

资讯文章
谷歌的通用语音模型将自动语音识别扩展到100多种语言

谷歌上个月在巴黎发布的巴德聊天机器人(Bard)令人失望,但至少可以这么说,还不要把这家科技巨头排除在人工智能语言模型的竞赛之外。谷歌本周有所反弹,在去年11月启动的“1000种语言计划”项目上迈出了一大步,该计划旨在建立一个支持世界上1000种最常用语言的通用模型。
在新论文谷歌USM:扩展100种语言之外的自动语音识别中,谷歌团队“探索了语言扩展的前沿”,提出了一个可扩展的多语言ASR(自动语音识别)自我监督训练框架,扩展到数百种语言。他们所得到的通用语音模型(USM)在多语言ASR和语音到文本翻译任务中实现了最先进的性能。

该团队将他们的主要贡献总结如下:
- 我们证明了在 300 种语言上预训练的 USM 可以通过少量监督数据成功适应新语言的 ASR 和 AST(自动语音翻译)任务。
- 我们通过在90k小时的监督数据上微调预训练模型,在73种语言上构建了通用ASR模型。通用ASR模型可以在TPU上高效地进行推理,并且可以在YouTube字幕ASR基准上可靠地转录长达数小时的音频。
- 我们对预训练、嘈杂学生训练、文本注入和模型大小对多语言 ASR 的影响进行了系统研究。
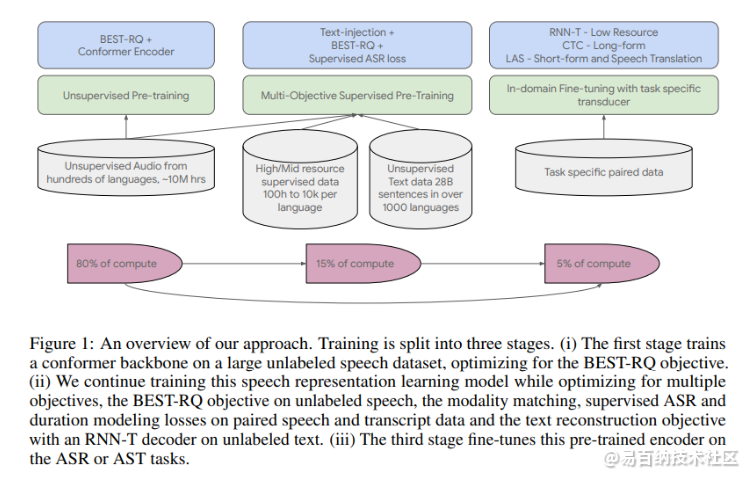
该团队使用谷歌在 2020 年推出的卷积增强变压器 Conformer 作为他们的骨干模型。USM 训练过程在管道中使用 12 万小时的语音和 28 亿句文本,涵盖 300+ 种语言,包括三个步骤:
1) 使用基于 BERT 的语音预训练和随机投影量化器 (BEST-RQ) 在 YT-NTL-U 大型未标记多语言语音数据集上预训练;
2) 应用多目标监督预训练来优化多个目标,使用 RNN-T 解码器对未标记的文本进行优化;
3) 预训练编码器针对下游 ASR 和 AST 任务进行了微调。
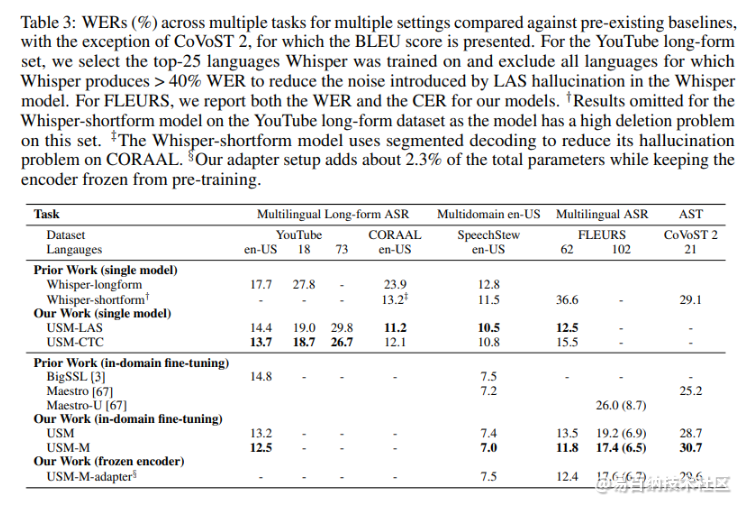
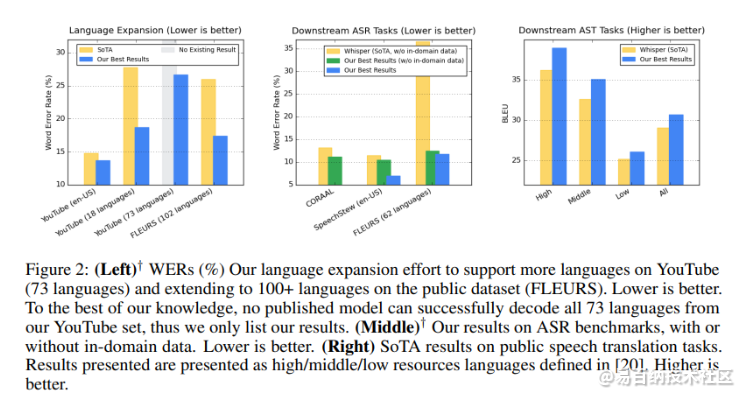
该团队在实证研究中评估了USM在ASR和AST任务上的表现。USM 模型在 102 种语言的 FLEURS 基准测试上实现了最先进的 ASR 结果,并在 2 种语言的 CoVoST-21 语音翻译语料库上实现了 AST 结果。研究人员指出,USM训练过程可以有效地适应新的语言和数据;并将USM的发展视为实现“谷歌组织世界信息并使其普遍可访问的使命”的重要一步。
声明:本文内容由易百纳平台入驻作者撰写,文章观点仅代表作者本人,不代表易百纳立场。如有内容侵权或者其他问题,请联系本站进行删除。
