

海思 AI 芯片 (Hi3559A V100) 算法开发(三) 在 PC 仿真库使用 YOLOv3 进行图片目标检测以及 NMS、YOLO 讲解

摘要
经过上一篇文章,大家编译运行 PC 仿真后,可能觉得有点迷惘,实际上你已经在后台完成了图像识别,保存结果,绘制识别框等一系列过程。这篇文章就教教大家怎么看识别的结果已经如何手动将识别框绘制出来。并且讲解 NMS 和 YOLO 的原理
仿真代码浅析
为了方便实际操作,这篇文章使用 VS 来快速运行,我觉得 vs 运行比 Ruyi 稍微快一点
为了速度再快一点,我们修改我们要运行的文件夹下的 nnie_sim.ini 中 cuda 的值,让他启动 GPU 加速
点开 nnie_sim.ini 文件
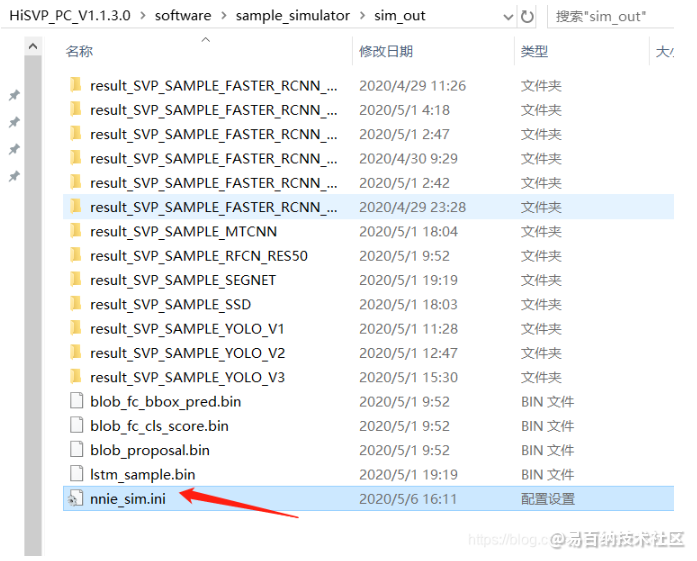
修改如下
#===== CONFIG =====
[LAYER_LINEAR_PRINT_EN]
0
[CUDA_CALC_EN]
1
[OPEN_INSTSIM]
0
[OPEN_PERFSIM]
0
即可启用 CUDA 加速运算,但如果你没有相关的 CUDA 驱动程序,你可能还需要单独下载,百度一下即可,这里不多废话
好了,前期配置到这里就结束了。
接下来我们点开 VS 工程文件

右键选取第一个项目作为启动项目


截取一段成功运行的 log 给大家参考一下

其中要是 CUDA 运行成功了,这里也会有这样的标识

要是出现以上两项,说明你幸运的成功了。但我们还要找到我们的运行结果
数据的输入在代码中就可以找到
点击我们保留的模型代码 Ctrl + 鼠标左键

再进入该函数
我们就可以看到以下内容

首先,以下是我们的 YOLOv3 定位用的 TXT 文件
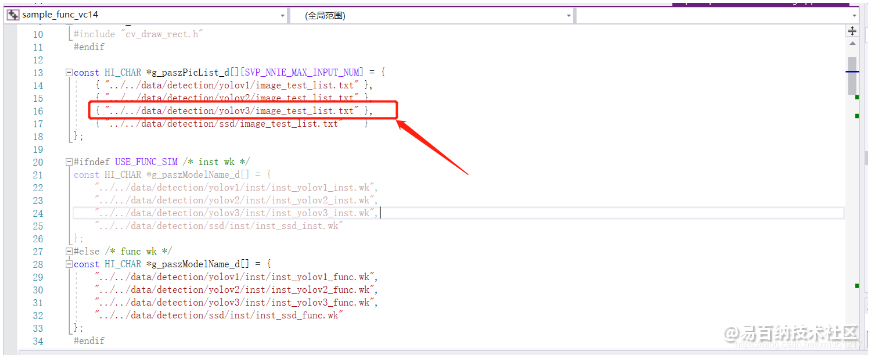
待识别的输入图像设置如下所示。 对应yolo版本的路径中有image_test_list.txt来指定一个或多个输入图像的路径和文件名称

