

【深度学习】基于Torch的Python开源机器学习库PyTorch卷积神经网络
【深度学习】基于Torch的Python开源机器学习库PyTorch卷积神经网络

文章目录
1 CNN概述
2 PyTorch实现步骤
2.1 加载数据
2.2 CNN模型
2.3 训练
2.4 可视化训练
3 TorchVision
4 torch.nn 模块简介
5 保存
6 提取网络1 CNN概述

(6)输出层有10个神经元,在MNIST数据集的输出具有10个分类,因此采用softmax激活函数,输出每张图片在每个分类上的得分。
cov2d第一个参数可以理解为,卷积层提取特征,池化层提取更重要的特征。压缩是两个层都要进行的工作。
Feature Map(特征图)是输入图像经过神经网络卷积产生的结果,表征的是神经空间内一种特征;其分辨率大小取决于先前卷积核的步长 。
层与层之间会有若干个卷积核(kernel),上一层中的每个feature map跟每个卷积核做卷积,对应产生下一层的一个feature map。
feature map的含义在计算机视觉领域基本一致,可以简单译成特征图,例如RGB图像,所有像素点的R可以认为一个feature map(这个概念与在CNN里面概念是一致的)。
卷积核:二维的矩阵
滤波器:多个卷积核组成的三维矩阵,多出的一维是通道。
2 PyTorch实现步骤
2.1 加载数据
import torch
import torch.nn as nn
import torch.utils.data as Data
import torchvision # 数据库模块
import matplotlib.pyplot as plt
torch.manual_seed(1) # reproducible
# Hyper Parameters
EPOCH = 1 # 训练整批数据多少次, 为了节约时间, 我们只训练一次
BATCH_SIZE = 50
LR = 0.001 # 学习率
DOWNLOAD_MNIST = True # 如果你已经下载好了mnist数据就写上 False
# Mnist 手写数字
train_data = torchvision.datasets.MNIST(
root='./mnist/', # 保存或者提取位置
train=True, # this is training data
transform=torchvision.transforms.ToTensor(), # 转换 PIL.Image or numpy.ndarray 成
# torch.FloatTensor (C x H x W), 训练的时候 normalize 成 [0.0, 1.0] 区间
download=DOWNLOAD_MNIST, # 没下载就下载, 下载了就不用再下了
)test_data = torchvision.datasets.MNIST(root='./mnist/', train=False)
# 批训练 50samples, 1 channel, 28x28 (50, 1, 28, 28)
train_loader = Data.DataLoader(dataset=train_data, batch_size=BATCH_SIZE, shuffle=True)
# 为了节约时间, 我们测试时只测试前2000个
test_x = torch.unsqueeze(test_data.test_data, dim=1).type(torch.FloatTensor)[:2000]/255. # shape from (2000, 28, 28) to (2000, 1, 28, 28), value in range(0,1)
test_y = test_data.test_labels[:2000]2.2 CNN模型
和以前一样, 我们用一个 class 来建立 CNN 模型. 这个 CNN 整体流程是 卷积(Conv2d) -> 激励函数(ReLU) -> 池化, 向下采样 (MaxPooling) -> 再来一遍 -> 展平多维的卷积成的特征图 -> 接入全连接层 (Linear) -> 输出
class CNN(nn.Module):
def __init__(self):
super(CNN, self).__init__()
self.conv1 = nn.Sequential( # input shape (1, 28, 28)
nn.Conv2d(
in_channels=1, # input height
out_channels=16, # n_filters
kernel_size=5, # filter size
stride=1, # filter movement/step
padding=2, # 如果想要 con2d 出来的图片长宽没有变化, padding=(kernel_size-1)/2 当 stride=1
), # output shape (16, 28, 28)
nn.ReLU(), # activation
