

【深度学习】深入浅出YYOLOv3目标检测算法(图片和视频)

文章目录
1 概述
2 一个全卷积神经网络——Darknet-53
3 解释输出
4 代码实现
4.1 导入项目
4.2 执行脚本
4.3 预测图像
4.4 预测视频
5 yolo3连接网络摄像头实现目标检测命令
6 谈谈深度学习目标检测中的遮挡问题1 概述
YOLO是“You Only Look Once”的简称,它虽然不是最精确的算法,但在精确度和速度之间选择的折中,效果也是相当不错。YOLOv3借鉴了YOLOv1和YOLOv2,虽然没有太多的创新点,但在保持YOLO家族速度的优势的同时,提升了检测精度,尤其对于小物体的检测能力。YOLOv3算法使用一个单独神经网络作用在图像上,将图像划分多个区域并且预测边界框和每个区域的概率。
2 一个全卷积神经网络——Darknet-53
YOLOv3仅使用卷积层,使其成为一个全卷积网络(FCN)。文章中,作者提出一个新的特征提取网络,Darknet-53。正如其名,它包含53个卷积层,每个后面跟随着batch normalization层和leaky ReLU层。没有池化层,使用步幅为2的卷积层替代池化层进行特征图的降采样过程,这样可以有效阻止由于池化层导致的低层级特征的损失。Darknet-53网络如下图左边所示。
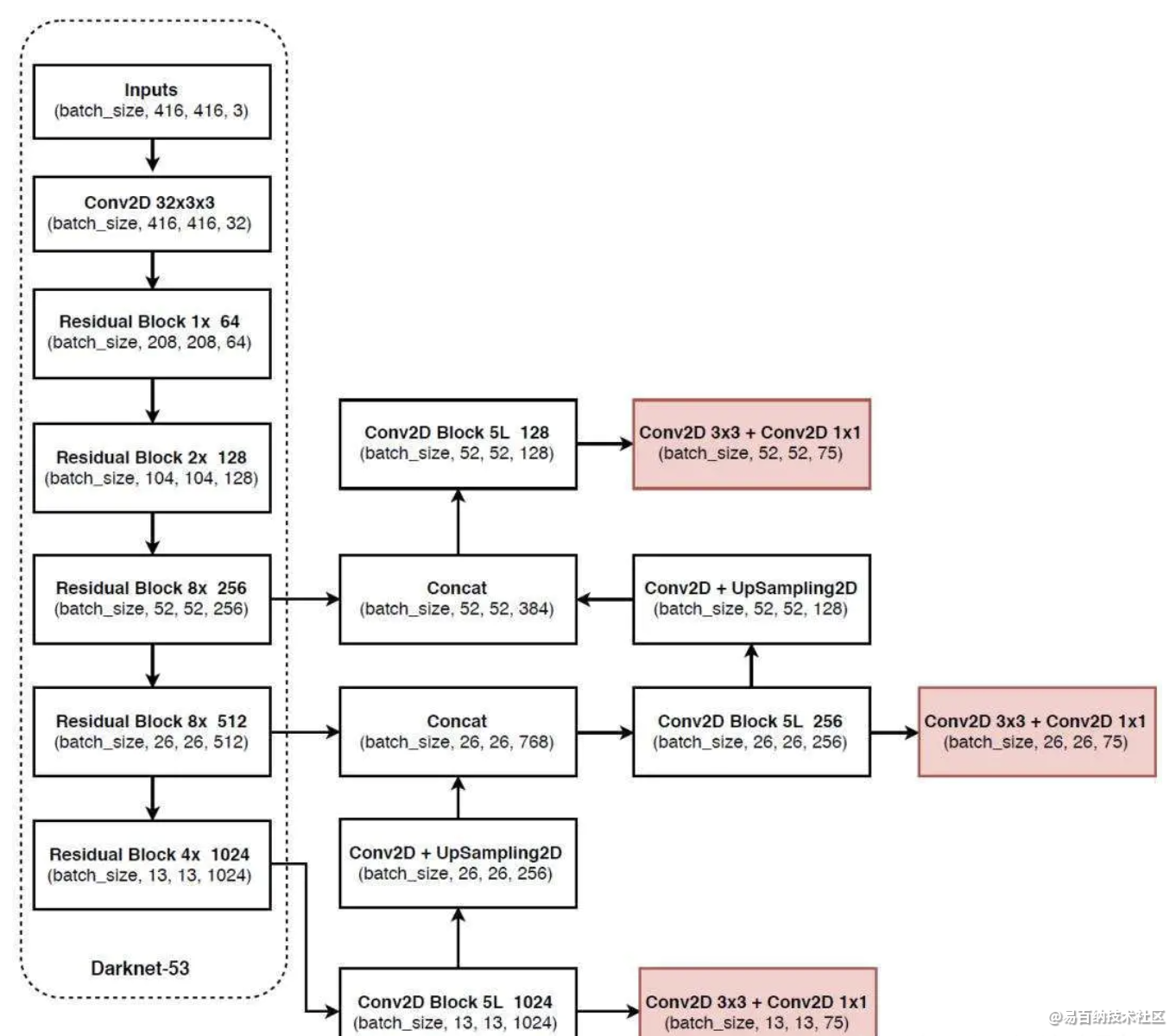
3 解释输出
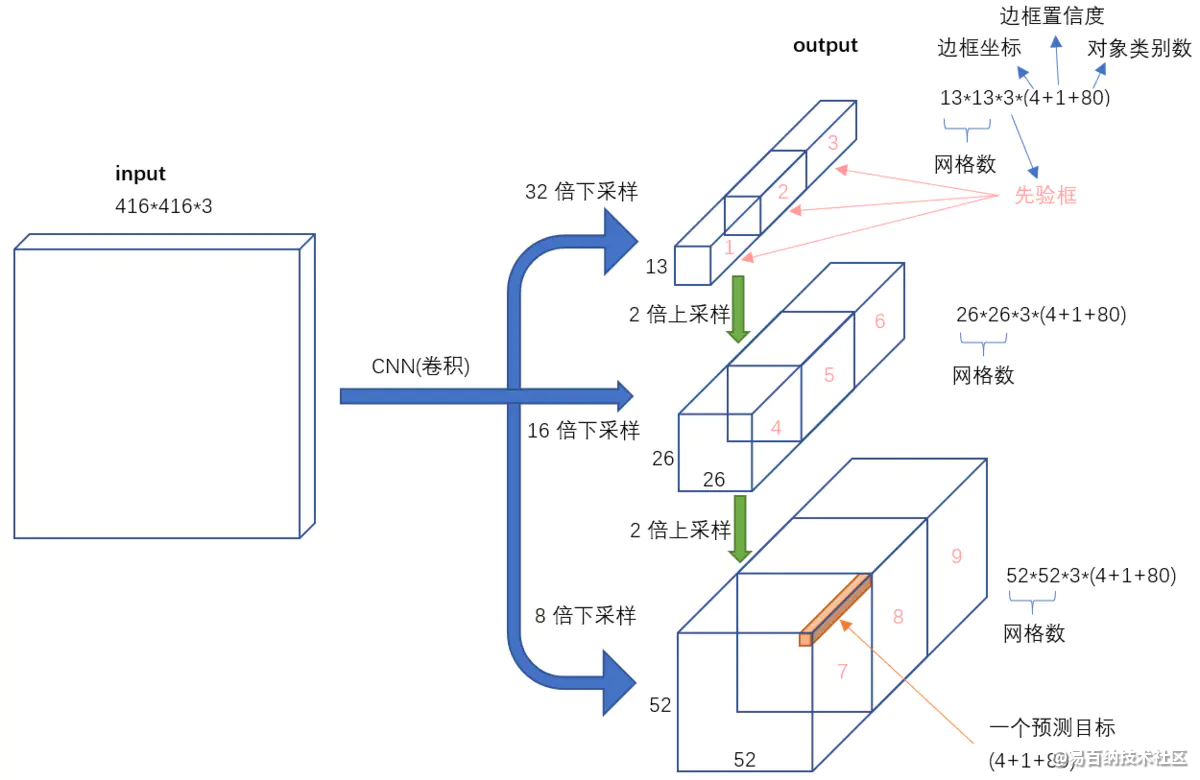
4 代码实现
代码已开源在github。
https://github.com/lixiang007666/yolov3_with_opencv_colab
4.1 导入项目
from google.colab import drive
drive.mount('/content/drive')import os
os.chdir("/content/drive/My Drive")
