

卷积神经网络(CNN)详细介绍及其原理详解

文章目录
前言
本文总结了关于卷积神经网络(CNN)的一些基础的概念,并且对于其中的细节进行了详细的原理讲解,通过此文可以十分全面的了解卷积神经网络(CNN),非常适合于作为Deep Learning的入门学习。下面就是本篇博客的全部内容!
一、什么是卷积神经网络
卷积神经网络(Convolutional Neural Networks, CNN)这个概念的提出可以追溯到二十世纪80~90年代,但是有那么一段时间这个概念被“雪藏”了,因为当时的硬件和软件技术比较落后,而随着各种深度学习理论相继被提出以及数值计算设备的高速发展,卷积神经网络得到了快速发展。那究竟什么是卷积神经网络呢?以手写数字识别为例,整个识别的过程如下所示:
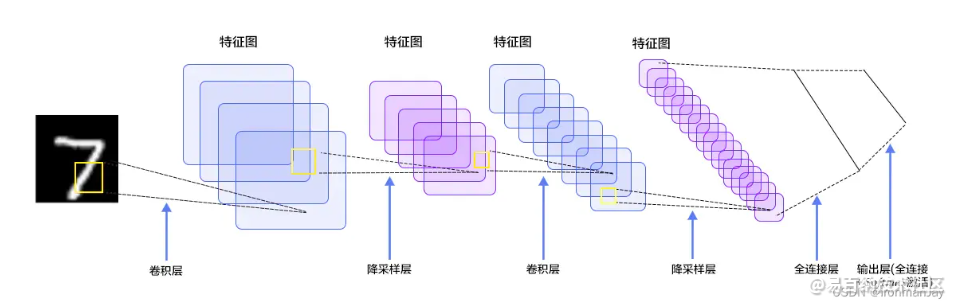
以上过程就是识别手写数字的全部过程,这个项目我之前也写过相关博客并开源了代码,感兴趣的同学可查阅: 基于CNN的MINIST手写数字识别项目代码以及原理详解。话说回来,可以看到整个过程需要在如下几层进行运算:
- 输入层:输入图像等信息
- 卷积层:用来提取图像的底层特征
- 池化层:防止过拟合,将数据维度减小
- 全连接层:汇总卷积层和池化层得到的图像的底层特征和信息
- 输出层:根据全连接层的信息得到概率最大的结果
可以看到其中最重要的一层就是卷积层,这也是卷积神经网络名称的由来,下面将会详细讲解这几层的相关内容。
二、输入层
输入层比较简单,这一层的主要工作就是输入图像等信息,因为卷积神经网络主要处理的是图像相关的内容,但是我们人眼看到的图像和计算机处理的图像是一样的么?很明显是不一样的,对于输入图像,首先要将其转换为对应的二维矩阵,这个二位矩阵就是由图像每一个像素的像素值大小组成的,我们可以看一个例子,如下图所示的手写数字“8”的图像,计算机读取后是以像素值大小组成的二维矩阵存储的图像。

