

Neon Intrinsics:Android入门
在本文中,我们将介绍如何为本地C++开发设置AndroidStudio,以及如何在ARM驱动的移动设备上使用Neon Intrinsics。
我将展示如何设置Android开发环境来使用Neon Intrinsics。然后,我们将实现一个Android应用程序,它使用Android Native DevelopmentKit(NDK)计算两个向量的点积。最后,我们将看到如何提高这样一个功能的性能。
作为Android开发人员,您可能没有时间编写汇编语言。相反,您的重点是应用程序可用性、可移植性、设计、数据访问以及将应用程序调到各种设备上。如果是这样的话,Neon Intrinsics将是一个很大的性能帮助。
ARM Neon Intrinsics技术是高级的单指令多数据(SIMD)处理器的体系结构扩展。SIMD的思想是在单个CPU周期内对数据序列或向量执行相同的操作。
例如,如果您是从两个一维数组中求和数字,则需要一个一个地添加它们。在非SIMD CPU中,每个数组元素从内存加载到CPU寄存器,然后添加寄存器值并将结果存储在内存中。对所有元素都重复此过程。为了加速这些操作,支持SIMD的CPU一次加载多个元素,执行操作,然后将结果存储到内存中。根据序列长度,性能将提高N。从理论上讲,计算时间将减少N。
通过使用SIMD结构,Neon Intrinsics可以加速多媒体和信号处理应用的性能,包括视频和音频编码和解码、3D图形以及语音和图像处理。Neon Intrinsics提供的控制几乎与编写汇编代码一样多,但它们将寄存器的分配留给编译器,以便开发人员能够专注于算法。因此,Neon Intrinsics在提高性能和编写汇编语言之间取得了平衡。
首先,我将向您展示如何设置您的Android开发环境以使用Neon Intrinsics。然后,我们将实现一个Android应用程序,它使用AndroidNativeDevelopmentKit(NDK)计算两个向量的点积。最后,我们将看到如何提高这样一个功能的性能。
我创建了这个示例项目Android Studio。示例代码可从GitHub存储库获得。NeonIntrinsics-Android。我用三星SM-J710F手机测试了代码。
原生C++Android项目模板
首先,我使用本机C++项目模板创建了一个新项目。
然后,我将应用程序名设置为Neon Intrinsics,选择Java作为语言,并将最小SDK设置为API 19:Android4.4(KitKat)。
然后,我选择了C++标准的工具链默认值。
我创建的项目包含一个在MainActivity类,派生自AppCompatActivity(见App/java/com.example.neonintrinsics/MainActivity.java)。关联视图仅包含TextView控件,该控件显示“Hello from C++”字符串。
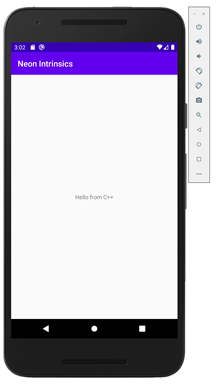
要获得这些结果,您可以使用其中一个模拟器直接从AndroidStudio运行该项目。要成功构建该项目,您需要安装CMake和AndroidNDK。您可以通过设置(FilesSettings)来做到这一点。然后,在SDK Tools选项卡上选择NDK和CMake。
如果您打开MainActivity.java文件中,您将注意到应用程序中来自native-lib的字符串。代码在APP/CPP/本机-lib.cpp文件夹。这就是我们将用于实现的文件夹。
支持Neon Intrinsics
要启用对Neon Intrinsics的支持,您需要修改ABI滤波器,因此,这个应用程序可以为ARM架构构建。Neon Intrinsics有两个版本:一个用于ARMv 7,ARMv8AArch32,另一个用于ARMv8AArch64。从本质的角度看,存在一些差异,如ARMv8-A中增加了2xFloat 64的向量。它们都可以在arm_neon.h找到头文件。你还需要导入Neon Intrinsics库。
转到Gradle脚本,并打开build.gradle(模块:APP)文件。然后,补充defaultConfig节中添加以下语句。首先,将这一行添加到常规设置中:
ndk.abiFilters 'x86', 'armeabi-v7a', 'arm64-v8a'这里,我添加了对x86、32位和64位ARM架构的支持。然后在cmake选项下面添加这一行:
arguments "-DANDROID_ARM_NEON=ON"它应该是这样的:
defaultConfig {
applicationId "com.example.myapplication"
minSdkVersion 16
targetSdkVersion 29
versionCode 1
versionName "1.0"
ndk.abiFilters 'x86', 'armeabi-v7a', 'arm64-v8a'
testInstrumentationRunner "androidx.test.runner.AndroidJUnitRunner"
externalNativeBuild {
cmake {
cppFlags ""
arguments "-DANDROID_ARM_NEON=ON"
}
}
}现在您可以使用Neon Intrinsics,它在arm_neon.h。请注意,构建将只成功的ARM-v7和更高版本。
点乘积和辅助方法
我们现在可以用C++实现两个向量的点积。所有的代码都应该放在native-Lib.cpp文件。注意,从armv8.4a开始,DotProduct是新指令集的一部分。这对应于一些皮质A75设计和所有的皮质A76设计继续。
我们从生成ramp的helper方法开始,从startValue:
short* generateRamp(short startValue, short len) {
