

了解和调试深度学习模型:探索 AI 可解释性方法

关键要点
- 深度学习模型可能非常复杂,理解其内部可能具有挑战性。
- 有几种方法可以在机器学习中提供可解释性
- 为了确保这些自动化系统的可靠性,可以使用可解释性工具来提供对模型决策的洞察力
- 与模型无关的可解释性工具,这些工具是跨模型的模块化工具,可用于与他人共享模型结果,以提供透明度并使用户能够对其模型充满信心
- 没有单一的“正确”方法来解释深度学习模型
深度学习模型可能非常复杂,了解其内部可能具有挑战性。如果用户了解模型如何做出决策,他们将更加信任这些模型。可解释性是一个不断发展的研究领域,旨在了解深度学习模型的工作原理。在本文中,我将讨论深度学习中解释方法的现状。我还将讨论不同方法的优点和局限性,并展示如何使用可解释性来提高深度学习模型的可靠性。
未来,机器学习可用于自动化人类执行的日常任务,包括回答客户服务查询或处理数据。为了确保这些自动化系统的可靠性,可以使用可解释性工具来提供对模型决策的洞察力。与模型无关的可解释性工具,这些工具是跨模型模块化的,可用于与他人共享模型结果,以提供透明度并使用户能够对其模型充满信心。
可解释性方法
ML 可解释性是指用户解释 ML 系统做出的决策的能力。这包括了解输入、模型和输出之间的关系。可解释性增加了模型的信心,减少了偏差,并确保模型合规且合乎道德。有几种方法可以在机器学习中提供可解释性,包括:
- 特征可解释性:此方法涉及可视化模型已学习的特征,以了解它正在学习的内容。特征可解释性可以帮助识别深度学习模型中最重要的特征,但如果它不基于基础模型,则可能并不总是可靠的。
- 激活最大化:这种方法涉及最大化某个神经元或层的激活,以了解模型正在学习的内容。在某些情况下,此方法可用于可视化网络组件的贡献,但根据用例的不同,结果可能并不总是人类可以理解的。
- 显著性图:此方法涉及创建模型输出的热图,以了解输入的哪些部分最重要。显著性图的一个缺点可能是它们并不总是能够提供有关不同特征之间关系的信息。
- 模型蒸馏:这种方法将复杂的模型提炼成更简单的模型(例如,决策树),同时试图保持原始模型的准确性。由于较小的模型可能被视为代理模型,因此它可能与原始模型不具有完全相同的基础结构。
- 局部可解释模型不可知解释:局部可解释模型不可知解释(LIME)的目的是通过创建忠实于原始的可解释模型来解释复杂模型。为此,LIME 通过将线性模型拟合到感兴趣的预测附近的训练数据来创建可解释的模型。然后使用线性模型来解释原始模型的预测。LIME 可能只为单个实例提供解释,而不为模型的整体行为提供解释。
- Shapley 值:Shapley 值可用于确定每个输入变量的重要性,以及哪些输入变量对模型输出的影响最大。这对于选择要包含在模型中的输入变量以及调整模型的参数以优化其性能非常有用。Shapley 值可能需要大量的计算时间,这意味着通常在现实世界的问题中确定近似解。
为了更好地理解深度学习模型如何做出决策,接下来我们将更详细地探讨其中的一些方法。Shapley值和LIME是深度学习可解释性的两个强大工具。我们将查看这些示例,因为查看可视化表示可能有助于使我们和我们未来的受众更容易理解这些概念。它还可以帮助您了解自己实践中的潜在应用。
用例 1:LIME
《局部可解释模型不可知的解释》于 2016 年首次发布,它使用局部线性近似来帮助理解黑盒模型的内部功能。该算法通过学习给定预测的稀疏线性模型来工作。这使用户能够深入了解模型的工作原理以及进行某些预测的原因。LIME 还可用于检测和纠正模型偏差,并识别模型表现不佳的区域。通过了解深度学习模型的行为,LIME 可以帮助您提高模型的准确性和鲁棒性。
利用可理解的代理模型是 LIME 的主要原则。例如,文本分类器可能使用单词嵌入,可解释的表示形式可能是表示单词是否存在的二进制向量。该算法涉及从一组潜在可解释的模型中选择一个理想的解释模型,以使模型尽可能简单,同时保持与原始模型的相似性。通过使用实例 X 的扰动找到最 佳解决方案。该技术使用采样和与模型无关的方法来减少局部感知损失。
让我们看一个应用于《盗梦空间》的 LIME 示例,其中包含猫和狗的图像。使用以下示例图像:
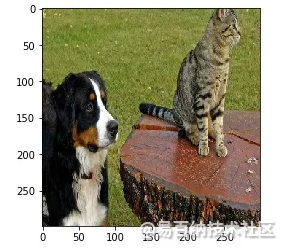
图1.猫和狗的形象
我们可以检索图像的前 5 个预测:
images = transform_img_fn(['dogs.jpg'])
# I'm dividing by 2 and adding 0.5 because of how this Inception represents images
plt.imshow(images[0] / 2 + 0.5)