红包
点赞
收藏
评论
打赏
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
评论
0个
手气红包
 暂无数据
暂无数据相关专栏
-
浏览量:1354次2023-02-16 11:18:38
-
浏览量:2342次2019-11-22 09:03:33
-
浏览量:3050次2023-04-23 09:34:59
-
浏览量:2599次2019-10-09 10:35:18
-
浏览量:2813次2018-09-14 14:18:42
-
浏览量:1227次2023-08-29 10:35:17
-
浏览量:1275次2023-03-14 18:33:13
-
浏览量:2667次2018-11-17 15:56:06
-
浏览量:1314次2023-03-03 08:55:07
-
浏览量:2675次2020-06-11 14:27:18
-
浏览量:3771次2020-08-26 17:32:45
-
浏览量:1441次2023-09-11 13:55:15
-
浏览量:3910次2019-07-15 09:57:05
-
浏览量:3200次2020-10-21 09:34:35
-
浏览量:1840次2018-05-21 13:43:38
-
浏览量:4246次2020-10-29 18:05:03
-
浏览量:4529次2019-06-03 09:47:22
-
浏览量:3860次2022-02-15 09:00:27
-
浏览量:2154次2022-01-30 09:00:12
关于作者

tomato
===============
原创615
阅读226.3w
收藏17
点赞24
评论11













切换马甲
上一页
下一页
打赏用户
共 0 位
我要创作
分享技术经验,可获取创作收益
置顶时间设置
结束时间
删除原因
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
打赏作者
tomato
您的支持将鼓励我继续创作!
打赏金额:
¥1
¥5
¥10
¥50
¥100
支付方式:
 微信支付
微信支付
举报反馈
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
发布时间设置
发布时间:
请选择发布时间设置
是否关联周任务-专栏模块
审核失败
失败原因
请选择失败原因
备注
请输入备注



关注公众号
联系我们
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
回顶部