nn.MaxPool2d(kernel_size=2), # 在 2x2 空间里向下采样, output shape (16, 14, 14)
)
self.conv2 = nn.Sequential( # input shape (16, 14, 14)
nn.Conv2d(16, 32, 5, 1, 2), # output shape (32, 14, 14)
nn.ReLU(), # activation
nn.MaxPool2d(2), # output shape (32, 7, 7)
)
self.out = nn.Linear(32 * 7 * 7, 10) # fully connected layer, output 10 classes
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = x.view(x.size(0), -1) # 展平多维的卷积图成 (batch_size, 32 * 7 * 7)
output = self.out(x)
return output
cnn = CNN()
print(cnn) # net architecture
"""
CNN (
(conv1): Sequential (
(0): Conv2d(1, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU ()
(2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
)
(conv2): Sequential (
(0): Conv2d(16, 32, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(1): ReLU ()
(2): MaxPool2d (size=(2, 2), stride=(2, 2), dilation=(1, 1))
)
(out): Linear (1568 -> 10)
)
"""2.3 训练
optimizer = torch.optim.Adam(cnn.parameters(), lr=LR) # optimize all cnn parameters
loss_func = nn.CrossEntropyLoss() # the target label is not one-hotted
# training and testing
for epoch in range(EPOCH):
for step, (b_x, b_y) in enumerate(train_loader): # 分配 batch data, normalize x when iterate train_loader
output = cnn(b_x) # cnn output
loss = loss_func(output, b_y) # cross entropy loss
optimizer.zero_grad() # clear gradients for this training step
loss.backward() # backpropagation, compute gradients
optimizer.step() # apply gradients
"""
...
Epoch: 0 | train loss: 0.0306 | test accuracy: 0.97
Epoch: 0 | train loss: 0.0147 | test accuracy: 0.98
Epoch: 0 | train loss: 0.0427 | test accuracy: 0.98
Epoch: 0 | train loss: 0.0078 | test accuracy: 0.98
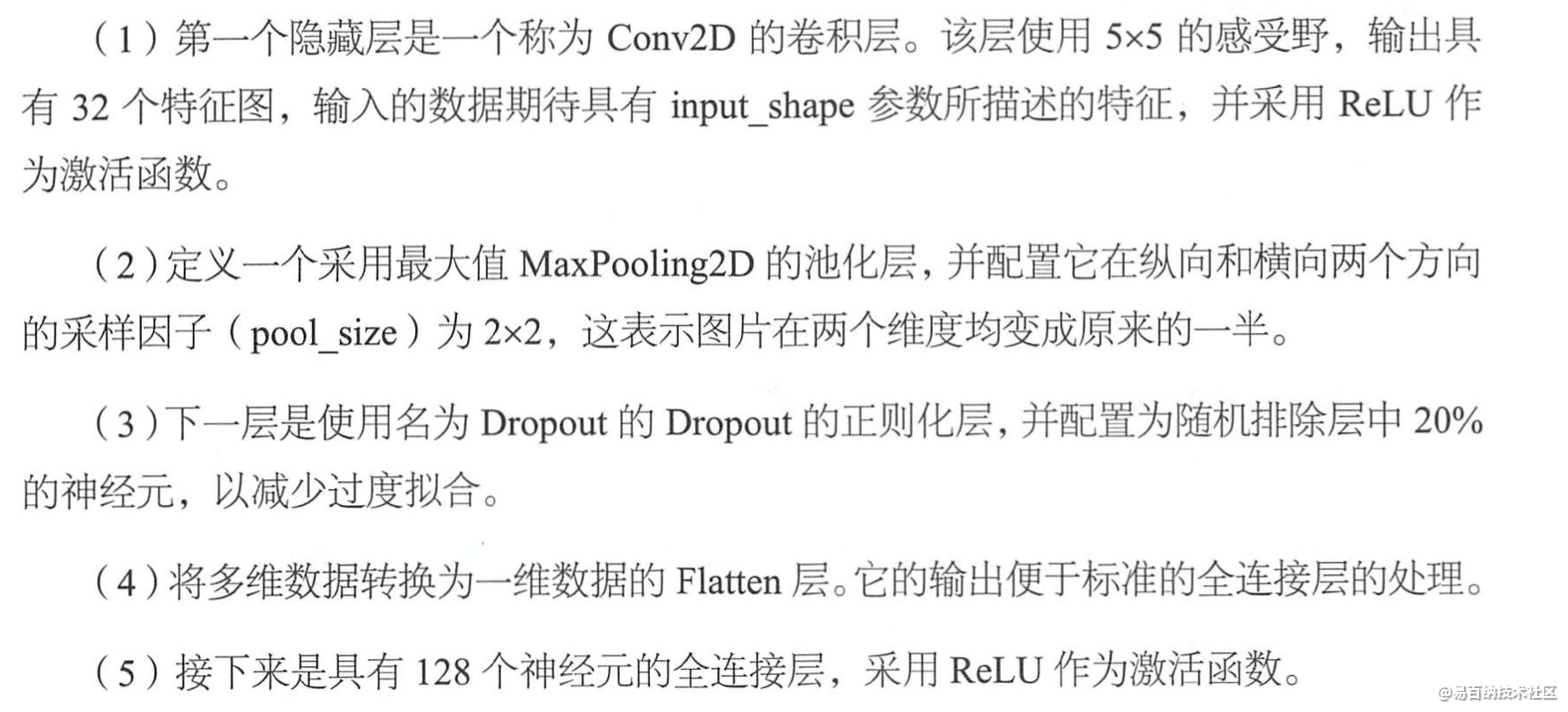
"""2.4 可视化训练
3 TorchVision
说明
很多基于Pytorch的工具集都非常好用,比如处理自然语言的torchtext,处理音频的torchaudio,以及处理图像视频的torchvision。
torchvision包含一些常用的数据集、模型、转换函数等等。当前版本0.5.0包括图片分类、语义切分、目标识别、实例分割、关键点检测、视频分类等工具,它将mask-rcnn功能也都包含在内了。mask-rcnn的Pytorch版本最高支持torchvision 0.2.*,0.3.0之后mask-rcnn就包含到tensorvision之中了。
Fine-tune目标检测模型
之前笔者尝试使用Mask-RCNN官方的TensorFlow和Pytorch版本实现目标识别和图片分割的Fine-tune。与之相比,TorchVision更加简单。
无论使用何种工具,Fine-tune都以调库为主,比较复杂容易出错的是构造数据文件,在尝试过程中,要么需要下载大量的数据,比如COCO数据集,要么需要标注和调试自己的数据,在外围工作上花费大量时间。