上图又称为灰度图像,因为其每一个像素值的范围是0~255(由纯黑色到纯白色),表示其颜色强弱程度。另外还有黑白图像,每个像素值要么是0(表示纯黑色),要么是255(表示纯白色)。我们日常生活中最常见的就是RGB图像,有三个通道,分别是红色、绿色、蓝色。每个通道的每个像素值的范围也是0~255,表示其每个像素的颜色强弱。但是我们日常处理的基本都是灰度图像,因为比较好操作(值范围较小,颜色较单一),有些RGB图像在输入给神经网络之前也被转化为灰度图像,也是为了方便计算,否则三个通道的像素一起处理计算量非常大。当然,随着计算机性能的高速发展,现在有些神经网络也可以处理三通道的RGB图像。
现在我们已经知道了,输入层的作用就是将图像转换为其对应的由像素值构成的二维矩阵,并将此二维矩阵存储,等待后面几层的操作。
三、卷积层
那图片输入进来之后该怎么处理呢?假设我们已经得到图片的二维矩阵了,想要提取其中特征,那么卷积操作就会为存在特征的区域确定一个高值,否则确定一个低值。这个过程需要通过计算其与卷积核(Convolution Kernel)的乘积值来确定。假设我们现在的输入图片是一个人的脑袋,而人的眼睛是我们需要提取的特征,那么我们就将人的眼睛作为卷积核,通过在人的脑袋的图片上移动来确定哪里是眼睛,这个过程如下所示: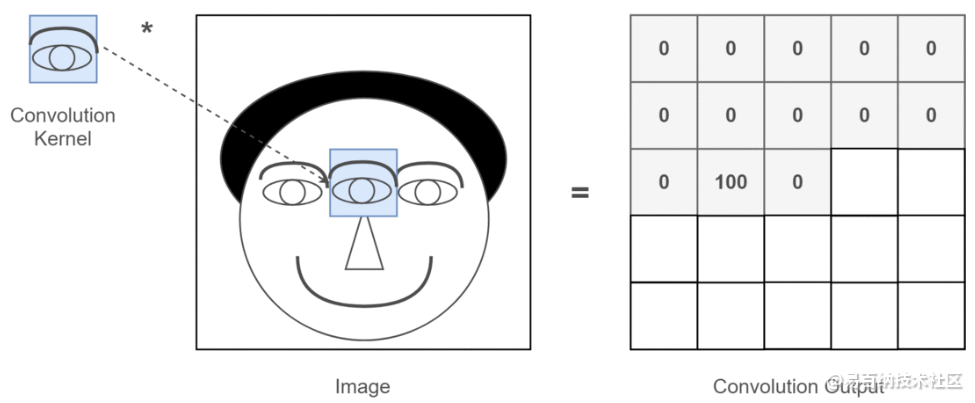
通过整个卷积过程又得到一个新的二维矩阵,此二维矩阵也被称为特征图(Feature Map),最后我们可以将得到的特征图进行上色处理(我只是打个比方,比如高值为白色,低值为黑色),最后可以提取到关于人的眼睛的特征,如下所示:
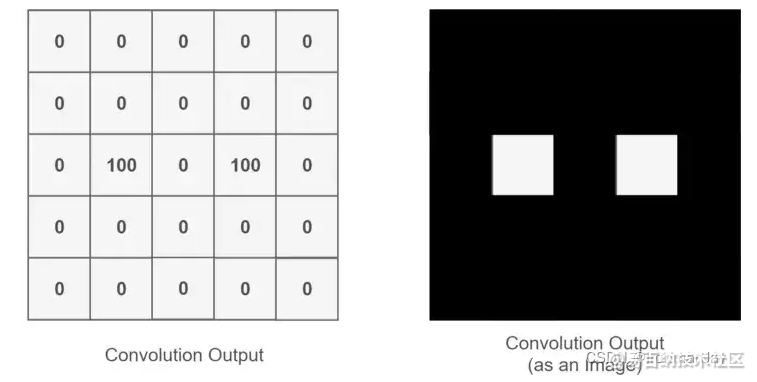
看着上面的描述可能有点懵,别急,首先卷积核也是一个二维矩阵,当然这个二维矩阵要比输入图像的二维矩阵要小或相等,卷积核通过在输入图像的二维矩阵上不停的移动,每一次移动都进行一次乘积的求和,作为此位置的值,这个过程如下图所示:
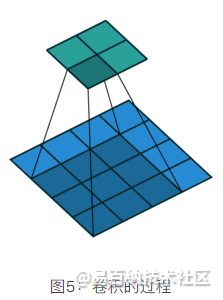
可以看到,整个过程就是一个降维的过程,通过卷积核的不停移动计算,可以提取图像中最有用的特征。我们通常将卷积核计算得到的新的二维矩阵称为特征图,比如上方动图中,下方移动的深蓝色正方形就是卷积核,上方不动的青色正方形就是特征图。
有的读者可能注意到,每次卷积核移动的时候中间位置都被计算了,而输入图像二维矩阵的边缘却只计算了一次,会不会导致计算的结果不准确呢?