preds = predict_fn(images)
for x in preds.argsort()[0][-5:]:
print x, names[x], preds[0,x]286 Egyptian cat 0.000892741242 EntleBucher 0.0163564239 Greater Swiss Mountain dog 0.0171362241 Appenzeller 0.0393639240 Bernese mountain dog 0.829222看看有助于预测伯尔尼山地犬的特征(在本例中为像素)可能会很有趣。在这种情况下,我们可以看到狗的脸对其预测有很大贡献。
from skimage.segmentation import mark_boundaries
temp, mask = explanation.get_image_and_mask(240, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))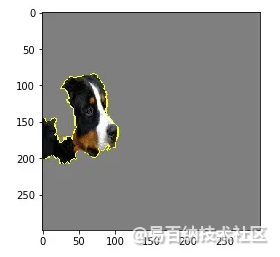
图2.像素有助于狗的预测
也可以看到负面贡献的特征或像素:
temp, mask = explanation.get_image_and_mask(240, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))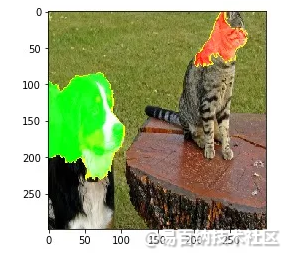
图3.狗的正(绿色)和负(红色)贡献
正如我们所看到的,猫的脸对伯尔尼山犬的预测产生了负面影响。现在让我们来看看哪些特征对埃及猫的特征有积极贡献。
temp, mask = explanation.get_image_and_mask(286, positive_only=True, num_features=5, hide_rest=True)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))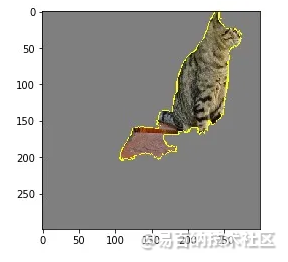
图4.有助于猫预测的像素
此外,我们可以看到伯尔尼山犬的脸对埃及猫的预测有负面影响。
temp, mask = explanation.get_image_and_mask(286, positive_only=False, num_features=10, hide_rest=False)
plt.imshow(mark_boundaries(temp / 2 + 0.5, mask))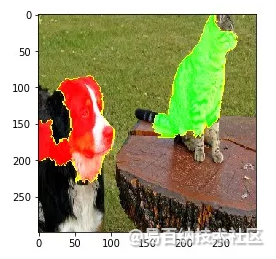
图5.猫的正(绿色)和负(红色)贡献
如前所述,与其他方法一样,LIME也有局限性和缺点。底层模型的“黑匣子”性质使得使用可解释的表示来解释某些行为变得困难。使用稀疏线性模型的决定也本质上意味着所提供的解释可能无法准确反映非线性模型(例如,高度非线性模型)所做的预测。解决此问题的一种方法是使用忠实度估计从针对特定问题上下文定制的一组多个选项中选择合适的可解释模型类。
用例 2:沙普利价值观
Shapley 值是一种独立于模型的方法,供用户描述模型中特征的重要性。它们解释了单个特征对整个模型预测的影响。深度学习模型通常包含多层神经元,使用这种方法可能无法提供描述深度学习模型中神经元之间复杂相互作用的有效方法。这种方法的另一个权衡是,它需要大量的样本来计算精确的Shapley值。对于某些深度学习模型,这可能很难实现。
通过测量训练模型中每个特征的重要性,Shapley 值提供了一种解释机器学习中非线性模型预测的方法。要计算 Shapley 值,将在从输入数据中删除特征的情况下运行模拟,并对每个模拟进行预测。然后,将特征的 Shapley 值计算为使用和不使用该特征所做预测的平均差值。它们可用于深入了解计算功能的贡献以及每个功能对模型性能的影响。
让我们看一个卷积神经网络上的 Shapley 值示例。我们可以使用 SHAP 库来生成 Shapley 值:
# select background for shap
background = x_train[np.random.choice(x_train.shape[0], 1000, replace=False)]# DeepExplainer to explain predictions of the model