(BGR 文件为图像的 RGB 的颠倒顺序的文件)
以下的两栏为算法的权值文件,上面的为 指令级 wk 文件,下面的为 功能仿真 wk 文件

我们这里用的就是下面的那个
最后我们可以找到我们运行的结果,在以下文件夹中

一个是输入图片识别的结果,右边的 txt 是识别框的定位文件
下面我们来看一下定位文件中的内容
第一行是输入的大小
第二行: 识别的图片名 识别到的物品类型 识别的准确率 选框左上角的x坐标 选框左上角的y坐标 以及右下角的 x y 坐标
后面也一样

模型参数修改
模型相关的重要参数我们可以在 SvpSampleYolo.h 文件中找到

前两个参数也很明显,就是图片的宽和长

一共有 80 个识别分类,也就是能识别 80 种物品

当模型尺寸改变时,其他参数也要做相应的改变,比如
#define SVP_SAMPLE_YOLOV3_GRIDNUM_CONV_82 (13)
#define SVP_SAMPLE_YOLOV3_GRIDNUM_CONV_94 (26)
图像卷积后大小的公式
先定义几个参数(向下取整,pooling层可能向上取整)
- 输入图片大小 W*W
- Filter(卷积核)大小F*F
- 步长 Step
- padding(填充)的像素数P,P=1就相当于给图像填充后图像大小为W+1 *W+1
- 输出图片的大小为N * N


识别种类数改变时也得做相应的调整
#define SVP_SAMPLE_YOLOV3_CHANNLENUM (255)
#define SVP_SAMPLE_YOLOV3_CLASSNUM (80)
此外,检测完我们是需要绘制识别框的(NMS:非极大抑制),那识别阈值以上的才会显示识别框,我们该怎么设定这个阈值呢?

一个是每个框的置信阈值,另外一个是两个框之间的iou阈值。
看到这两个参数你可能会有点懵,
那我们先讲解一下什么是 NMS
NMS
先假设有6个矩形框,根据分类器类别分类概率做排序,从小到大分别属于车辆的概率分别为A < B < C < D < E < F 。
(1) 从最大概率矩形框F开始,分别判断A、B、C、D、E与F的重叠度IOU是否大于某个设定的阈值;
(2) 假设B、D与F的重叠度超过阈值,那么就扔掉B、D;并标记第一个矩形框F,是我们保留下来的。
(3) 从剩下的矩形框A、C、E中,选择概率最大的E,然后判断A、C与E的重叠度,重叠度大于一定的阈值,那么就扔掉;并标记E是我们保留下来的第二个矩形框。
(4) 重复这个过程,找到所有被保留下来的矩形框。
通俗易懂的讲解一下上面的参数,
两个框之间的 lou 阈值越大表示很重叠的识别框,准确率小的识别框才会被取消,越小表示有点重叠就会去掉准确率低的识别框
置信阈值虽然听起来挺拗口,实际上就是 是否含有目标的概率,也包含了预测框的准确率
还有一个偏置项的参数,bias,在 cpp 文件中

看到偏置项有读者可能又有点懵了,那我们再讲解一下 YOLO 的算法原理
YOLO
参考论文:(主要)You Only Look Once: Unified, Real-Time Object Detection
YOLO: Unified, Real-Time Object Detection
YOLO9000: Better, Faster, Stronger
Rich feature hierarchies for accurate object detection and semantic segmentation
Fast R-CNN
Towards Real-Time Object Detection with Region Proposal Networks
darknet
简介
将物品检测作为回归问题求解,基于 end-to-end 网络,使用一个单独的网络,作为回归问题求解的话,只需要一次 reference 就可以得到所有信息。泛化能力强。
网络结构
YOLO 有 24 个卷积层 + 2 个全连接层 ,还有一个 fast YOLO 拥有 9 个卷积层 和 2 个全连接层
对于卷积层主要用 11 的卷积来做 channel reduction 。再接 33 的卷积,全连接层和卷积层的激活函数用了 Leaky ReLU 激活函数:max(x,0.1x)。但最后一层用线性激活函数。
计算过程