让我们仔细思考,如果每次计算的时候,边缘只被计算一次,而中间被多次计算,那么得到的特征图也会丢失边缘特征,最终会导致特征提取不准确,那为了解决这个问题,我们可以在原始的输入图像的二维矩阵周围再拓展一圈或者几圈,这样每个位置都可以被公平的计算到了,也就不会丢失任何特征,此过程可见下面两种情况,这种通过拓展解决特征丢失的方法又被称为Padding。
- Padding取值为1,拓展一圈
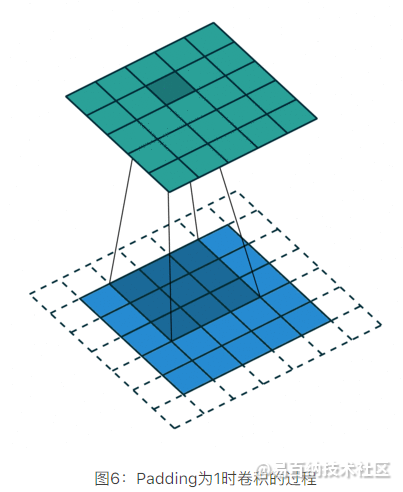
- Padding取值为2,拓展两圈

那如果情况再复杂一些呢?如果我们使用两个卷积核去提取一张彩色图片呢?之前我们介绍过,彩色图片都是三个通道,也就是说一个彩色图片会有三个二维矩阵,当然,我们仅以第一个通道示例,否则太多了也不好介绍。此时我们使用两组卷积核,每组卷积核都用来提取自己通道的二维矩阵的特征,刚才说了,我们只考虑第一通道的,所以说我们只需要用两组卷积核的第一个卷积核来计算得到特征图就可以了,那么这个过程可见下图

看着上面的动图确实有些不知所措是吧,我来解释一下,按照刚才的思路,输入图片是彩色图片,有三个通道,所以输入图片的尺寸就是7×7×3,而我们只考虑第一个通道,也就是从第一个7×7的二维矩阵中提取特征,那么我们只需要使用每组卷积核的第一个卷积核即可,这里可能有读者会注意到Bias,其实它就是偏置项,最后计算的结果加上它就可以了,最终通过计算就可以得到特征图了。可以发现,有几个卷积核就有几个特征图,因为我们现在只使用了两个卷积核,所以会得到两个特征图。
以上就是关于卷积层的一些相关知识,当然,本文也只是一个入门,所以说还有一些比较复杂的内容没有进行深入阐述,这个就需要等到过后的学习与总结了。
四、池化层
刚才我们也提到了,有几个卷积核就有多少个特征图,现实中情况肯定更为复杂,也就会有更多的卷积核,那么就会有更多的特征图,当特征图非常多的时候,意味着我们得到的特征也非常多,但是这么多特征都是我们所需要的么?显然不是,其实有很多特征我们是不需要的,而这些多余的特征通常会给我们带来如下两个问题:
- 过拟合
- 维度过高
为了解决这个问题,我们可以利用池化层,那什么是池化层呢?池化层又称为下采样,也就是说,当我们进行卷积操作后,再将得到的特征图进行特征提取,将其中最具有代表性的特征提取出来,可以起到减小过拟合和降低维度的作用,这个过程如下所示:

