

深度学习基础:使用TensorFlow 了解overfitting 与underfittin

假设你要想利用机器学习辨识手写文字,在训练时得到的训练误差很低,但是训练完的模型辨识文字的效果却不好,这是什么原因呢?
在这篇文章,我们会用TensorFlow 建立一个模拟函数的模型,透过修改模型的容量与超参数,特意让模型发生过拟合与欠拟合,并观察究竟在何种情况会发上以上两种况。
训练误差与测试误差
首先,我们先来重新温习何谓训练误差与测试误差。在训练模型时,我们会使用损失函数评估预测值与真实值的误差,该误差称作训练误差(training error);在训练完模型后,任一训练资料以外的资料用于训练出的模型所产生的误差称作测试误差(testing error)。
过拟合与欠拟合
假设我们想要训练模型辨识手写文字,因此建立一个多层感知机的模型,在训练时会用训练误差与测试误差评估模型的泛化能力。如果训练误差总是无法降低,预测的准确率很低,我们会称这种情况为欠拟合(underfitting);而如果训练误差很低时,在训练资料的表现很好,但是却在在测试集上无法获得较好的结果,则会称这种情况为过拟合(overfitting)。
接着,我们要来谈谈发生过拟合与欠拟合的两个主要原因:模型容量与训练的资料多寡。
何谓模型容量?
在机器学习的领域中,我们会说容量(capacity)是模型拟合数的能力。通常,越是复杂的模型其容量越高,但是容易造成过拟合。反之,越是简单的模型其容量越低,却容易导致欠拟合。
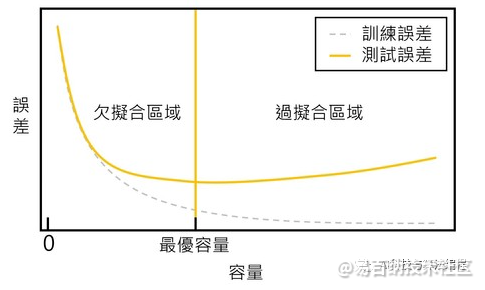
以下的函数是线性回归的模型,其能够拟合的函数不外乎就是线性函数,如果资料成非线性的分布,则线性回归的模型较难拟合资料的规律,因此该模型的容量较低。
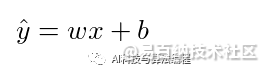
如果是一个9 次方的函数模型,相较于线性回归模型,它较有能力拟合非线性的资料分布,因此该模型的容量较大。
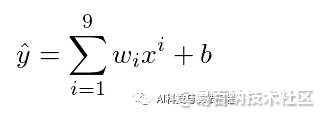
在选择模型时,必须选择适当容量的模型,避免发生过拟合或欠拟合。
训练数据多寡
机器学习的基本条件之一便是数据量,如果想要训练能够辨识手写文字的模型时,每一种文字只有寥寥无几的数据数量,尽管经过长时间的训练,一旦遇到风格非常不同的手写文字,模型便会失准。
因此,如果数据过少,则训练出的模型容易发生过拟合的结果。
模拟过拟合与欠拟合
接着,我们尝试模拟过拟合与欠拟合发生的情况,将使用多项式回归(polynomial regression) 拟合以下函数,用拟合的结果解释过拟合与欠拟合。
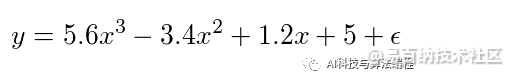
overfitting 与underfitting
首先引入在这个范例中会使用到的套件,我们需要使用numpy 来产生数据,再者,利用TensorFlow 建立多项式回归的模型,学习资料隐藏的规律,最后,将会用matplotlib 视觉化模型拟合的情况。
import numpy as np
import tensorflow as tf
from matplotlib import pyplot as plt产生数据
我们使用numpy 产生200 笔在常态分布中的数值作为features,并将这些数值带入目标函数生成labels,并将features 与labels 各分一半作为训练资料与测试资料。在生成labels 时,我们加入一些噪音资料,让资料的分布更符合现实中的情况。
true_w = [5, 1.2, -3.4, 5.6]
features = np.random.normal(size=200)
np.random.shuffle(features)
labels = 0
for i in range(4):
labels += true_w[i] * np.power(features, i)
labels += np.random.normal(scale=0.1, size=labels.size)
training_features, testing_features = features[:100], features[100:]
training_labels, testing_labels = labels[:100], labels[100:]建立模型
欲拟合的函数共有两个变数y与x,所以我们要定义两个tf.placeholder,在之后训练时传入资料。
在定义运算时,首先定义多项式回归模型的最高次方e,并由e动态决定系数w的个数;接着,将运算各别加入串列中,最后再经由tf.add_n一次性地加入所有的运算至net。
e = 4 # 多項式回歸模型的最高次方
x = tf.placeholder(tf.float32)
y = tf.placeholder(tf.float32)
w = tf.Variable([1.0] * e, tf.float32)
calculations = []
for i in range(e):
calculations.append(tf.multiply(w[i], tf.pow(x, i)))
net = tf.add_n(calculations)设定超参数
接下来,我们有三个超参数要设定,分别是learning rate、batch size、epochs,以上三个超参数你都可以尝试调整成不同的数值,观察模型拟合函数的结果。
learning_rate = 0.01
batch_size = 10
epochs = 100设定损失函数与优化器
在这个范例中,使用均方误差(Mean Squared Error, MSE) 作为损失函数,并使用梯度下降法优化参数。
loss = tf.reduce_mean(tf.pow(net - y, 2))
train = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)建立迭代器
tf.data.Dataset在TensorFlow 1.4的版本中,从tf.contrib移至核心API,是一个可以用来迭代资料的函式库。我们使用tf.data.Dataset作为迭代资料的工具。
dataset = tf.data.Dataset.from_tensor_slices((training_features, training_labels))
dataset = dataset.repeat().batch(10)
iterator = dataset.make_initializable_iterator()
next_data = iterator.get_next()训练模型
在开始训练之前,别忘记要初始化所有的变数以及用来迭代资料的迭代器。我们迭代的次数(epochs) 为100 次,可以尝试调整看看这个超参数,观察会发生什么事情。
train_loss = []
test_loss = []
init = [tf.global_variables_initializer(), iterator.initializer]
saver = tf.train.Saver()
with tf.Session() as sess:
sess.run(init)
for i in range(epochs):
for _ in range(10):
batch_x, batch_y = sess.run(next_data)
sess.run([train, loss], feed_dict={
x: batch_x,
y: batch_y
})
trloss = sess.run(loss, feed_dict={
x: training_features,
y: training_labels
})
train_loss.append(np.mean(trloss))
teloss = sess.run(loss, feed_dict={
x: testing_features,
y: testing_labels
})
test_loss.append(np.mean(teloss))
saver.save(sess, './model{}.ckpt'.format(e))因为我们使用with-as开启Session,所以在with-as里面的程式码结束后,Session会自动关闭。如果你是初学者,可能在训练时会发现,一旦再重新开启一个Session,此时原本训练好的参数都不见了,所以我们在训练完模型时,必须要保存模型的参数。
保存模型的参数可以使用tf.train.Saver(),所有在计算图中的资讯都会被储存在checkpoint (.ckpt档)中,当我们再次启动Session时,可以载入checkpoint回复之前的模型参数与状态。
视觉化模型拟合函数
首先载入模型参数与状态,接着用matplotlib 视觉化模型拟合函数的结果。我们分别视觉化2 次多项式模型、3 次多项式模型与4 次多项式模型和真实资料拟合的状况。
with tf.Session() as sess:
saver.restore(sess, './model{}.ckpt'.format(i))
plt.figure(figsize=(15, 4.5))
plt.subplots_adjust(bottom=0.15)
plt.subplot(121)
plt.xlabel('x')
plt.ylabel('y')
plt.scatter(features, labels, 5)
order = np.argsort(testing_features)
order_features = testing_features[order]
test_prediction = sess.run(net, feed_dict={
x: order_features})
plt.plot(order_features, test_prediction, 'r')
plt.subplot(122)
plt.xlabel('epochs')
plt.ylabel('loss')
plt.semilogy(range(1, epochs+1), train_loss, label='train')
plt.semilogy(range(1, epochs+1), test_loss, label='test', linestyle='--')
plt.legend(loc='upper right')
plt.savefig('{}{}.jpg'.format(e, i), dpi=300, bbox_inches='tight')欠拟合(underfitting)
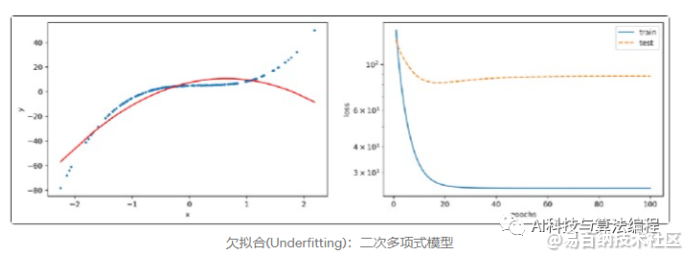
我们视觉化2次多项式模型拟合函数的结果,发现的容量过低的模型不易拟合函数;再从右图可以看到训练误差与测试误差都没有收敛,所以我们可以判定模型发生了欠拟合。当模型欠拟合时,解决方法是增加模型的容量,就可能可以解决欠拟合。
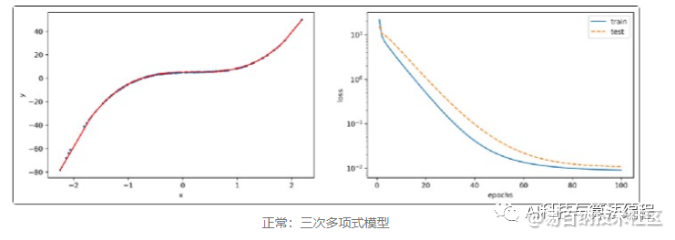
正常拟合
接下来我们看到三次多项式的模型可以几乎很完美地拟合函式,从右图看到训练误差与测试误差非常地接近,而且随着迭代次数增加,模型慢慢地收敛,选择适当的模型可以顺利地拟合函数。
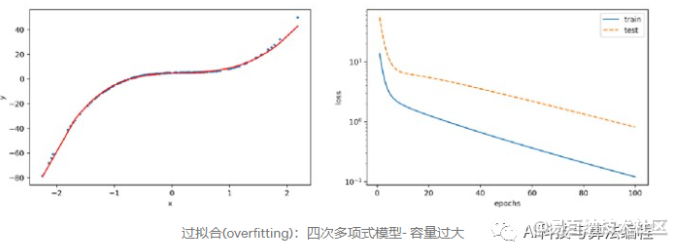
过拟合(overfitting)
容量大于实际上需要解决的问题时,容易发生过拟合的问题。以下的例子是四次多项式的模型,虽然模型随着迭代增加训练误差越来越小,但是训练误差与测试误差仍相差一段距离,可以判断该模型发生了过拟合的问题。
另外一种会发生过拟合的情况是训练资料不足,我们刻意调整训练资料的数量至只有10 笔,当我们利用三次多项式拟合函数时,模型会发生过拟合。

