

【深度学习】讲一个深度分离卷积结构和空洞卷积的应用
【深度学习】讲一个深度分离卷积结构和空洞卷积的应用
文章目录
前言:看一张图像
1 概述
1.1 正常卷积
1.2 Depth可分离卷积
2 深度可分离卷积的优点
3 空洞(扩张)卷积(Dilated/Atrous Convolution)
4 构建模型
5 U-Net网络更换空洞卷积前言:看一张图像

shape:
(480, 512, 3)
(480, 512)
(480, 512)
(480, 512)1 概述

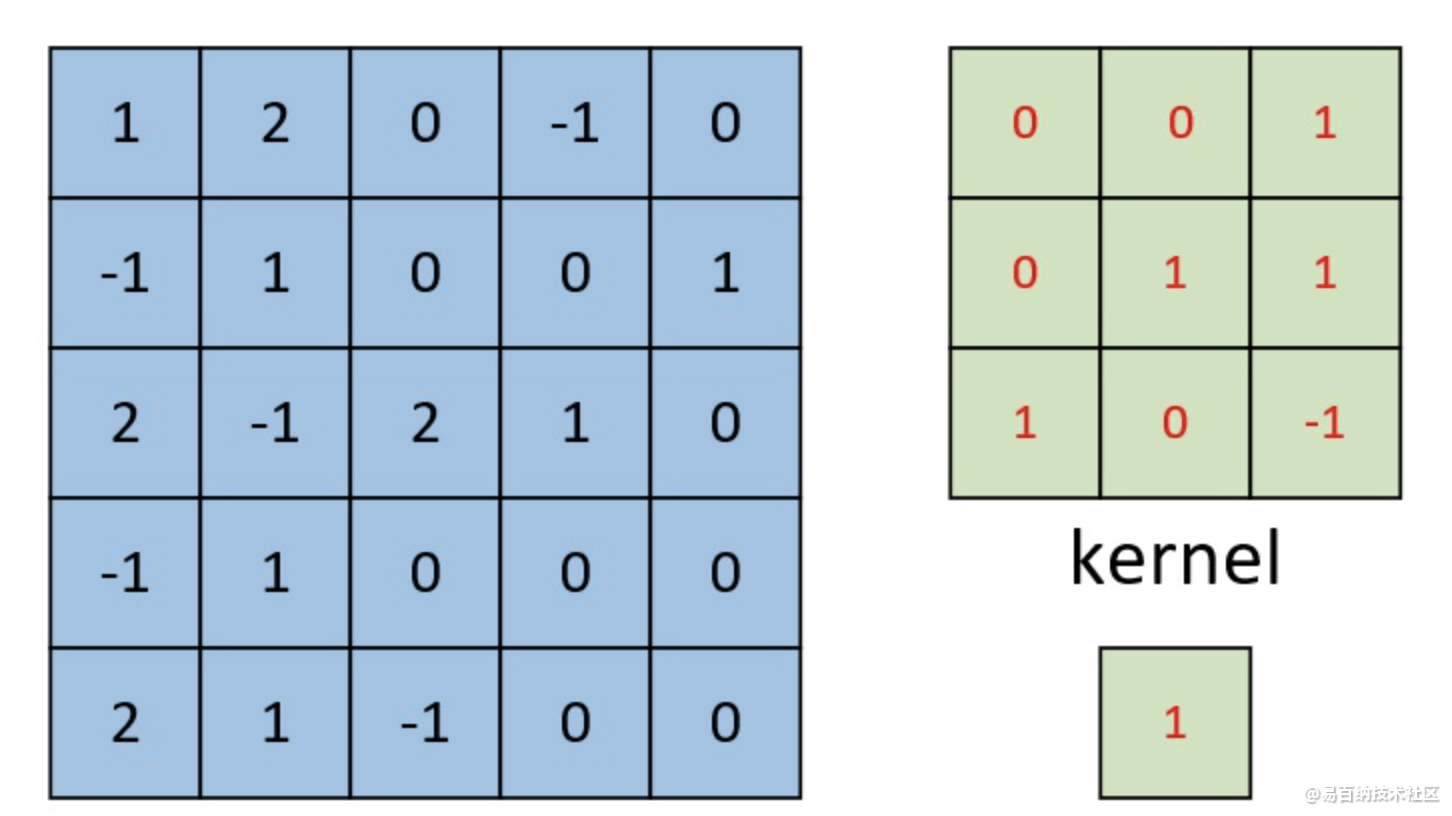
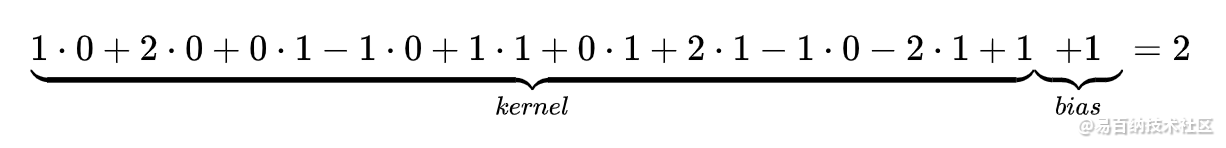
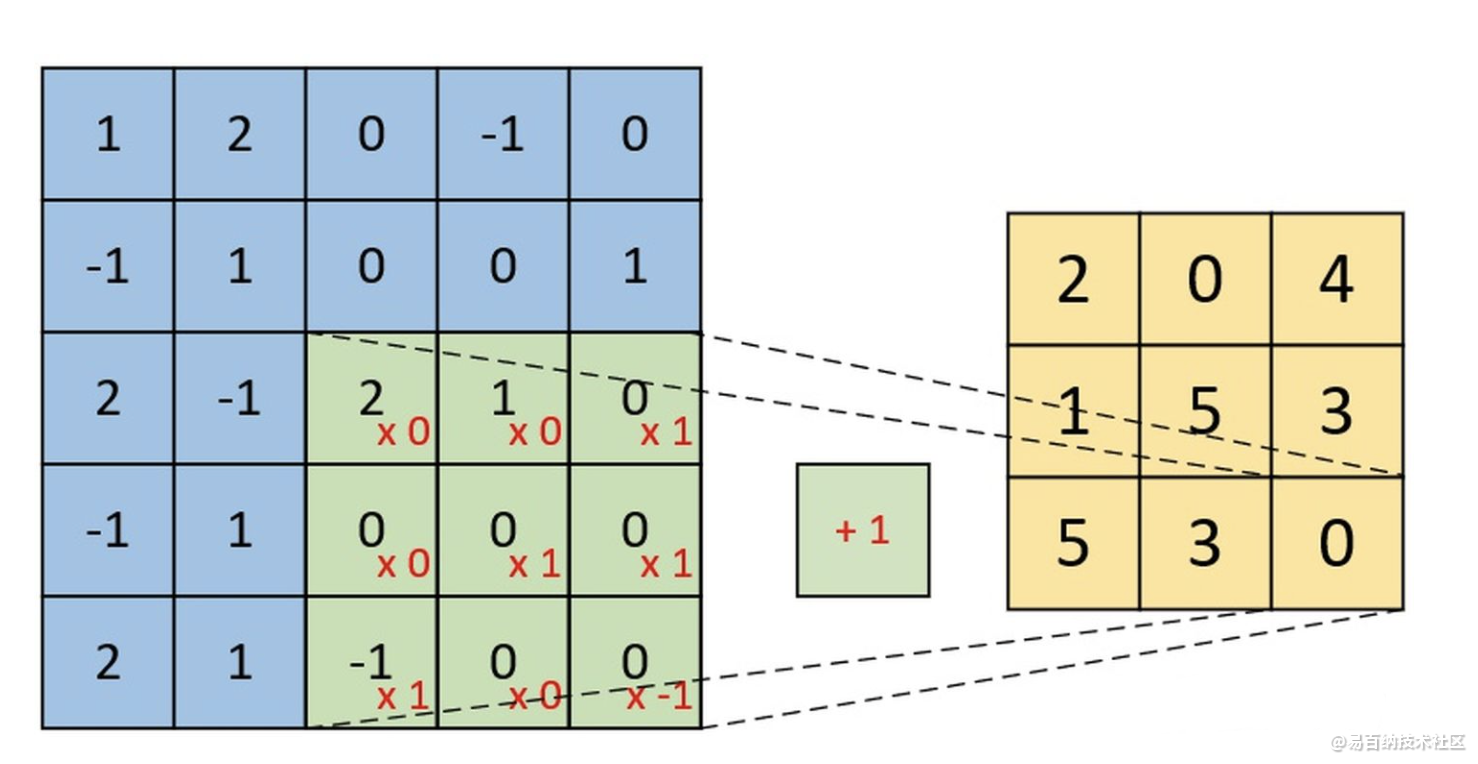
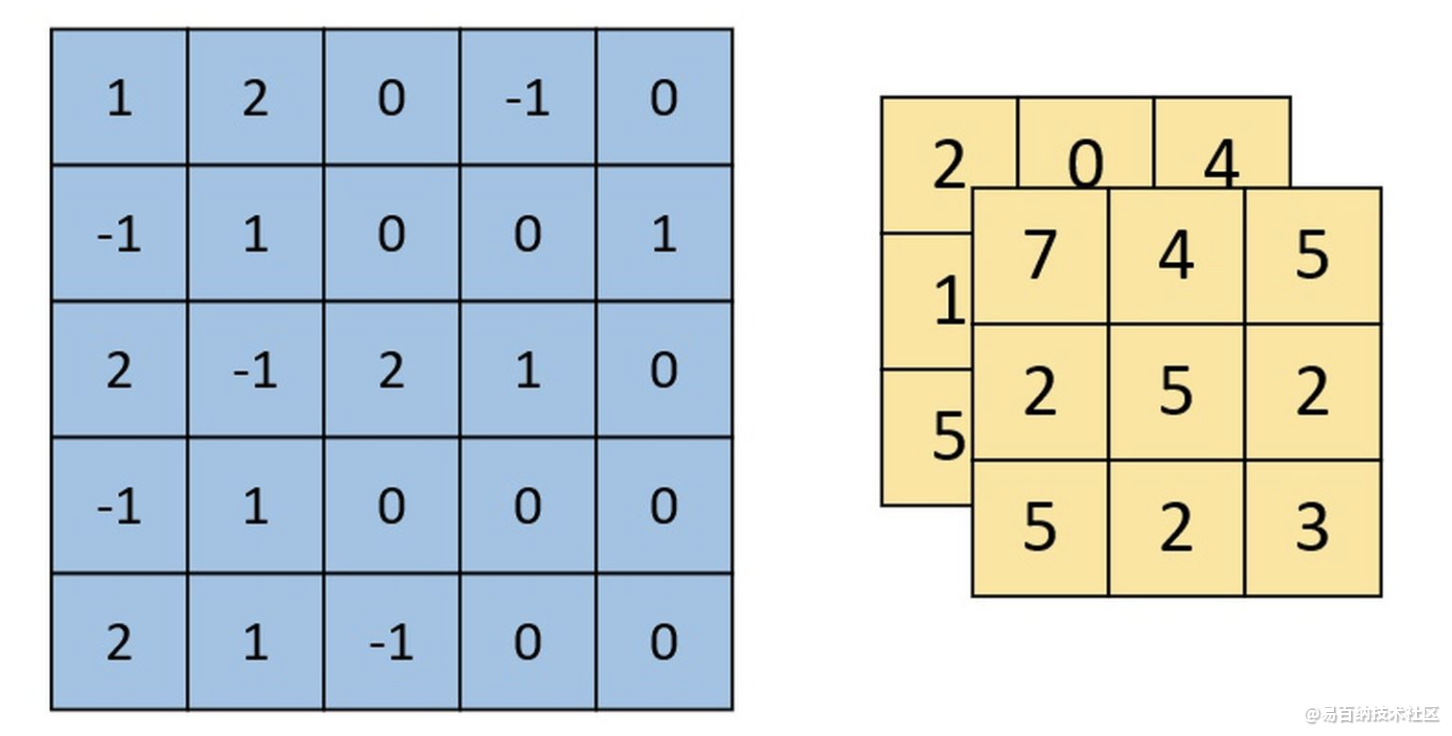
下图为卷积后的特征图(feature map),左边为卷积核对输入图片左上放进行卷积时的示意图。
