

【深度学习】图像数据集处理常用方法合集(部分基于pytorch)
【深度学习】图像数据集处理常用方法合集(部分基于pytorch)
1 图像数据集预处理的目的
1.1 灰度图转化
1.2 高斯滤波去除高斯噪声
2 使用双峰法进行图像二值化处理
2.1 图像直方图
2.2 双峰法
3 2d数据转nii格式阶段
4 Pytorch数据预处理:transforms的使用方法
5 其他的transforms处理方法,总结有四大类
5.1 裁剪-Crop
5.2 翻转和旋转——Flip and Rotation
5.3 图像变换
5.4 对transforms操作,使数据增强更灵活1 图像数据集预处理的目的
图像预处理的主要目的是消除图像中无关的信息,恢复有用的真实信息,增强有关信息的可检测性和最大限度地简化数据,从而改进特征抽取、图像分割、匹配和识别的可靠性。以上内容来自百度,接下来是我自己的粗浅的见解,我觉得图像数据的预处理,类似于化学中的提纯的操作,只不过这是一种粗糙的提纯,只能够将一些表面的泥沙等杂物去除,为了以后更精确的提纯作准备。
1.1 灰度图转化
首先简单讲述灰度图和RGB图像,灰度图是单通道图像,他没有色彩,RGB三个分量相等,对于灰度图,我们只需要知道灰度图一般分为256级灰度,灰度的像素在0——255之间,0为黑,255为白,其他的0到255是不同的灰度,对于灰度图像数据,我们还要知道,图像的像素是展开来是一个个像素值组成二维数组当然也可以是列表,例如一张10*10大小的灰度图的像素展开来如下图:(为了计算方便像素值已经进行归一化处理,我们采用的归一化处理是将图像的像素值除以255,变成小数)
RGB红、绿、蓝三个颜色通道每种色各分为256阶亮度,在一种颜色为0时表示此种颜色亮度最弱——而在255时此种颜色最亮。当三色灰度数值相同时,产生不同灰度值的灰色调,即三色灰度都为0时,是最暗的黑色调;三色灰度都为255时,是最亮的白色调。
由于要处理RGB的三色图像与处理灰度图像相比,显然要处理的参数更多更复杂,所以我们要将RGB图转化为灰度图,转化的方法很简单我们直接用Image中函数即可.
1.2 高斯滤波去除高斯噪声
在数字图像中的高斯噪声的主要来源出现在采集期间。 由于不良照明和/或高温引起的传感器噪声,高斯噪声是指它的概率密度函数服从高斯分布(即正态分布)的一类噪声。
在进行高斯滤波是我们只需要使用OpenCV中的cv.GaussianBlur()函数:

2 使用双峰法进行图像二值化处理
2.1 图像直方图
图像直方图是对图像的像素值进行数据统计,灰度图像的直方图中横轴为灰度级(0——256),竖轴为每一个灰度级的像素的个数,这是一张灰度图,它的直方图在下面
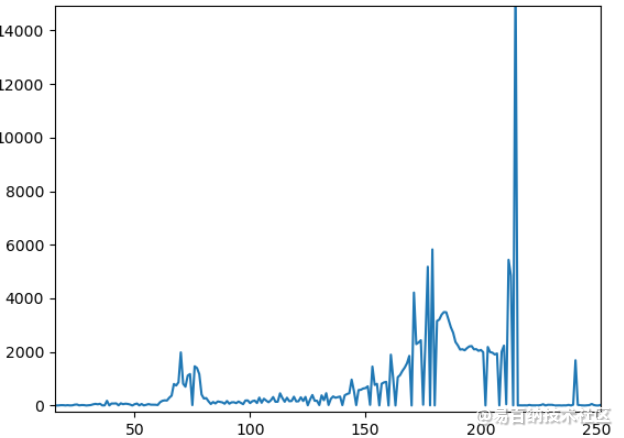
图中的数据显示了图像像素值的分布规律。可以看出上面灰度图中的字符是相对偏向黑色的,在灰度图中对应的x轴坐标50——100这段范围的,其背景对应150以后。
2.2 双峰法
在前面的那张灰度图中,我们想要的是图中的字符数据,我不是背景,我们要进行二值化的也是图中的字符,图像的二值化,就是,在灰度图的像素值归为两个类别,一个为像素值0,一个为255,也就是非黑即白,所以我们想要找到一个阈值,将低于这个阈值的像素值设为0,高于这个阈值的像素值设为255,所谓双峰法就是根据灰度图的直方图来选择阈值,比如我们要选择上面灰度图中的字符,就选择100作为阈值,最后的二值化结果如图;
3 2d数据转nii格式阶段
transform=lambda x: (x == 255).astype(int)
单标签:
import numpy as np
a=[[0,60,120,180,240],[0,0,0,0,0],[0,0,0,0,0],[240,180,120,60,0]]
a=np.array(a)
transform=lambda x: (x == 240).astype(int)
b=transform(a)
print(b)
[[0 0 0 0 1]
[0 0 0 0 0]
[0 0 0 0 0]
[1 0 0 0 0]]多标签:
import numpy as np
a=[[0,60,120,180,240],[0,0,0,0,0],[0,0,0,0,0],[240,180,120,60,0]]
a=np.array(a)
transform=lambda x: (x == 240).astype(int)*1
transform1=lambda x: (x == 180).astype(int)*2
transform2=lambda x: (x == 120).astype(int)*3
transform3=lambda x: (x == 60).astype(int)*4
b=transform(a)+transform1(a)+transform2(a)+transform3(a)
print(b)
[[0 4 3 2 1]
[0 0 0 0 0]
[0 0 0 0 0]
[1 2 3 4 0]]4 Pytorch数据预处理:transforms的使用方法
图像判断,因为得到的CT图片数据集很少,在训练网络的术后准确度很低。但是又很难找到其他数据集。所以在训练网络的时候,我们很关注对图像的预处理操作,并使用了数据增强的方法。
import torchvision.transforms as transforms
import cv2
img_path = "./panda.jpg"
train_transformer = transforms.Compose([
transforms.ToPILImage(),
transforms.Resize(256),
# transforms.RandomResizedCrop(224,scale=(0.5,1.0)),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
##numpy.ndarray
img = cv2.imread(img_path) # 读取图像
img1 = train_transformer(img)输出:
(500, 800, 3)
torch.Size([3, 256, 409])
上面一段代码就是图像预处理的操作。以前在tensorflow的框架内处理起来很麻烦的数据,在这里就几句代码可以搞定了,很爽。大致讲解一下代码。
transforms.Compose函数就是将transforms组合在一起;而每一个transforms都有自己的功能。最终只要使用定义好的train_transformer 就可以按照循序处理transforms的要求的。上面的代码中:
transforms.ToPILImage()是转换数据格式,把数据转换为tensfroms格式。只有转换为tensfroms格式才能进行后面的处理。
transforms.Resize(256)是按照比例把图像最小的一个边长放缩到256,另一边按照相同比例放缩。
transforms.RandomResizedCrop(224,scale=(0.5,1.0))是把图像按照中心随机切割成224正方形大小的图片。
transforms.ToTensor() 转换为tensor格式,这个格式可以直接输入进神经网络了。
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])对像素值进行归一化处理。
5 其他的transforms处理方法,总结有四大类
5.1 裁剪-Crop
中心裁剪:transforms.CenterCrop
随机裁剪:transforms.RandomCrop
随机长宽比裁剪:transforms.RandomResizedCrop
上下左右中心裁剪:transforms.FiveCrop
上下左右中心裁剪后翻转,transforms.TenCrop
5.2 翻转和旋转——Flip and Rotation
依概率p水平翻转:transforms.RandomHorizontalFlip(p=0.5)
依概率p垂直翻转:transforms.RandomVerticalFlip(p=0.5)
随机旋转:transforms.RandomRotation
5.3 图像变换
resize:transforms.Resize
标准化:transforms.Normalize
转为tensor,并归一化至[0-1]:transforms.ToTensor
填充:transforms.Pad
修改亮度、对比度和饱和度:transforms.ColorJitter
转灰度图:transforms.Grayscale
线性变换:transforms.LinearTransformation()
仿射变换:transforms.RandomAffine
依概率p转为灰度图:transforms.RandomGrayscale
将数据转换为PILImage:transforms.ToPILImage
transforms.Lambda:Apply a user-defined lambda as a transform.
5.4 对transforms操作,使数据增强更灵活
transforms.RandomChoice(transforms), 从给定的一系列transforms中选一个进行操作
transforms.RandomApply(transforms, p=0.5),给一个transform加上概率,依概率进行操作
transforms.RandomOrder,将transforms中的操作随机打乱
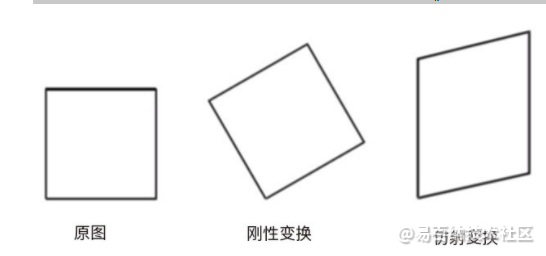
图像的几何变换主要包括:平移、缩放、旋转、仿射、透视等等。图像变换是建立在矩阵运算基础上的,通过矩阵运算可以很快的找到不同图像的对应关系。理解变换的原理需要理解变换的构造方法以及矩阵的运算方法。
图像的几何变换主要分为三类:刚性变换、仿射变换和透视变换,如下图:
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5528次2021-08-02 09:33:43
-
浏览量:17749次2021-07-29 10:22:10
-
浏览量:15070次2021-07-08 09:43:47
-
2023-01-13 11:33:00
-
浏览量:18313次2021-05-31 17:01:39
-
浏览量:5767次2021-08-13 15:39:02
-
浏览量:6697次2021-07-26 17:43:04
-
浏览量:5578次2021-07-26 11:25:51
-
浏览量:1428次2023-09-07 16:22:49
-
浏览量:17273次2021-07-16 12:56:10
-
浏览量:6615次2021-08-03 11:36:18
-
浏览量:5633次2021-08-05 09:21:07
-
浏览量:5761次2021-08-05 09:20:49
-
浏览量:6795次2021-08-03 11:36:37
-
浏览量:104次2023-08-30 20:18:28
-
浏览量:5564次2021-07-26 11:28:05
-
浏览量:6244次2021-08-02 09:34:03
-
浏览量:7316次2021-06-07 09:26:53
-
浏览量:7527次2021-06-18 17:21:06

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