从这篇文章的例子中,你们会发现模型的容量与资料量的多寡皆会影响训练的结果,所以在训练模型前必须收集足够的资料与选择适当的模型,借此避免过拟合与欠拟合。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6618次2021-05-17 16:52:58
-
浏览量:1242次2023-07-20 17:45:54
-
浏览量:1099次2023-08-28 09:56:42
-
2023-01-12 11:47:40
-
浏览量:1280次2023-07-05 10:15:58
-
浏览量:1075次2023-09-28 11:19:15
-
浏览量:1742次2019-12-09 10:34:06
-
浏览量:6770次2021-07-30 10:33:41
-
浏览量:5112次2021-05-18 15:15:50
-
浏览量:1863次2024-02-06 11:56:53
-
浏览量:1574次2023-09-08 10:47:07
-
浏览量:1408次2023-02-13 15:29:10
-
浏览量:1249次2024-01-26 10:04:32
-
浏览量:1888次2023-07-22 09:54:51
-
浏览量:1222次2023-09-18 15:02:26
-
浏览量:2174次2023-02-13 10:31:50
-
浏览量:8519次2021-05-06 12:40:38
-
浏览量:4804次2021-04-14 16:23:03
-
浏览量:179次2023-08-23 10:15:21






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
圈圈

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
