

【深度学习】深入浅出nnUnet的数据处理方法
【深度学习】深入浅出nnUnet的数据处理方法
文章目录
1 nnUNet数据预处理crop方法
2 预测结果可视化
3 如何针对三维医学图像分割任务进行通用数据预处理:nnUNet中预处理流程总结
3.1 数据格式转换
3.2 图像裁剪Crop
3.3 重采样Resample
3.4 标准化Normalization
4 后处理1 nnUNet数据预处理crop方法
plan_and_preprocess
运行分割,首先需要对数据集进行数据预处理,这也是nnUNet的精髓所在。
nnUNet_plan_and_preprocess -t NUM --verify_dataset_integrity我们进入 入口函数,绘制整个流程图:
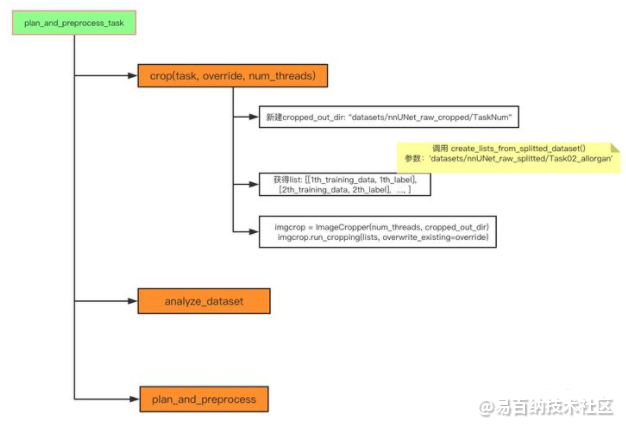
加下来我们分析这三个最为关键的函数。
首先从 crop()开始,
lists, _ = create_lists_from_splitted_dataset(splitted_4d_output_dir_task)
num_threads: 4, cropped_out_dir: datasets/nnUNet_raw_cropped/Task02_allorgan
imgcrop = ImageCropper(num_threads, cropped_out_dir)
imgcrop.run_cropping(lists, overwrite_existing=override)
shutil.copy(join(splitted_4d_output_dir, task_string, "dataset.json"), cropped_out_dir)核心其实还是调用了外部的 ImageCropper()类来实现的。
ImageCropper类
init() 类不多说,设置 output_folder 为 datasets/nnUNet_raw_cropped/TaskNUM_XXX,以及进程数 num_threads 。
之后主程序调用 run_cropping(),将处理后的数据及数据属性文件放入 output_folder中。
Q: 为什么把crop定义成一个类?
A: 从上面的介绍可以看出crop这个过程虽然目的很简单,但涉及到很多其他需求,比如数据的读取,存储,bounding box的记录,定义成类使得不同小功能之间更加模块化。
Q: run_cropping中为什么把参数传给私有方法_load_crop_save_star,而不是直接传给load_crop_save方法?
A: 仅从功能上来说,实际上没有特殊意义;猜想应该是作者为了后续的扩展性及代码的调用便捷考虑,后续可能会扩展 load_crop_save_star的操作,项目较大,代码抽象度高的时候,这么做的优势就显出来。
为什么把crop_from_list_of_files和crop定义为静态方法?
A: 静态方法的文档。方便用类方法直接调用,testing的时候也会用到这个方法。
Q: ImageCropper类中最后两个方法load_properties,save_properties在这里没用到吗?