那有的读者可能会问了,我应该以什么规则进行特征提取呢?其实这个过程类似于卷积的过程,就是一个正方形的小方块在图片上进行移动,每次我们取这个正方形方框中最具有代表性的特征,那么问题又来了,如何提取到最有代表性的特征呢,通常有两种方法:
- 最大池化
顾名思义,最大池化就是每次取正方形中所有值的最大值,这个最大值也就相当于当前位置最具有代表性的特征,这个过程如下所示: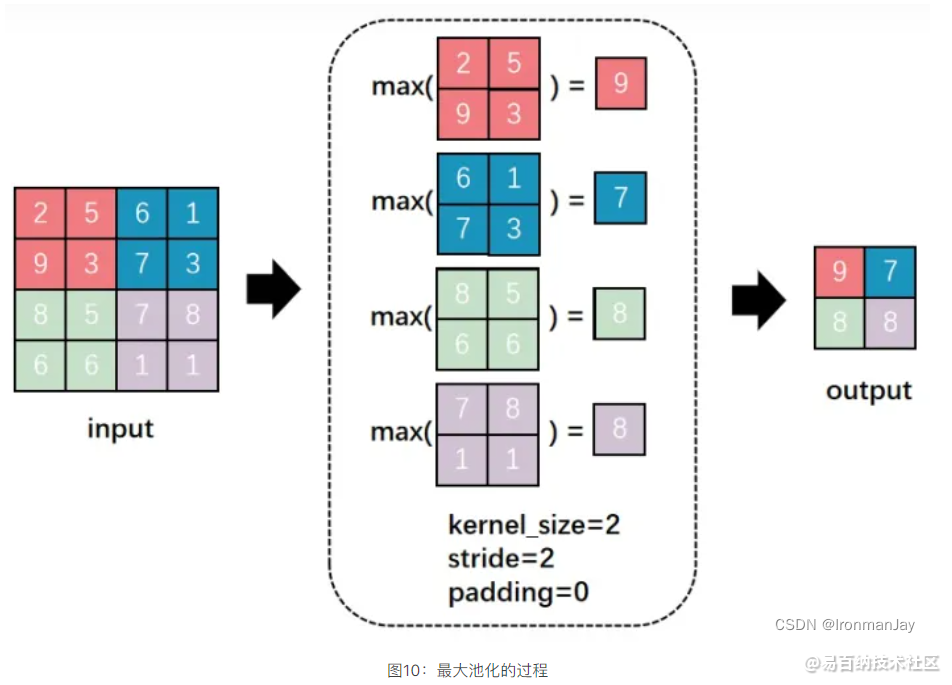
这里有几个参数需要说明一下:
kernel_size = 2:池化过程使用的正方形尺寸是2×2,如果是在卷积的过程中就说明卷积核的大小是2×2
stride = 2:每次正方形移动两个位置(从左到右,从上到下),这个过程其实和卷积的操作过程一样
padding = 0:这个之前介绍过,如果此值为0,说明没有进行拓展
- 平均池化
平均池化就是取此正方形区域中所有值的平均值,考虑到每个位置的值对于此处特征的影响,平均池化计算也比较简单,整个过程如下图所示:
对于其中的参数含义与上面介绍的最大池化一致,另外,需要注意计算平均池化时采用向上取整。
以上就是关于池化层的所有操作,我们再回顾一下,经过池化后,我们可以提取到更有代表性的特征,同时还减少了不必要的计算,这对于我们现实中的神经网络计算大有脾益,因为现实情况中神经网络非常大,而经过池化层后,就可以明显的提高模型的效率。所以说,池化层的好处很多,将其优点总结如下:
在减少参数量的同时,还保留了原图像的原始特征
有效防止过拟合
为卷积神经网络带来平移不变性
以上两个优点我们之前已经介绍过了,那什么又是平移不变性呢?可以用我们之前的一个例子,如下图所示:
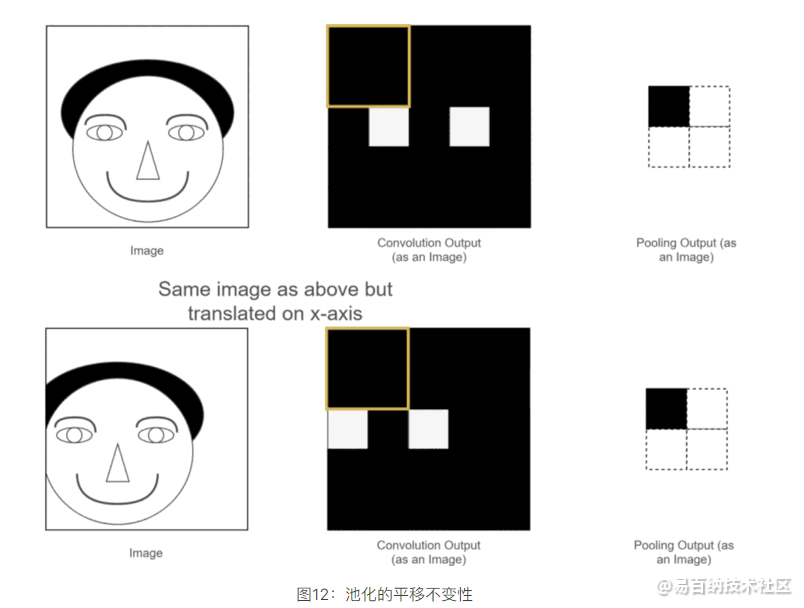
可以看到,两张原始图片的位置有所不同,一个是正常的,另一个是人的脑袋稍稍左移了一些,经过卷积操作后,得到各自对应的特征图,这两张特征图也和原始图片的位置相对应,一个眼睛特征的位置是正常的,另一个眼睛特征的位置稍稍左移了一些,虽然人可以分辨,但是经过神经网络计算后,就可能带来误差,因为应该出现眼睛的位置并没有出现眼睛,那应该怎么办呢?此时使用池化层进行池化操作,可以发现,虽然池化之前两幅图片的眼睛特征不在一个位置,但是经过池化之后,眼睛特征的位置都是相同的,这就为后续神经网络的计算带来了方便,此性质就是池化的平移不变性