short* ramp = new short[len];
for(short i = 0; i < len; i++) {
ramp[i] = startValue + i;
}
return ramp;
}接下来,我们实现msElapsedTime方法,稍后将用于确定执行时间:
double msElapsedTime(chrono::system_clock::time_point start) {
auto end = chrono::system_clock::now();
return chrono::duration_cast<chrono::milliseconds>(end - start).count();
}
chrono::system_clock::time_point now() {
return chrono::system_clock::now();
}这个msElapsedTime方法计算从给定起点传递的持续时间(以毫秒表示)。
方法是一个方便的包装器。std::chrono::system_clock::now方法,该方法返回当前时间。
现在创建实际的dotProduct方法。正如您从编程类中所记得的,要计算两个等长向量的点积,您可以逐元素地乘向量元素,然后累加得到的积。该算法的简单实现如下:
int dotProduct(short* vector1, short* vector2, short len) {
int result = 0;
for(short i = 0; i < len; i++) {
result += vector1[i] * vector2[i];
}
return result;
}上面的实现使用for循环。因此,我们依次乘向量元素,然后将得到的乘积累加到一个名为结果的局部变量中。
用Neon Intrinsics计算点积
若要修改dotProduct函数以受益于Neon Intrinsics,您需要拆分for循环,以便它能够利用数据通道。为此,对循环进行分区或矢量化,以便在单个CPU周期内对数据序列进行操作。这些序列被定义为矢量。但是,为了区别于作为点积输入的向量,我将这些序列称为寄存器向量.
对于寄存器向量,可以减少循环迭代,这样,在每次迭代时,就可以乘多个向量元素,然后累加多个向量元素来计算点积。可以使用的元素数量取决于寄存器布局。
ARM Neon架构使用64位或128位寄存器文件。在64位的情况下,您可以使用8个8位、4个16位或两个32位的元素。在128位情况下,您可以使用16位8位、8位16位、4位32位或两个64位元素。
为了表示各种寄存器向量,Neon Intrinsics使用以下名称约定:
<type><size>x<number of lanes>_t<type>是数据类型(int、uint、Float或poly)。<size>用于数据类型(8、16、32、64)的位数。<number of lanes>确定了多少车道。
例如,int16x4_t表示具有4条16位整数元素的向量寄存器,它等价于一个4元素int 16一维数组(short[4]).
你不能直接实例化Neon Intrinsics内部类型。相反,您可以使用专用方法将数据从数组加载到CPU寄存器。这些方法的名称以vld。注意,方法命名使用类似于类型命名的约定。所有方法后面跟着一个方法短名(如ld对于LOAD),以及字母和多个位的组合(例如,s16)指定输入数据类型。
Neon Intrinsics本质与组装指令直接对应:
int dotProductNeon(short* vector1, short* vector2, short len) {
const short transferSize = 4;
short segments = len / transferSize;
// 4-element vector of zeros
int32x4_t partialSumsNeon = vdupq_n_s32(0);
// Main loop (note that loop index goes through segments)
for(short i = 0; i < segments; i++) {
// Load vector elements to registers
short offset = i * transferSize;
int16x4_t vector1Neon = vld1_s16(vector1 + offset);
int16x4_t vector2Neon = vld1_s16(vector2 + offset);
// Multiply and accumulate: partialSumsNeon += vector1Neon * vector2Neon
partialSumsNeon = vmlal_s16(partialSumsNeon, vector1Neon, vector2Neon);
}
// Store partial sums
int partialSums[transferSize];
vst1q_s32(partialSums, partialSumsNeon);
// Sum up partial sums
int result = 0;
for(short i = 0; i < transferSize; i++) {
result += partialSums[i];
}
return result;
}在这里,为了从内存中加载数据,我使用vld1_s16方法。此方法从短路数组中加载四个元素(带符号的16位整数或s16(简称)到CPU寄存器。
一旦元素在cpu寄存器中,我将使用vmlal(乘积和积累)方法。此方法从两个数组中添加元素,并将结果累加到第三个数组中。
在这里,这个数组存储在partialSumsNeon变量。要初始化这个变量,我使用了vdupq_n_s32方法,它将所有CPU寄存器设置为特定值。在本例中,值为0。这是矢量法写的等价物int sum = 0.