A: 目前看来是的。这两个函数功能很清楚,后续如果看到有用了再补充。
2 预测结果可视化
大多数医学图像的分割都是有具体意义的,比如对血管的分割。所有我们有时需要对自己的预测结果进行可视化,以便于对结果有个大致的分析。
import matplotlib.pyplot as plt
import numpy as np
import nrrd
import os
from glob import glob
def plotNrrd(filepath):
arr0=nrrd.read('C:/Users/32920/Desktop/nnUnet结果/'+filepath)[0]
x=[]
y=[]
z=[]
for i in range(len(arr0)):
for j in range(len(arr0[0])):
for k in range(len(arr0[0][0])):
if(arr0[i][j][k]==1):
print(i+1,' ',j+1,' ',k+1)
x.append(i+1)
y.append(j+1)
z.append(k+1)
fileindex=(filepath.split('/')[-1]).split('.')[0]
with open('nrrd'+fileindex+'_x.txt','a')as f:
f.write(','.join(map(str,x)))
with open('nrrd'+fileindex+'_y.txt','a')as f1:
f1.write(','.join(map(str,y)))
with open('nrrd'+fileindex+'_z.txt','a')as f2:
f2.write(','.join(map(str,z)))
ax = plt.figure().add_subplot(111, projection = '3d')
#基于ax变量绘制三维图
#xs表示x方向的变量
#ys表示y方向的变量
#zs表示z方向的变量,这三个方向上的变量都可以用list的形式表示
#m表示点的形式,o是圆形的点,^是三角形(marker)
#c表示颜色(color for short)
ax.scatter(x, y, z, c = 'r', marker = '^') #点为红色三角形
#设置坐标轴
ax.set_xlabel('X Label')
ax.set_ylabel('Y Label')
ax.set_zlabel('Z Label')
plt.title(fileindex+'.nrrd')
#显示图像
plt.savefig(filepath+'.png')
if __name__=='__main__':
# plotNpz('Predict_Masks_labeled_org/30.npz')
#plotNrrd('ASOCA/Test_Masks/32.nrrd')
files = glob('*.nrrd')
for file in files:
plotNrrd(file)
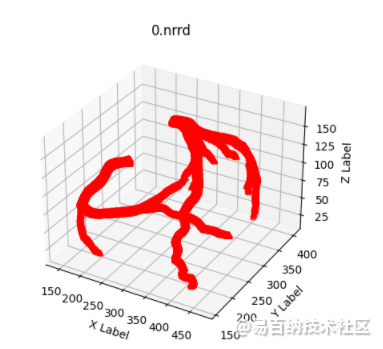
3 如何针对三维医学图像分割任务进行通用数据预处理:nnUNet中预处理流程总结
根据nnUNet框架,三维医学图像分割的通用预处理可以分为四步,分别是数据格式的转换,裁剪crop,重采样resample以及标准化normalization。
3.1 数据格式转换
常见的医学图像格式有DICOM(后缀名为.dcm),MHD(后缀名为.mhd和.raw)以及NIFTY(后缀名为.nii或.nii.gz)。这几种格式都不太方便直接进行操作,一般都使用对应的Python库将数据进行读取后,转换成numpy数组后再进行后续处理。
nnUNet中给出了一种建议的目标数据格式,将每一个病例的数据,都存成一个四维numpy数组以及与之对应的pickle文件。
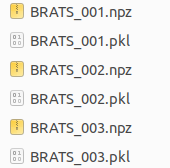
MSD Task01_BrainTumor数据转换后存储形式
四维数组array(CXYZ)中,第一个维度的最后array[-1,:,:,:]存储的是分割标注结果。而第一个维度的前面存储不同模态的数据,如MRI数据中有FLAIR, T1w, t1gd, T2w等四种模态,array[0,:,:,:]表示FLAIR序列成像的强度数据,array[1,:,:,:]表示T1加权的强度数据,以此类推。如果仅单模态,则四维数组第一维度长度仅为2,分别表示影像数据以及标注数据。四维数组array的后三个维度代表x,y,z三个坐标表示的三维数据,对于原始影像数据,值大小代表强度,而对于标注结果,后三个维度的三维数据值分别为0,1,2……表示不同的标注类别。在后续的代码中,为了简便,将不同模态的原始图像与分割标注分开,使用data(CXYZ)代表四维图像数据,使用seg(XYZ)代表三维标注数据。
而pickle文件中存储该医学影像中其它的重要信息,是对numpy数组提供信息的补充。包含spacing,direction,origin等信息。
3.2 图像裁剪Crop
图像裁剪就是将三维的医学图像裁剪到它的非零区域,具体方法就是在图像中寻找一个最小的三维bounding box,该bounding box区域以外的值为0,使用这个bounding box对图像进行裁剪。相比裁剪前,裁剪后的图像对于最后的分割结果没有影响,但是却可以减小图像尺寸,避免无用的计算,提高计算效率。这个操作对于部分数据集如大脑数据集比较有效,这些数据集中外围全黑的背景相对较多。裁剪在nnUNet的实现中可以分为3步。
大脑MRI影像,外周全0值较多
