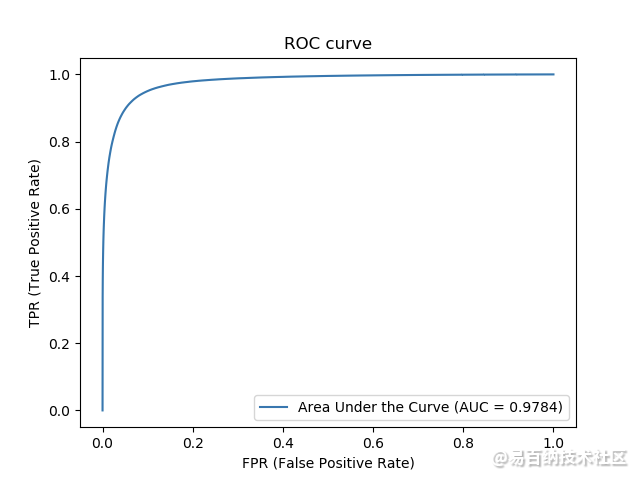
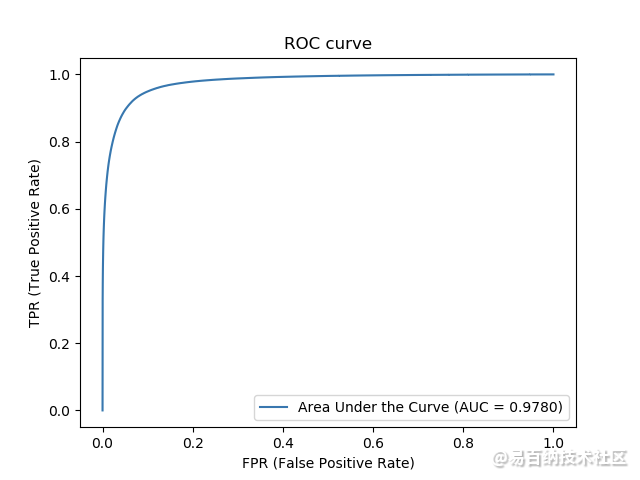
Area under the ROC curve: 0.9783655005634913
Area under Precision-Recall curve: 0.9081161109531458
Jaccard similarity score: 0.9556604981376744
F1 score (F-measure): 0.818853320153726
Confusion matrix:[[3882130 78364]
[ 122855 454794]]
ACCURACY: 0.9556604981376744
SENSITIVITY: 0.7873189428182166
SPECIFICITY: 0.9802135794171131
PRECISION: 0.8530191800554432
6.2 test_binary_crossentropy_bn_PReLU_lr=0.01, decay=2e-5
6.3 test_binary_crossentropy_bn_LeakyReLU_lr=0.01, decay=2e-5
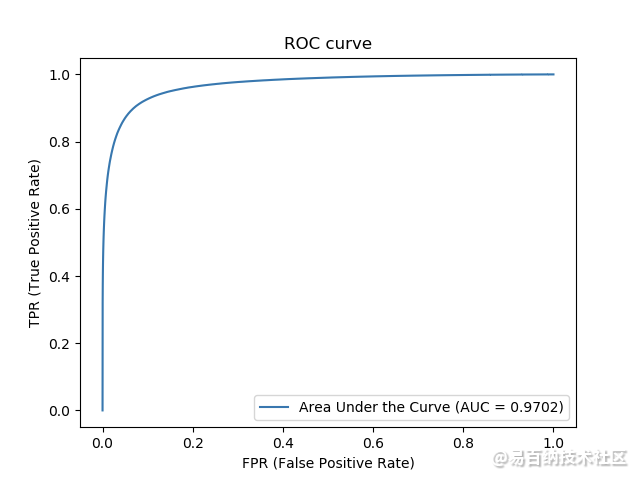
Area under the ROC curve: 0.9783655005634913
Area under Precision-Recall curve: 0.9081161109531458
Jaccard similarity score: 0.9556604981376744
F1 score (F-measure): 0.818853320153726
Confusion matrix:[[3882130 78364]
[ 122855 454794]]
ACCURACY: 0.9556604981376744
SENSITIVITY: 0.7873189428182166
SPECIFICITY: 0.9802135794171131
PRECISION: 0.8530191800554432
7 总结DropOut
文章的最后说一种防止过拟合的方法。
方法步骤为:
删除隐藏层的一些神经单元
在新的神经网络上正向,反向更新
恢复最初始的神经元,重新随机选择一半删除。正反更新
重复上面的过程
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:8072次2021-05-13 12:53:50
-
浏览量:4103次2021-04-23 14:09:15
-
浏览量:4157次2021-04-20 15:50:27
-
浏览量:3588次2018-02-14 10:30:11
-
浏览量:5021次2021-05-28 16:59:25
-
浏览量:5892次2021-07-14 09:51:09
-
浏览量:4971次2021-08-13 15:39:02
-
浏览量:7754次2021-05-28 16:59:43
-
浏览量:4605次2021-04-23 14:09:37
-
浏览量:6208次2021-05-31 17:02:05
-
浏览量:10783次2021-05-04 20:20:07
-
浏览量:5632次2021-07-26 11:27:40
-
浏览量:170次2023-08-28 09:56:42
-
浏览量:6368次2021-07-26 11:30:25
-
浏览量:94次2024-02-01 14:20:47
-
浏览量:3821次2021-04-19 14:54:23
-
浏览量:9163次2021-06-15 10:30:15
-
浏览量:13920次2021-06-07 17:47:54
-
浏览量:114次2024-02-01 14:28:23

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺



-
241篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