explainer = shap.DeepExplainer(model, background)# compute shap values
shap_values = explainer.shap_values(x_test_each_class)
# visualize SHAP values
plot_actual_predicted(images_dict, predicted_class)
print()
shap.image_plot(shap_values, x_test_each_class * 255)底层图像上沙普利值的可视化看起来类似于
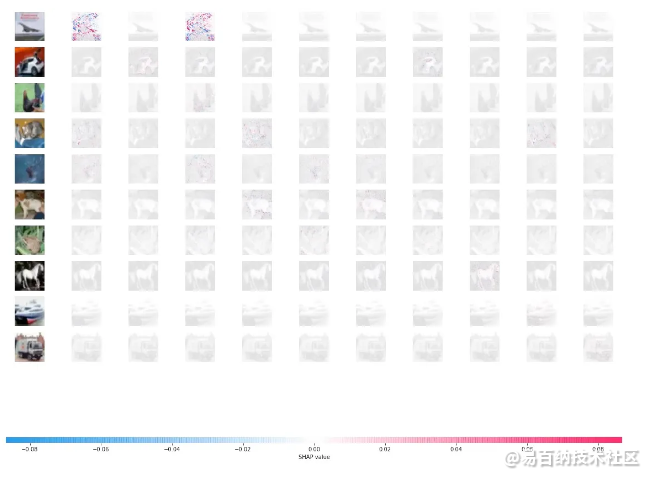
图6.沙普利值的可视化
其中红色像素表示较高的值。Shapley 值,对将图像分类为类有积极贡献,其中蓝色像素表示较低的值 Shapley 值对将图像分类为类产生负面影响 这种类型的可视化使我们能够看到像素组如何为单个解决方案做出贡献,并允许我们在模型中寻找偏差, 调整我们的培训流程以解决任何潜在问题。
如前所述,Shapley 值与其他方法一样具有局限性。它们可能需要大量的计算时间,这意味着通常为现实世界的问题确定近似解决方案。与其他基于排列的解释方法一样,Shapley 值忽略特征依赖性,有时也可能提供无意的解释。因此,Shapley 值可能会被误解,确保偏差不被隐藏非常重要。
结论
未来,机器学习可用于自动化人类执行的日常任务,包括回答客户服务查询或处理数据。为了确保这些自动化系统的可靠性,可以使用可解释性工具来提供对模型决策的洞察力。与模型无关的可解释性工具,这些工具是跨模型模块化的,可用于与他人共享模型结果,以提供透明度并使用户能够对其模型充满信心。
LIME 和 Shapley 值是解释深度学习模型结果的两种方法。这两种方法都提供有关模型如何得出其结果的信息。LIME(局部可解释模型不可知解释)和Shapley值(以数学家Lloyd Shapley命名)是两种可用于描述深度学习模型决策过程的方法。这两种方法都旨在通过分析每个输入特征的贡献来解释深度学习模型的预测。这两种方法之间的主要区别在于 LIME 是一种与模型无关的方法。也就是说,它可以用于任何类型的模型,但 Shapley 值仅限于基于特征线性组合的模型。此外,LIME 的计算效率高于他的 Shapley 值,对于复杂模型来说,Shapley 值的计算成本可能很高。
正如我们所看到的,可解释性是一个不断增长的研究领域,旨在了解深度学习模型的工作原理。不同的可解释性方法具有不同的优点和局限性。可解释性可用于提高深度学习模型的可靠性。一些可解释性评估方法比其他方法更昂贵或更耗时。没有单一的“正确”方法来解释深度学习模型。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2001次2023-03-01 13:44:37
-
浏览量:1450次2023-06-02 17:41:27
-
浏览量:197次2023-08-15 22:50:27
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:2344次2020-01-08 09:25:44
-
浏览量:353次2023-07-24 11:00:24
-
浏览量:775次2023-06-08 10:35:09
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:189次2023-07-30 17:57:28
-
浏览量:1510次2023-03-20 15:23:45
-
浏览量:270次2023-07-30 18:35:03
-
浏览量:7387次2021-05-24 15:13:24
-
浏览量:2706次2020-07-03 14:29:26
-
浏览量:6447次2021-06-15 11:49:53
-
浏览量:5596次2021-04-21 17:06:33
-
浏览量:6794次2021-08-03 11:36:37
-
浏览量:174次2023-08-16 18:28:43
-
浏览量:216次2023-08-03 15:58:40
-
浏览量:5114次2021-05-18 15:15:50






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
艾

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