首先输入的图像为 4484483 ,经过 步长为 2 ,64 个 77 卷积核的卷积,变为 (448-7+0)/2 + 1 == 221.5 ≈ 221,再进行池化操作,(222-2)/2 +1 ==111,我算的结果下一层的输入应该是 111111 的图像大小,不知道为什么YOLO 算的是 112,不知道是否因为他添加了 2 层 padding ,有知道的读者希望可以解惑一下。

网络最后输出为 7 7 30 的张量,这里是把一张图片分为 77 的网格,而 7 7 20 的张量都是复制存储 20 类别在每个网格上的概率,比如就是 7 7 * 1 是这张图每个网格上狗的概率。
紧跟其后的两个张量为 边界框的置信度,两个相乘为类别置信度。最后 8 个是边框的 (x,y,w,h),把 c 分开用于方便计算。这 3- 个元素都是对应一个网格的,翻译过来就是一个网格会产生 30 个值,前 20 个是各个种类的概率值,2个是边界框置信度,后 8 个是边界框的 (x,y,w,h),两组,共 8 个。c 单独抽出。


原理
1) 图片 resize 成 448448 ,并分割为 77 的网格
2) 每个单元格负责检测那些中心点落在格子内的目标,假如某个网格在图片上狗的身体上,则这个网格负责检测狗,每个网格会预测 B 个边界框(bounding box )以及边界框的置信度(confidence score)。置信度包含两个方面,一个是这个边界框含有与目标的可能性大小,二是这个边界框的准确度。

也就是说置信度不但包含了是否含有目标的概率,也包含了预测框的准确率。是两个因子的乘积。
3)边框的大小可以用四个值来表示 (x,y,w,h) x y 是边界框中心点的坐标,以及边界框的长和宽。并且!!中心坐标的预测值是相对每个网格左上角坐标的偏移量,并且单位是相对于单元格大小的,而 w h 是相对于整个图片的宽与高的比例,这样理论上 4 个元素的大小在 0 ~ 1 的范围
4)这样每个网格的预测值实际上包含 5 个元素,(x,y,w,h,c),c 为置信度


中间下面为分类,上面为目标识别
训练
YOLO 的模型训练在它的论文上是这样描述的
1) 使用图像训练集 ImageNet 1000 类的训练数据对初始模型进行训练,训练初始模型的前 20 个卷积层 + 一个 average 池化层 + 一个全连接层,训练图像分辨率 resize 到 224*224
2) 使用步骤一得到的前 20 个卷积的参数来初始化 YOLO 模型前 20 个卷积层的参数,再加上随机初始化的 4 个卷积层和 2 个全连接层,然后用 VOC 20 类标注数据进行 YOLO 模型训练。为提高图像精度,输入的图像分辨率变为 448*448
以上就是简单的训练步骤
YOLO 训练的损失函数采用的是均方差损失函数。但对不同部分采用不同的权重值。先分为两个部分,一个是定位误差一个是分类误差

还有一点,预测时一个网格会有多个边界框,对应一个类别。如果网格内确实存在目标,那么只选择与 ground truth 的 IOU 最大的边界框在负值预测目标。这样会让一个网格对应的边界框专业,识别率更高。但如果单个网格内存在多个目标,就无法识别,这也是 YOLO 的缺点之一。
对于不存在对应目标的边界框,误差只有置信度,没有定位误差。当有对应目标的网格内,才计算分类误差项。
综上所述,误差函数为:

总共有
边界框中心坐标误差 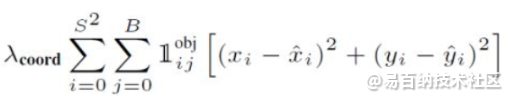
第一个算的是预测的边框中心与实际的边框中心的误差,其中  指的是第 i 个网格存在目标,且该网格的第 j 个边界框负责预测目标。
指的是第 i 个网格存在目标,且该网格的第 j 个边界框负责预测目标。