一旦所有循环迭代完成,您需要将结果和存储回内存。您可以逐个元素读取结果元素。using vget_lane方法,或者使用vst方法。我使用第二种选择。
一旦部分和返回到内存中,我就对它们进行求和,以得到最终结果。
请注意,在AArch64上,您还可以使用:
return vaddv_s32 (partialSumsNeon);然后跳过第二个for循环。
把东西放在一起
我们现在可以把所有的代码放在一起了。为此,我们将修改MainActivity.stringFromJNI方法。
extern "C" JNIEXPORT jstring JNICALL
MainActivity.stringFromJNI (
JNIEnv* env,
jobject /* this */) {
// Ramp length and number of trials
const int rampLength = 1024;
const int trials = 10000;
// Generate two input vectors
// (0, 1, ..., rampLength - 1)
// (100, 101, ..., 100 + rampLength-1)
auto ramp1 = generateRamp(0, rampLength);
auto ramp2 = generateRamp(100, rampLength);
// Without NEON intrinsics
// Invoke dotProduct and measure performance
int lastResult = 0;
auto start = now();
for(int i = 0; i < trials; i++) {
lastResult = dotProduct(ramp1, ramp2, rampLength);
}
auto elapsedTime = msElapsedTime(start);
// With NEON intrinsics
// Invoke dotProductNeon and measure performance
int lastResultNeon = 0;
start = now();
for(int i = 0; i < trials; i++) {
lastResultNeon = dotProductNeon(ramp1, ramp2, rampLength);
}
auto elapsedTimeNeon = msElapsedTime(start);
// Clean up
delete ramp1, ramp2;
// Display results
std::string resultsString =
"----==== NO NEON ====----\nResult: " + to_string(lastResult)
+ "\nElapsed time: " + to_string((int)elapsedTime) + " ms"
+ "\n\n----==== NEON ====----\n"
+ "Result: " + to_string(lastResultNeon)
+ "\nElapsed time: " + to_string((int)elapsedTimeNeon) + " ms";
return env->NewStringUTF(resultsString.c_str());
}这个MainActivity.stringFromJNI方法如下所示。
首先,我们使用generateRamp方法。
接下来,我们用非Neon方法计算了这些矢量的点积。dotProduct。我们重复这个计算多次(试验常数),并使用msElasedTime.
然后,我们执行相同的操作,但现在使用的是启用Neon的方法。dotProductNeon.
最后,我们结合这两种方法的结果以及在resultsString。后者将显示在TextView。请注意,要成功构建和运行上述代码,您需要一个ARM-v7-A/ARMv8-A设备。
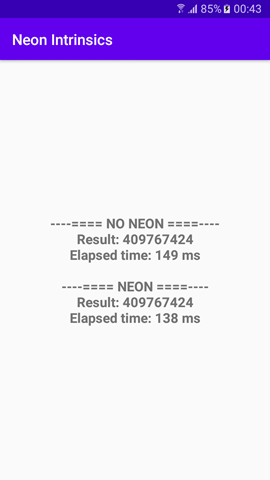
这是一个7%的改善,简单地使用内置的本质。在ARM 64设备上,理论上的改进可以达到25%。
总结
在本文中,我们了解了如何为本地C++开发设置AndroidStudio,以及如何在ARM驱动的移动设备上使用Neon Intrinsics。
在解释了Neon Intrinsics的概念之后,我们演示了两个等长向量的点积的一个示例实现。然后我们用专用的Neon Intrinsics本质将方法矢量化。通过这样做,我们介绍了您在使用Neon Intrinsics组件时所采取的重要步骤,特别是将数据从内存加载到CPU寄存器,完成操作,然后将结果存储回内存。
代码的矢量化从来都不是一件容易的事情。然而,您可以简化它与Neon Intrinsics,以提高性能在场景中使用3D图形,信号和图像处理,音频编码,视频流。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3756次2020-07-13 17:40:25
-
浏览量:4066次2020-07-29 11:49:25
-
浏览量:1546次2023-08-30 10:00:35
-
浏览量:4097次2020-08-18 20:09:59
-
浏览量:2133次2023-07-27 10:28:36
-
浏览量:2314次2019-12-03 16:21:12
-
浏览量:2282次2018-12-19 09:52:55
-
浏览量:2426次2020-08-18 19:54:52
-
浏览量:2015次2018-12-19 10:11:25
-
浏览量:1671次2024-01-24 14:47:22
-
浏览量:1413次2023-07-26 17:52:40
-
浏览量:5598次2021-01-24 16:43:50
-
浏览量:2559次2020-08-14 18:38:14
-
浏览量:3562次2020-11-10 14:23:32
-
浏览量:5319次2020-04-15 10:00:55
-
浏览量:2278次2020-03-20 10:52:14
-
浏览量:3567次2020-08-21 19:39:43
-
浏览量:2872次2023-08-28 14:50:41
-
浏览量:6475次2021-03-31 15:36:17
恬静的小魔龙
他强任他强,清风拂山岗
-
18篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
恬静的小魔龙

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