第一步根据四维图像数据data(C,X,Y,Z)生成三维的非零模板nonzero_mask,标示图像中哪些区域是非零的 。不同的模态都有对应的三维数据,产生不同的三维nonzero_mask,而整个四维图像的非零模板为各个模态非零模板的并集。最后调用scipy库的binary_fill_holes函数对生成的nonzero_mask进行填充。
from scipy.ndimage import binary_fill_holes
nonzero_mask = np.zeros(data.shape[1:], dtype=bool)
for c in range(data.shape[0]):
this_mask = data[c] != 0
nonzero_mask = nonzero_mask | this_mask
nonzero_mask = binary_fill_holes(nonzero_mask)第二步根据生成的非零模板,确定用于裁剪的bounding_box大小和位置,在代码中就是要找到nonzero_mask在x,y,z三个坐标轴上值为1的最小坐标值以及最大坐标值。
mask_voxel_coords = np.where(nonzero_mask != outside_value)
minzidx = int(np.min(mask_voxel_coords[0]))
maxzidx = int(np.max(mask_voxel_coords[0])) + 1
minxidx = int(np.min(mask_voxel_coords[1]))
maxxidx = int(np.max(mask_voxel_coords[1])) + 1
minyidx = int(np.min(mask_voxel_coords[2]))
maxyidx = int(np.max(mask_voxel_coords[2])) + 1
bbox = [[minzidx, maxzidx], [minxidx, maxxidx], [minyidx, maxyidx]]第三步就根据bounding_box对该张图像的每个模态依次进行裁剪,然后重新组合在一起。
resizer = (slice(bbox[0][0], bbox[0][1]), slice(bbox[1][0], bbox[1][1]), slice(bbox[2][0], bbox[2][1]))
cropped_data = []
for c in range(data.shape[0]):
cropped = data[c][resizer]
cropped_data.append(cropped[None])
data = np.vstack(cropped_data)
为简化,仅展示二维空间中crop的过程图
在对原始数据裁剪完毕之后,使用同样的bounding box对分割标注seg进行裁剪,具体步骤与上述代码的第三步一致。
注意到,nnUNet在对标注图像seg进行裁剪之后,还额外利用了nonzero_mask的信息,将nonzero_mask区域以外的背景标签值,从0修改为-1。
non_zero_label = -1
seg[(seg == 0) & (nonzero_mask == 0)] = nonzero_label这样一来, seg中值为0和-1的都代表背景, 只是值为0的代表图像中值不为0的背景, 值为-1的代表图像中值为0的背景. 这样做可在后续的处理中,用seg<0迅速指示图像中的nonzero region. 在normalization中, 如果图像尺寸减小了1/4以上,就需要利用这个信息,仅在nonzero region进行normalization。
3.3 重采样Resample
重采样目的是解决在一些三维医学图像数据集中,不同的图像中单个体素voxel所代表的实际空间大小spacing不一致的问题。因为卷积神经网络只在体素空间中进行操作,会忽视掉实际物理空间中大小信息。为了避免这种差异性,需要对不同图像数据在体素空间进行resize,保证不同的图像数据中,每个体素所代表的实际物理空间一致。
具体需要将整个数据集resample到多大的spacing,即目标空间大小target_spacing应该多大呢?nnUNet给出的建议是在大多数时候使用数据集各个图像不同spacing的中值,但是在各向异性(最大坐标上的spacing÷最小坐标上的spacing>3)的数据集中,取数据集10%分位点的spacing值作为spacing最大坐标的目标空间大小会是更好的选择。重采样的步骤可以简单分成3步。
第一步是确定重采样的目标空间大小。在之前数据格式转换的时候,每个数据的spacing信息存储在对应的pickle文件中,需要依次进行读取,然后一起存放在一个列表spacings当中。之后调用numpy中函数统计每个维度spacing的中值即可。
接下来根据中值spacing进行判断,数据集是否存在各向异性的问题。nnUNet设定的判断标准是,中值spacing中三个维度,是否有一个维度spacing大于另一个维度spacing的3倍,并且,该维度的中值size小于另一个维度中值size的1/3。如果存在各向异性,对spacing特别大的维度,取数据集中该维度spacing值的10%分位点作为该维度的目标空间大小。
anisotropy_threshold = 3
worst_spacing_axis = np.argmax(target)
other_axes = [i for i in range(len(target)) if i != worst_spacing_axis]
other_spacings = [target[i] for i in other_axes]