“行人检测”是“PyTorch官方教程中文版”中的fine-tune实例,全部代码100多行,数据也只有100多张图片,从例程中可以看到,自己做数据类,比下载COCO数据训练更加方便。如果使用GPU,如1080ti,十次迭代在十分钟以内即可完成。具体请见:
4 torch.nn 模块简介
nn.functional
import torch.nn.functional as F
包含 torch.nn 库中所有函数
同时包含大量 loss 和 activation function
import torch.nn.functional as F
loss_func = F.cross_entropy
loss = loss_func(model(x), y)
loss.backward()
nn.Module & nn.Parameter
继承 nn.Module,构造一个保存 weights,bias 和具有前向传播方法(forward step)的类
nn.Module 有大量属性和方法(eg. .parameters() 和 .zero_grad())
nn.Linear
torch.optim
torch.optim 有各种优化算法,可以使用优化器的 step 来进行前向传播,而不用人工的更新所有参数
opt.step()
opt.zero_grad()
optim.zero_grad() 将所有的梯度置为 0,需要在下个批次计算梯度之前调用
DataLoader
TensorDataset 是 Dataset 的 tensor 包装
from torch.utils.data import TensorDataset
train_ds = TensorDataset(x_train, y_train)
DataLoader 用于管理 batches,便于迭代
from torch.utils.data import DataLoader
train_dl = DataLoader(train_ds, batch_size=32)
迭代训练
model, opt = get_model()
for epoch in range(epochs):
for xb, yb in train_dl:
pred = model(xb)
loss = loss_func(pred, yb)
loss.backward()
opt.step()
opt.zero_grad()print(loss_func(model(xb), yb))
Add Validation
在训练过程中计算并打印每个 epoch 的 validation loss
5 保存
torch.save(net1, 'net.pkl') # 保存整个网络
torch.save(net1.state_dict(), 'net_params.pkl') # 只保存网络中的参数 (速度快, 占内存少)6 提取网络
def restore_net():
# restore entire net1 to net2
net2 = torch.load('net.pkl')
prediction = net2(x)def restore_params():
# 新建 net3
net3 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
# 将保存的参数复制到 net3
net3.load_state_dict(torch.load('net_params.pkl'))
prediction = net3(x)
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:4757次2021-07-26 11:25:51
-
浏览量:5136次2021-07-26 17:43:04
-
浏览量:113次2024-02-01 14:28:23
-
浏览量:3587次2018-02-14 10:30:11
-
浏览量:4971次2021-08-13 15:39:02
-
浏览量:6208次2021-05-31 17:02:05
-
浏览量:435次2023-07-05 10:11:45
-
浏览量:93次2024-02-01 14:20:47
-
浏览量:324次2023-09-06 11:12:55
-
浏览量:3820次2021-04-19 14:54:23
-
浏览量:121次2024-02-06 11:56:53
-
浏览量:132次2024-02-06 11:41:16
-
浏览量:5021次2021-05-28 16:59:25
-
浏览量:7753次2021-05-28 16:59:43
-
浏览量:4605次2021-04-23 14:09:37
-
2023-09-27 15:48:35
-
浏览量:129次2023-09-28 11:44:09
-
浏览量:8980次2020-11-08 17:15:55
-
浏览量:4156次2021-04-20 15:50:27

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺



-
241篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