性能总结
YOLO 相对来说在性能与速度上做了折中,识别率是低于 Fast R-CNN ,定位不是很准确,但对背景的误判率很低
综上所述,YOLO 优点在于算法简洁,且速度快,不容易误判背景,泛化能力强。缺点在于只预测两个边界框,对于小物件识别率不高,这方面可以看 SSD ,Faster R-CNN ,采用多尺度网格和 anchor boxes。在物体的宽高比方面泛化能力低,无法定位不同寻常比例的物品。
TensorFlow 实现代码
定义 YOLO 模型参数;
class Yolo(object):
def __init__(self, weights_file, verbose=True):
self.verbose = verbose
# detection params
self.S = 7 # cell size
self.B = 2 # boxes_per_cell
self.classes = ["aeroplane", "bicycle", "bird", "boat", "bottle",
"bus", "car", "cat", "chair", "cow", "diningtable",
"dog", "horse", "motorbike", "person", "pottedplant",
"sheep", "sofa", "train","tvmonitor"]
self.C = len(self.classes) # number of classes
# offset for box center (top left point of each cell)
self.x_offset = np.transpose(np.reshape(np.array([np.arange(self.S)]*self.S*self.B),
[self.B, self.S, self.S]), [1, 2, 0])
self.y_offset = np.transpose(self.x_offset, [1, 0, 2])
self.threshold = 0.2 # confidence scores threhold
self.iou_threshold = 0.4
# the maximum number of boxes to be selected by non max suppression
self.max_output_size = 10
self.sess = tf.Session()
self._build_net()
self._build_detector()
self._load_weights(weights_file)
模型的主体网络部分,这个网络将输出[batch,7730]的张量:
def _build_net(self):
"""build the network"""
if self.verbose:
print("Start to build the network ...")
self.images = tf.placeholder(tf.float32, [None, 448, 448, 3])
net = self._conv_layer(self.images, 1, 64, 7, 2)
net = self._maxpool_layer(net, 1, 2, 2)
net = self._conv_layer(net, 2, 192, 3, 1)
net = self._maxpool_layer(net, 2, 2, 2)
net = self._conv_layer(net, 3, 128, 1, 1)
net = self._conv_layer(net, 4, 256, 3, 1)
net = self._conv_layer(net, 5, 256, 1, 1)
net = self._conv_layer(net, 6, 512, 3, 1)
net = self._maxpool_layer(net, 6, 2, 2)
net = self._conv_layer(net, 7, 256, 1, 1)
net = self._conv_layer(net, 8, 512, 3, 1)
net = self._conv_layer(net, 9, 256, 1, 1)
net = self._conv_layer(net, 10, 512, 3, 1)
net = self._conv_layer(net, 11, 256, 1, 1)
net = self._conv_layer(net, 12, 512, 3, 1)
net = self._conv_layer(net, 13, 256, 1, 1)
net = self._conv_layer(net, 14, 512, 3, 1)
net = self._conv_layer(net, 15, 512, 1, 1)
net = self._conv_layer(net, 16, 1024, 3, 1)
net = self._maxpool_layer(net, 16, 2, 2)
net = self._conv_layer(net, 17, 512, 1, 1)
net = self._conv_layer(net, 18, 1024, 3, 1)
net = self._conv_layer(net, 19, 512, 1, 1)
net = self._conv_layer(net, 20, 1024, 3, 1)
net = self._conv_layer(net, 21, 1024, 3, 1)
net = self._conv_layer(net, 22, 1024, 3, 2)
net = self._conv_layer(net, 23, 1024, 3, 1)
net = self._conv_layer(net, 24, 1024, 3, 1)
net = self._flatten(net)
net = self._fc_layer(net, 25, 512, activation=leak_relu)
net = self._fc_layer(net, 26, 4096, activation=leak_relu)
net = self._fc_layer(net, 27, self.S*self.S*(self.C+5*self.B))
self.predicts = net
解析网络的预测结果,这里采用了第一种预测策略,即判断预测框类别,再NMS
def _build_detector(self):
"""Interpret the net output and get the predicted boxes"""