五、全连接层
假设还是上面人的脑袋的示例,现在我们已经通过卷积和池化提取到了这个人的眼睛、鼻子和嘴的特征,如果我想利用这些特征来识别这个图片是否是人的脑袋该怎么办呢?此时我们只需要将提取到的所有特征图进行“展平”,将其维度变为1 × x 1×x1×x,这个过程就是全连接的过程,也就是说,此步我们将所有的特征都展开并进行运算,最后会得到一个概率值,这个概率值就是输入图片是否是人的概率,这个过程如下所示:
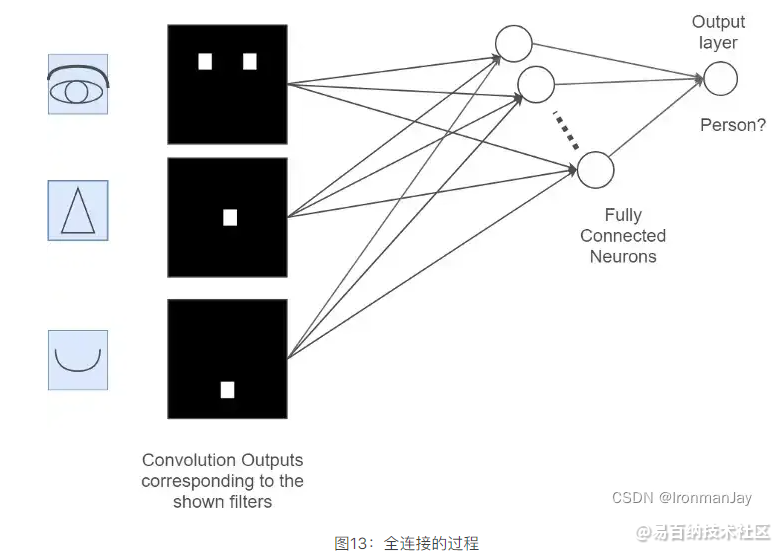
单看这个过程可能还是不太清晰,所以我们可以把之前的过程与全连接层结合起来,如下图所示:
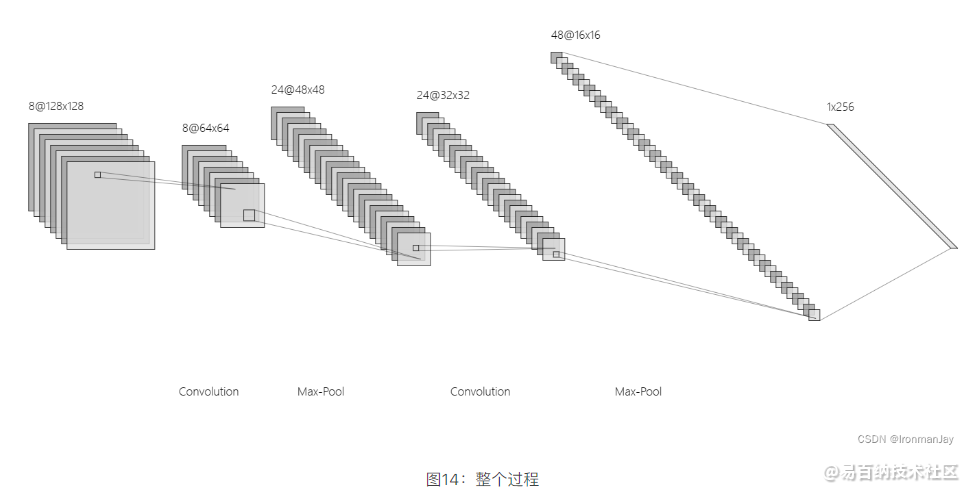
可以看到,经过两次卷积和最大池化之后,得到最后的特征图,此时的特征都是经过计算后得到的,所以代表性比较强,最后经过全连接层,展开为一维的向量,再经过一次计算后,得到最终的识别概率,这就是卷积神经网络的整个过程。
六、输出层
卷积神经网络的输出层理解起来就比较简单了,我们只需要将全连接层得到的一维向量经过计算后得到识别值的一个概率,当然,这个计算可能是线性的,也可能是非线性的。在深度学习中,我们需要识别的结果一般都是多分类的,所以每个位置都会有一个概率值,代表识别为当前值的概率,取最大的概率值,就是最终的识别结果。在训练的过程中,可以通过不断地调整参数值来使识别结果更准确,从而达到最高的模型准确率。

七、回顾整个过程
卷积神经网络最经典的应用莫过于手写数字识别了,比如我现在手写一个数字8,那么卷积神经网络是如何识别出来的呢?整个识别的过程如下图所示: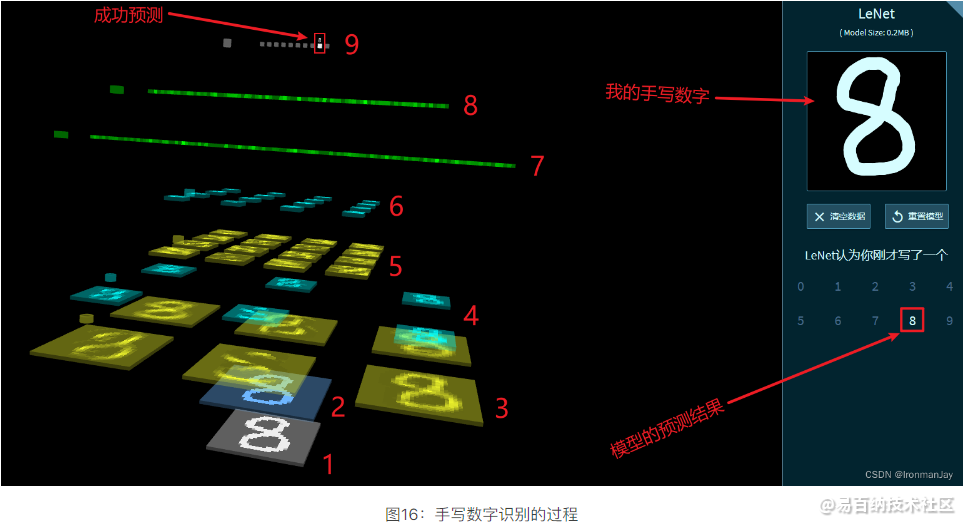
- 将手写数字图片转换为像素矩阵
- 对像素矩阵进行Padding不为0的卷积运算,目的是保留边缘特征,生成一个特征图
- 对这个特征图使用六个卷积核进行卷积运算,得到六个特征图
- 对每个特征图进行池化操作(也可称为下采样操作),在保留特征的同时缩小数据流,生成六个小图,这六个小图和上一层各自的特征图长得很像,但尺寸缩小了
- 对池化操作后得到的六个小图进行第二次卷积运算,生成了更多的特征图
- 对第二次卷积生成的特征图进行池化操作(下采样操作)
- 将第二次池化操作得到的特征进行第一次全连接
- 将第一次全连接的结果进行第二次全连接