!lshttps://github.com/lixiang007666/yolov3_with_opencv_colab.git
os.chdir("/content/drive/My Drive/yolov3_with_opencv")
!ls4.2 执行脚本
!bash getModels.sh
4.3 预测图像
!python object_detection_yolo.py --image=/content/drive/MyDrive/yolov3_with_opencv/demo/dog.jpg
4.4 预测视频
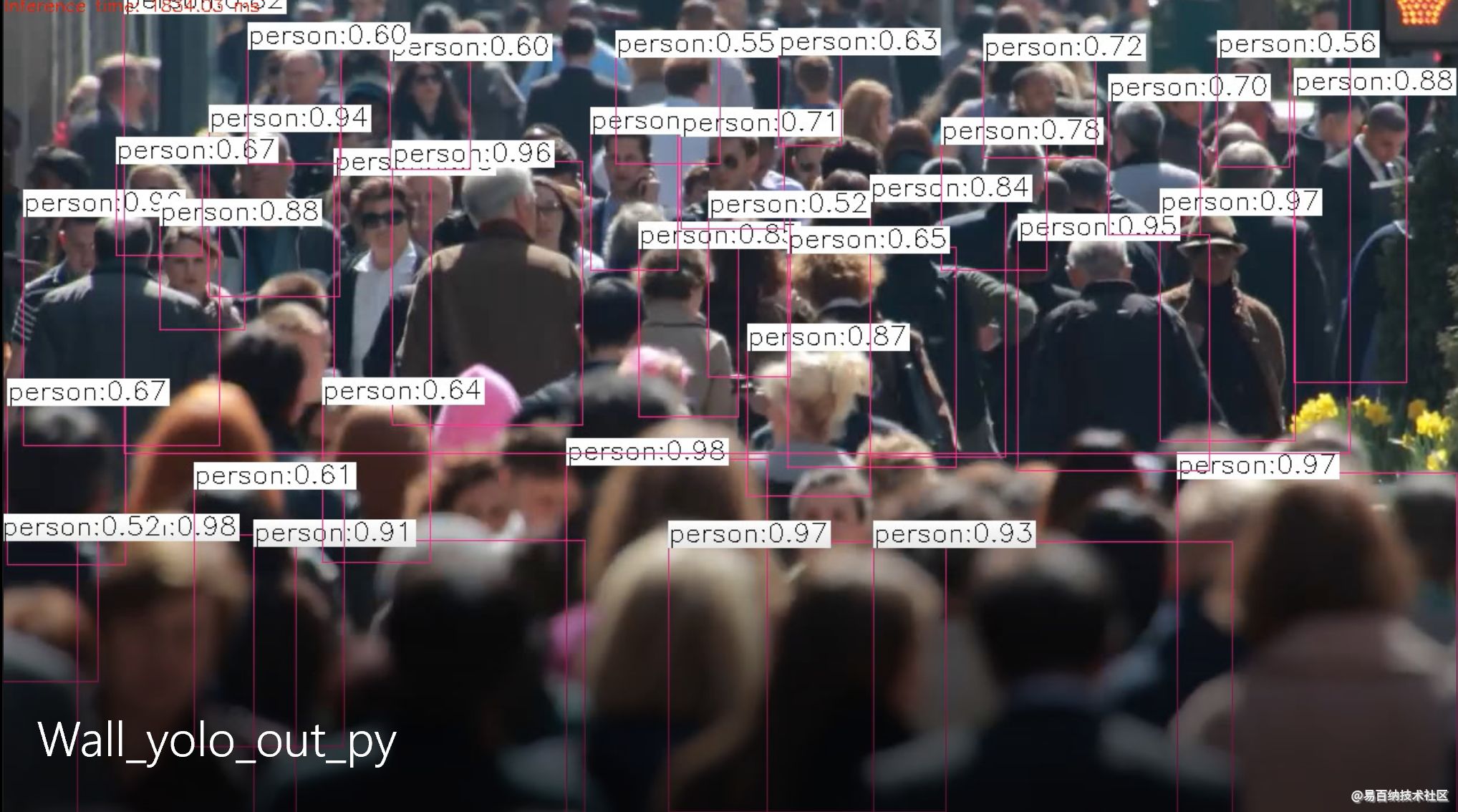
!python3 object_detection_yolo.py --video=/content/drive/MyDrive/yolov3_with_opencv/demo/wall.mp4时间略长。



5 yolo3连接网络摄像头实现目标检测命令
yolo3连接摄像头实现目标检测
yolo3使用较灵活,可以通过修改源码,来实现自己的一些功能。如果想要连接网络摄像头进行目标检测。针对目前我用的相机是海康或大华的,可以直接采用rtsp协议。测试连接成功。环境:Windows,darknet-yolo3。如果大家还没有实现yolo3的目标检测功能,可以参考我的另一篇博客:https://blog.csdn.net/wszswllnzn_/article/details/100760477
在命令中输入:darknet.exe detector demo cfg/coco.data yolov3.cfg yolov3.weights rtsp://admin:123456@192.168.43.12。使用此命令可以直接获取视频流。
上述指令中的admin和123456分别是摄像头ip camera的用户名和密码,摄像头的IP是192.168.43.12。需要根据知己的设备进行更改。
