

Tensorflow搭建卷积神经网络实现情绪识别
【深度学习】Tensorflow搭建卷积神经网络实现情绪识别
文章目录
1 Tensorflow的基本使用方法
1.1 计算图
1.2 Feed
1.3 Fetch
1.4 其他解释
2 训练一个TensorFlow模型来识别情绪1 Tensorflow的基本使用方法
使用图 (graph) 来表示计算任务。
在被称之为 会话 (Session) 的上下文 (context) 中执行图。
使用 tensor 表示数据。
通过 变量 (Variable) 维护状态。
使用 feed 和 fetch 可以为任意的操作(arbitrary operation) 赋值或者从其中获取数据。
TensorFlow 是一个编程系统, 使用图来表示计算任务。图中的节点被称之为 op (operation 的缩写)。一个 op 获得 0 个或多个 Tensor, 执行计算,产生 0 个或多个 Tensor。每个 Tensor 是一个类型化的多维数组。 例如。 你可以将一小组图像集表示为一个四维浮点数数组, 这四个维度分别是 [batch, height, width, channels]。
一个TensorFlow 图描述了计算的过程。 为了进行计算,图必须在会话里被启动。会话将图的op分发到诸如CPU或GPU之类的 设备上,同时提供执行 op 的方法。这些方法执行后, 将产生的 tensor返回。在Python语言中,返回的tensor是numpy ndarray对象; 在C和C++语言中,返回的tensor是tensorflow::Tensor实例。
1.1 计算图
TensorFlow程序通常被组织成一个构建阶段和一个执行阶段。在构建阶段,op的执行步骤被描述成一个图。在执行阶段,使用会话执行执行图中的op。TensorFlow 支持 C, C++, Python 编程语言。三种语言的会话库 (session libraries) 是一致的。
import tensorflow as tf
# 创建一个常量 op, 产生一个 1x2 矩阵. 这个 op 被作为一个节点
# 加到默认图中.
#
# 构造器的返回值代表该常量 op 的返回值.
matrix1 = tf.constant([[3., 3.]])
# 创建另外一个常量 op, 产生一个 2x1 矩阵.
matrix2 = tf.constant([[2.],[2.]])
# 创建一个矩阵乘法 matmul op , 把 'matrix1' 和 'matrix2' 作为输入.
# 返回值 'product' 代表矩阵乘法的结果.
product = tf.matmul(matrix1, matrix2)在一个会话中启动图
构造阶段完成后,才能启动图。启动图的第一步是创建一个Session对象,如果无任何创建参数,会话构造器将启动默认图。
# 启动默认图.
sess = tf.Session()
# 调用 sess 的 'run()' 方法来执行矩阵乘法 op, 传入 'product' 作为该方法的参数.
# 上面提到, 'product' 代表了矩阵乘法 op 的输出, 传入它是向方法表明, 我们希望取回
# 矩阵乘法 op 的输出.
#
# 整个执行过程是自动化的, 会话负责传递 op 所需的全部输入. op 通常是并发执行的.
#
# 函数调用 'run(product)' 触发了图中三个 op (两个常量 op 和一个矩阵乘法 op) 的执行.
#
# 返回值 'result' 是一个 numpy `ndarray` 对象.
result = sess.run(product)
print result
# ==> [[ 12.]]
# 任务完成, 关闭会话.
sess.close()Tensor
TensorFlow程序使用tensor数据结构来代表所有的数据,计算图中, 操作间传递的数据都是 tensor。你可以把 TensorFlow tensor 看作是一个n维的数组或列表一个tensor包含一个静态类型rank,和一个 shape。
变量
变量维护图执行过程中的状态信息,下面的例子演示了如何使用变量实现一个简单的计数器。
# 创建一个变量, 初始化为标量 0.
state = tf.Variable(0, name="counter")
# 创建一个 op, 其作用是使 state 增加 1
one = tf.constant(1)
new_value = tf.add(state, one)
update = tf.assign(state, new_value)