has_aniso_spacing = target[worst_spacing_axis] > (anisotropy_threshold * min(other_spacings))
has_aniso_voxels = target_size[worst_spacing_axis] * self.anisotropy_threshold < min(other_sizes)
if has_aniso_spacing and has_aniso_voxels:
spacings_of_that_axis = np.vstack(spacings)[:, worst_spacing_axis]
target_spacing_of_that_axis = np.percentile(spacings_of_that_axis, 10)
# don't let the spacing of that axis get higher than the other axes
if target_spacing_of_that_axis < min(other_spacings):
target_spacing_of_that_axis = max(min(other_spacings), target_spacing_of_that_axis) + 1e-5
target[worst_spacing_axis] = target_spacing_of_that_axis第二步根据target_spacing确定每张图像的目标尺寸。每张图像, spacing和shape之间的乘积为一个定值,代表整个图像在实际空间中的大小。因此可以得到如下关系:
new_shape = np.round(((np.array(original_spacing) / np.array(target_spacing)).astype(float) * shape)).astype(int)第三步调用skimage库中的reisze函数对每张图像进行resize即可, 但在nnUNet中会根据图像是否存在各向异性进行不同的resize策略。如果不存在各向异性,对整个三维图像进行3阶spline插值即可。如果图像存在各向异性,设spacing大的维度为z轴,则仅在图像的xy平面进行3阶spline插值,而在z轴采用最近邻插值。而对于分割的标注图像,无论各向异性与否, 在三个维度上都采用最近邻插值。下面代码中,用do_seperate_z表示是否存在各向异性,用axis表示各向异性图像中spacing最大的轴。
from skimage.transform import resize
if do_separate_z:
if axis == 0:
new_shape_2d = new_shape[1:]
elif axis == 1:
new_shape_2d = new_shape[[0, 2]]
else:
new_shape_2d = new_shape[:-1]
reshaped_final_data = []
for c in range(data.shape[0]):
reshaped_data = []
for slice_id in range(shape[axis]):
if axis == 0:
reshaped_data.append(resize(data[c, slice_id], new_shape_2d, order=3))
elif axis == 1:
reshaped_data.append(resize(data[c, :, slice_id], new_shape_2d, order=3))
else:
reshaped_data.append(resize(data[c, :, :, slice_id], new_shape_2d, order=3))
if shape[axis] != new_shape[axis]:
# The following few lines are blatantly copied and modified from sklearn's resize()
rows, cols, dim = new_shape[0], new_shape[1], new_shape[2]
orig_rows, orig_cols, orig_dim = reshaped_data.shape
row_scale = float(orig_rows) / rows
col_scale = float(orig_cols) / cols
dim_scale = float(orig_dim) / dim
map_rows, map_cols, map_dims = np.mgrid[:rows, :cols, :dim]
map_rows = row_scale * (map_rows + 0.5) - 0.5
map_cols = col_scale * (map_cols + 0.5) - 0.5
map_dims = dim_scale * (map_dims + 0.5) - 0.5
coord_map = np.array([map_rows, map_cols, map_dims])
reshaped_final_data.append(map_coordinates(reshaped_data, coord_map, order=0, cval=cval,
mode='nearest')[None])
else:
reshaped = []
for c in range(data.shape[0]):
reshaped.append(resize(data[c], new_shape, order=3)[None])