备注: 如果上述指令行不通,不妨试试相机自带的协议格式。
1、海康或大华摄像头
darknet.exe detector demo cfg/coco.data yolov3.cfg yolov3.weights rtsp://admin:123456@192.168.43.12:554/cam/realmonitor?channel=1&subtype=0
2、雄迈摄像头
darknet.exe detector demo cfg/coco.data yolov3.cfg yolov3.weights rtsp://192.168.43.12:554/user=admin&password=admin&channel=1&stream=0.sdp?real_stream
6 谈谈深度学习目标检测中的遮挡问题
尽管目标检测算法整体上已经相对比较成熟,但是在特殊场景下的表现还有很多优化空间,比如图片中的目标有遮挡、图像运动模糊、目标为可改变形状的非刚性物体等。本文主要是针对遮挡问题,之前在做游戏目标检测时也遇到过这个问题,当时只是考虑增加训练样本的多样性,最近,笔者读了几篇解决目标检测中的遮挡问题的文章,也看了一些网友的解析,觉得若有所悟,不自觉地想把自己的理解记录下来,自认为“一万个人眼中有一万个哈姆雷特”,希望能够从某个侧面对大家有所帮助。
目标检测中存在两类遮挡,(1)待检测的目标之间相互遮挡;(2)待检测的目标被干扰物体遮挡。比如下图,

具体来说,如果检测任务的目标是汽车和人,那么汽车被人遮挡,而且人被干扰物体(牛)遮挡。因为算法只学习待检测的物体的特征,所以第二种遮挡只能通过增加样本来优化检测效果。
在现实的检测任务中,只有比较特殊的场景需要考虑遮挡问题,比如行人检测、公交车上密集人群检测、牲畜数量计算等,本文将介绍的两篇文章是针对行人检测问题的,也可以复用到其它的应用场景(ps: 大家如果想发paper,也可以借鉴这两篇文章解决问题的方式)。
1 Repulsion Loss: Detecting Pedestrians in a Crowd
2 Occlusion-aware R-CNN: Detecting pedestrians in a Crowd
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6077次2021-06-23 15:25:25
-
浏览量:7378次2021-05-24 15:13:24
-
浏览量:18304次2021-05-31 17:01:39
-
浏览量:10425次2021-04-20 15:42:26
-
浏览量:6140次2021-06-22 16:53:40
-
浏览量:6191次2021-04-20 15:43:03
-
浏览量:11627次2021-06-09 12:09:57
-
浏览量:5661次2021-04-27 16:30:07
-
浏览量:6597次2021-06-16 11:22:18
-
浏览量:5343次2021-04-21 17:05:28
-
浏览量:10117次2024-02-02 17:13:35
-
浏览量:5372次2021-04-21 17:05:56
-
浏览量:1277次2023-12-18 18:07:01
-
浏览量:2238次2023-09-08 15:20:45
-
浏览量:1724次2023-12-11 16:56:37
-
浏览量:1195次2023-06-02 17:42:13
-
浏览量:1417次2023-12-14 17:05:19
-
浏览量:12007次2021-04-27 00:28:09
-
浏览量:6465次2021-07-09 11:16:51

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