# 启动图后, 变量必须先经过`初始化` (init) op 初始化,
# 首先必须增加一个`初始化` op 到图中.
init_op = tf.initialize_all_variables()
# 启动图, 运行 op
with tf.Session() as sess:
# 运行 'init' op
sess.run(init_op)
# 打印 'state' 的初始值
print sess.run(state)
# 运行 op, 更新 'state', 并打印 'state'
for _ in range(3):
sess.run(update)
print sess.run(state)
# 输出:
# 0
# 1
# 2
# 31.2 Feed
feed使用一个 tensor值临时替换一个操作的输出结果。你可以提供feed数据作为run()调用的参数。feed只在调用它的方法内有效,方法结束,feed 就会消失。最常见的用例是将某些特殊的操作指定为"feed"操作,标记的方法是使用 tf.placeholder() 为这些操作创建占位符。
1.3 Fetch
为了取回操作的输出内容,可以在使用Session对象的run()调用 执行图时,传入一些 tensor,这些 tensor 会帮助你取回结果。在之前的例子里, 我们只取回了单个节点 state,但是你也可以取回多个tensor:
1.4 其他解释
在TensorFlow中,变量(Variable)是特殊的张量(Tensor),它的值可以是一个任何类型和形状的张量。
与其他张量不同,变量存在于单个 session.run 调用的上下文之外,也就是说,变量存储的是持久张量,当训练模型时,用变量来存储和更新参数。除此之外,在调用op之前,所有变量都应被显式地初始化过。
占位符(placeholder)与feed
当我们构建一个模型的时候,有时候我们需要在运行时候输入一些初始数据,这个时候定义模型数据输入在tensorflow中就是用placeholder(占位符)来完成。它的定义如下:
def placeholder(dtype, shape=None, name=None):其中dtype表示数据类型,shape表示维度,name表示名称。它支持单个数值与任意维度的数组输入。
单个数值占位符定义
a = tf.placeholder(tf.float32)
b = tf.placeholder(tf.float32)
c = tf.add(a, b)当我们需要执行得到c的运行结果时候我们就需要在会话运行时候,通过feed来插入a与b对应的值,代码演示如下:
with tf.Session() as sess:
result = sess.run(c, feed_dict={a:3, b:4})
print(result)其中 feed_dict就是完成了feed数据功能,feed中文有喂饭的意思,这里还是很形象的,对定义的模型来说,数据就是最好的食物,所以就通过feed_dict来实现。
这句话划重点。
fetch用法
会话运行完成之后,如果我们想查看会话运行的结果,就需要使用fetch来实现,feed,fetch同样可以fetch单个或者多个值。
- fetch单个值
矩阵a与b相乘之后输出结果,通过会话运行接受到值c_res这个就是fetch单个值,fetch这个单词在数据库编程中比较常见,这里称为fetch也比较形象。代码演示如下:
EX:fetch cusorname into v_cursorname
import tensorflow as tf
a = tf.Variable(tf.random_normal([3, 3], stddev=3.0), dtype=tf.float32)
b = tf.Variable(tf.random_normal([3, 3], stddev=3.0), dtype=tf.float32)
c = tf.matmul(a, b);
init = tf.global_variables_initializer()
with tf.Session() as sess:
sess.run(init)
c_res = sess.run(c)
print(c_res)上述代码我们就fetch了两个值,这个就是feed与fetch的基本用法。下面我们就集合图像来通过feed与fetch实现一些图像ROI截取操作。代码演示如下:


2 训练一个TensorFlow模型来识别情绪
我们将编写一个python脚本来训练定制监督机器学习模型使用Tensorflow和Keras,将能够识别人脸的情绪。
我决定不使用InceptionV3等流行(和强大)模型提供的再培训脚本。跟Inception一起训练几乎肯定会更快,模型可能会有更好的准确性,但是在那里我已经完成了一些基本的TensorFlow教程,我想挑战自己,并尝试从头到尾学习模型和保存它为生产做好准备 ,预先训练的权重组合与新训练的权重,并加载模型在JVM服务器端项目。
获取数据
因此,我们需要获得所示情绪的标签数据(监督式学习!)。这意味着我们需要大量的脸部图像,这些图像被标记为情绪(“Angry”, “Sad”)或更好的情绪感受范围和它们的值(“Angry 10%”, “Hungry 90%”)。
我们使用的是使用Kaggle一个高质量的公共数据集,从Pokemon stats 到 baseball stats的在线存储库。用人脸和标记的情绪并不难找到一些数据。
下载数据(fer2013.csv)
https://www.kaggle.com/c/challenges-in-representation-learning-facial-expression-recognition-challenge/data
“数据由48x48像素灰度图像组成。脸部已被自动注册,以便脸部或多或少处于中心位置,并占用每张图像中相同数量的空间。任务是根据脸部表情中显示的情绪将每个脸部分类到七个类别中的一个(0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)
选择特定的数据集总有一些限制,在这种情况下,其中一些是:
只有7种情绪被识别。
图像很小(48,48)=>小模型输入=>必须调整高分辨率的照片到低分辨率->缺失高分辨率的细节。
图像面对“集中和占据了相同的空间在每个图像”= >难以复制没有建立一些作物现实世界图像美联储在更好地匹配对准= >可能会糟糕的准确性,如果我们不这样做
探索数据
尽快开始探索数据总是一个好主意,这样我们就可以了解我们正在处理的内容。探索数据的一个好方法是使用JupyterNotebook,以前称为iPythonNotebook,它允许您编写代码,笔记或运行代码段。