reshaped_final_data = np.vstack(reshaped)
reshaped_seg = resize(seg, new_shape, order=0)3.4 标准化Normalization
对图像进行标准化normalization的预处理,不仅在医学图像中需要,在自然图像中也是必备步骤。Normalization的目的是让训练集中每张图像的灰度值都能具有相同的分布。
nnUNet提供了两种normalization的策略,一种单独针对CT图像,一种应用于其它非CT图像。相同的地方是都使用z-scoring(即减去均值除以标准差)。不同的地方有两点。第一点,CT图像做normalization用的是整个训练集前景的均值和标准差,而非CT图像normalization时仅使用单张图像的灰度信息计算均值和方差。策略不同原因在于,CT图像中,强度信息HU值能反映不同组织的物理性质,用整个训练集前景的统计信息,可以有效的利用HU值的额外信息。第二点,CT图像中经常会有异常大的孤立值和异常小的孤立值,需要先将图像HU值clip到前景HU值[0.5, 99.5]百分比范围之间,而非CT图像没有clip的必要。
值得注意的一点是,如果在crop阶段图像大小减小了1/4以上的时候,nnUNet会选择仅在nonzero region进行normalization。
先介绍CT图像的normalization,过程可以分为2步。
第一步是收集整个CT影像训练集前景的统计信息。假设c代表CT所在的模态,data[c]代表CT图像的三维数据。seg是存放分割标注信息的三维数组,根据crop步骤中的处理, 标注值为-1代表0值背景,标注值为0代表非0值的背景,而大于0代表不同的前景标签。nnUNet为了简便计算,对每张图像仅采样1/10的前景体素用于统计,存储在voxels列表中。
mask = seg > 0 # 生成前景mask
voxels = list(data[c][mask][::10])通过对训练集中每张训练数据的遍历,将采样到的前景体素列表voxels拼接在一块,可以命名为voxels_all。
第二步调用numpy中的函数统计整个训练集前景的均值,标准差,0.5%分位HU值,99.5%分位HU值,并利用这些统计信息对每张图像进行clip以及z-scoring。代码中用use_nonzero_mask指示是否只在nonzero区域进行normalization.
```clike
mean = np.mean(voxels_all)
std = np.std(voxels_all)
percentile_99_5 = np.percentile(voxels_all, 99.5)
percentile_00_5 = np.percentile(voxels_all, 00.5)
data[c] = np.clip(data[c], percentile_00_5, percentile_99_5)
data[c] = (data[c] - mean) / std
if use_nonzero_mask[c]:
data[c][seg < 0] = 0 # seg<0代表图像里值为0的背景
而非CT图像的normalization相对简单一些,只需1步,每张三维图像只利用自身均值和标准差进行z-scoring即可。
```clike
if use_nonzero_mask[c}:
mask = seg >= 0 # 图像中非0区域
data[c][mask] = (data[c][mask] - data[c][mask].mean()) / data[c][mask].std()
else:
data[c] = (data[c] - data[c].mean()) / data[c].std()4 后处理
后处理会使用一个生物医学影像的先验知识:医学影像中常常只有1个主体目标,比如一个人只有1个心脏左心室。在这个先验知识的指导下,后处理会尝试仅保留五折交叉验证后选择的2个模型的重叠的最大连通域,再进行测试。如果测试效果好,就保留此后处理;反之则不保留。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6080次2021-06-23 15:25:25
-
浏览量:7388次2021-05-24 15:13:24
-
浏览量:5668次2021-04-27 16:30:07
-
浏览量:11636次2021-06-09 12:09:57
-
浏览量:6143次2021-06-22 16:53:40
-
浏览量:10428次2021-04-20 15:42:26
-
浏览量:6272次2021-08-09 16:11:19
-
浏览量:6193次2021-04-20 15:43:03
-
浏览量:6601次2021-06-16 11:22:18
-
浏览量:5347次2021-04-21 17:05:28
-
浏览量:5528次2021-08-02 09:33:43
-
浏览量:5376次2021-04-21 17:05:56
-
浏览量:13907次2021-05-12 12:35:30
-
2023-01-13 11:35:13
-
浏览量:8094次2021-06-15 10:28:29
-
浏览量:30261次2021-01-08 11:33:04
-
浏览量:5801次2021-05-15 23:39:10
-
浏览量:35757次2021-05-04 20:18:49
-
浏览量:15006次2021-01-08 03:03:13

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