# the width and height of orignal image
self.width = tf.placeholder(tf.float32, name="img_w")
self.height = tf.placeholder(tf.float32, name="img_h")
# get class prob, confidence, boxes from net output
idx1 = self.S * self.S * self.C
idx2 = idx1 + self.S * self.S * self.B
# class prediction
class_probs = tf.reshape(self.predicts[0, :idx1], [self.S, self.S, self.C])
# confidence
confs = tf.reshape(self.predicts[0, idx1:idx2], [self.S, self.S, self.B])
# boxes -> (x, y, w, h)
boxes = tf.reshape(self.predicts[0, idx2:], [self.S, self.S, self.B, 4])
# convert the x, y to the coordinates relative to the top left point of the image
# the predictions of w, h are the square root
# multiply the width and height of image
boxes = tf.stack([(boxes[:, :, :, 0] + tf.constant(self.x_offset, dtype=tf.float32)) / self.S * self.width,
(boxes[:, :, :, 1] + tf.constant(self.y_offset, dtype=tf.float32)) / self.S * self.height,
tf.square(boxes[:, :, :, 2]) * self.width,
tf.square(boxes[:, :, :, 3]) * self.height], axis=3)
# class-specific confidence scores [S, S, B, C]
scores = tf.expand_dims(confs, -1) * tf.expand_dims(class_probs, 2)
scores = tf.reshape(scores, [-1, self.C]) # [S*S*B, C]
boxes = tf.reshape(boxes, [-1, 4]) # [S*S*B, 4]
# find each box class, only select the max score
box_classes = tf.argmax(scores, axis=1)
box_class_scores = tf.reduce_max(scores, axis=1)
# filter the boxes by the score threshold
filter_mask = box_class_scores >= self.threshold
scores = tf.boolean_mask(box_class_scores, filter_mask)
boxes = tf.boolean_mask(boxes, filter_mask)
box_classes = tf.boolean_mask(box_classes, filter_mask)
# non max suppression (do not distinguish different classes)
# ref: https://tensorflow.google.cn/api_docs/python/tf/image/non_max_suppression
# box (x, y, w, h) -> box (x1, y1, x2, y2)
_boxes = tf.stack([boxes[:, 0] - 0.5 * boxes[:, 2], boxes[:, 1] - 0.5 * boxes[:, 3],
boxes[:, 0] + 0.5 * boxes[:, 2], boxes[:, 1] + 0.5 * boxes[:, 3]], axis=1)
nms_indices = tf.image.non_max_suppression(_boxes, scores,
self.max_output_size, self.iou_threshold)
self.scores = tf.gather(scores, nms_indices)
self.boxes = tf.gather(boxes, nms_indices)
self.box_classes = tf.gather(box_classes, nms_indices)
详细代码
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1587次2024-01-06 10:44:04
-
浏览量:2897次2024-01-06 10:33:06
-
2024-01-22 16:01:53
-
浏览量:4650次2020-08-05 21:02:35
-
浏览量:3148次2022-01-10 09:00:16
-
浏览量:8106次2018-06-14 23:13:10
-
浏览量:4800次2022-01-04 09:00:18
-
浏览量:4313次2020-07-27 15:19:53
-
浏览量:3663次2020-08-10 09:28:54
-
浏览量:6468次2024-05-22 15:23:49
-
浏览量:2451次2024-01-13 18:14:30
-
浏览量:2314次2023-12-22 14:13:56
-
浏览量:5240次2020-08-05 20:38:05
-
2018-06-18 22:47:22
-
浏览量:3480次2024-03-06 16:15:59
-
浏览量:2710次2024-01-04 17:47:00
-
浏览量:1583次2023-12-20 16:31:10
-
2018-04-04 14:06:53
-
浏览量:4694次2020-08-24 21:15:04

张显显
暂无个性签名~








-
24篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
张显显

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