让我们来看看。https://github.com/JsFlo/EmotionRecTraining/blob/master/exploreEmotionRecData.ipynb
import pandas as pd
raw_data_csv_file_name = ‘data/fer2013.csv’
raw_data = pd.read_csv(raw_data_csv_file_name)
pd.read_csv(…)是Pandas库提供的函数,它返回一个DataFrame包含所有数据的对象,并提供有用的和易于使用的API。
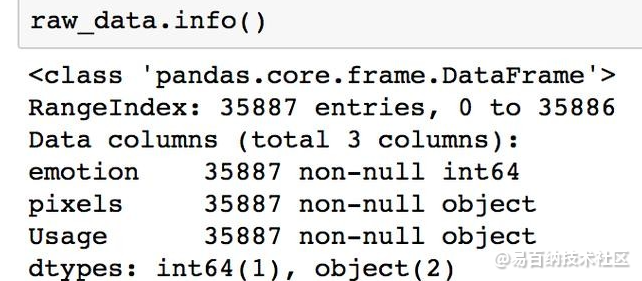
首先让我们快速描述数据使用dataFrame.info()。
转换输入像素以查看第一幅图像。
import numpy as np
img = raw_data["pixels"][0] # first image
val = img.split(" ")
x_pixels = np.array(val, 'float32')
x_pixels /= 255
x_reshaped = x.reshape(48,48)
%matplotlib inline # only if running in jupyter notebook
import matplotlib
import matplotlib.pyplot as plt
plt.imshow(x_reshaped, cmap= "gray", interpolation="nearest") plt.axis("off")
plt.show()
模型架构
在这个项目之前,我只有低级TensorFlow api的经验,所以我想尝试更高层次的东西,以便能够快速编写和遍历不同的体系结构(并且因为我的低级别TensorFlow的性能不佳)。
我决定尝试Keras,Keras是一个高级神经网络api,可以在TensorFlow上运行,并且可以访问对我来说很重要的底层TensorFlow图形,因为我想在训练它之后使用标准的TensorFlow保存模型方法。
同样为了规避我最初在我的第一个原型模型中看到的一些问题,我决定使用以前训练过的VGG16模型的帮助。
使用以前训练的模型
比如用于Inception模型的训练脚本,这些脚本会让你将一些图像放在一个文件夹中并运行一个python脚本。
“转移学习和领域适应是指在一种环境中学到的东西被利用来改善另一种环境中的泛化” - 深度学习,2016
这通常被称为转移学习,这个想法是你使用以前训练过的模型来帮助你完成一项任务。例如使用重新训练脚本,使用已知的体系结构模型和/或使用从训练中学习的权重,这种技术有很多变体。
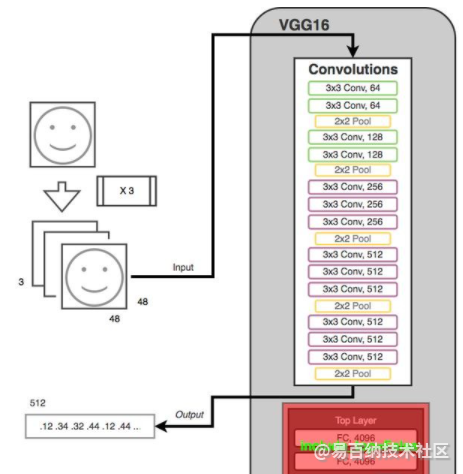
训练模型
我们要训练的实际模型将会是一个小的3个全连接层(+输出层),它将采用512个浮点值。使用高级Keras api使得这非常简单。
topLayerModel = Sequential()
topLayerModel.add(Dense(256,input_shape =(512,),activation ='relu'))
topLayerModel.add(Dense(256,input_shape =(256,),activation ='relu'))
topLayerModel .add(Dropout(0.5))
topLayerModel.add(Dense(128,input_shape =(256,),activation ='relu'))
topLayerModel.add(Dense(NUM_CLASSES,activation ='softmax'))
512 Input => 256
256 => 256
256 => 128
128 => 7 classes (Angry, Disgust, Fear, Happy, Sad, Surprise, Neutral)
现在我们需要的是训练(.fit())模型。
adamax = Adamax()
topLayerModel.compile(loss ='categorical_crossentropy',
optimizer = adamax,metrics = ['accuracy'])
topLayerModel.fit(x_train_feature_map,y_train,
validation_data =(x_train_feature_map,y_train),
nb_epoch = FLAGS.n_epochs,batch_size = FLAGS.batch_size)
x_train_feature_map-(n_inputs,512)的数组
y_train- 正确情感的one hot 矢量 (例如{0 = happy = [1,0,0,0,0,0,0]})(例如{5 = Surprise = [0,0,0,0,0 ,1,0]})
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1358次2023-09-06 11:12:55
-
浏览量:1864次2024-02-06 11:56:53
-
浏览量:2454次2024-02-20 17:08:32
-
浏览量:4567次2018-02-14 10:30:11
-
浏览量:1182次2023-07-18 13:41:23
-
浏览量:1300次2023-07-05 10:11:45
-
浏览量:1107次2023-07-05 10:11:51
-
浏览量:1689次2024-02-01 14:28:23
-
浏览量:5669次2021-04-15 15:51:43
-
浏览量:4766次2021-04-19 14:54:23
-
2023-01-12 11:47:40
-
浏览量:2230次2023-07-05 10:11:54
-
浏览量:1038次2023-09-06 10:09:13
-
浏览量:5417次2024-02-20 17:35:09
-
浏览量:1476次2024-02-01 14:20:47
-
浏览量:1227次2023-03-21 10:37:02
-
浏览量:2717次2024-02-06 11:41:16
-
浏览量:1181次2023-12-21 10:45:56
-
浏览量:1399次2023-09-27 15:48:35

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