- 将第二次全链接的结果进行最后一次运算,这种运算可能是线性的也可能是非线性的,最终每个位置(一共十个位置,从0到9)都有一个概率值,这-个概率值就是将输入的手写数字识别为当前位置数字的概率,最后以概率最大的位置的值作为识别结果。可以看到,右侧上方是我的手写数字,右侧下方是模型(LeNet)的识别结果,最终的识别结果与我输入的手写数字是一致的,这一点从图片左边最上边也可以看到,说明此模型可以成功识别手写数字
总结
有限,有错的地方还望读者指正,谢谢大家!下篇博客见!
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1476次2024-02-01 14:20:47
-
浏览量:4568次2018-02-14 10:30:11
-
浏览量:1865次2024-02-06 11:56:53
-
浏览量:2720次2024-02-06 11:41:16
-
浏览量:1185次2023-07-18 13:41:23
-
浏览量:1301次2023-07-05 10:11:45
-
浏览量:1109次2023-07-05 10:11:51
-
浏览量:5669次2021-04-15 15:51:43
-
浏览量:1359次2023-09-06 11:12:55
-
浏览量:2231次2023-07-05 10:11:54
-
浏览量:1039次2023-09-06 10:09:13
-
浏览量:5869次2021-05-21 17:03:03
-
浏览量:2456次2024-02-20 17:08:32
-
浏览量:1690次2024-02-01 14:28:23
-
浏览量:7028次2021-07-05 16:39:40
-
浏览量:1227次2023-03-21 10:37:02
-
浏览量:4768次2021-04-19 14:54:23
-
浏览量:1185次2023-09-04 11:16:00
-
浏览量:141次2023-08-31 08:46:00

tomato
===============













-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
tomato

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