单通道单卷积核
单通道多卷积
右边为Feature map。
卷积核长下面这样。
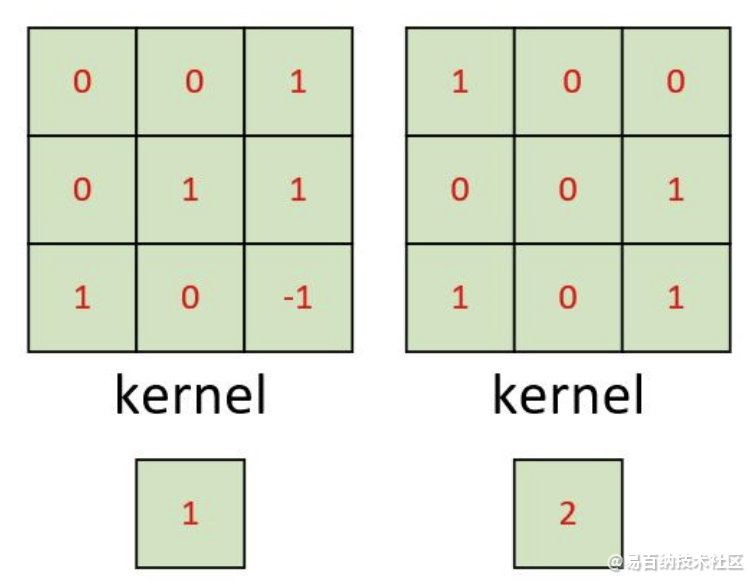
多通道单卷积核
左边为包含有三个通道的输入,右边为一个卷积核和一个偏置。注意,强调一下右边的仅仅只是一个卷积核,不是三个。笔者看到不少人在这个地方都会搞错。因为输入是三个通道,所以在进行卷积的时候,对应的每一个卷积核都必须要有三个通道才能进行卷积。下面我们就来看看具体的计算过程。
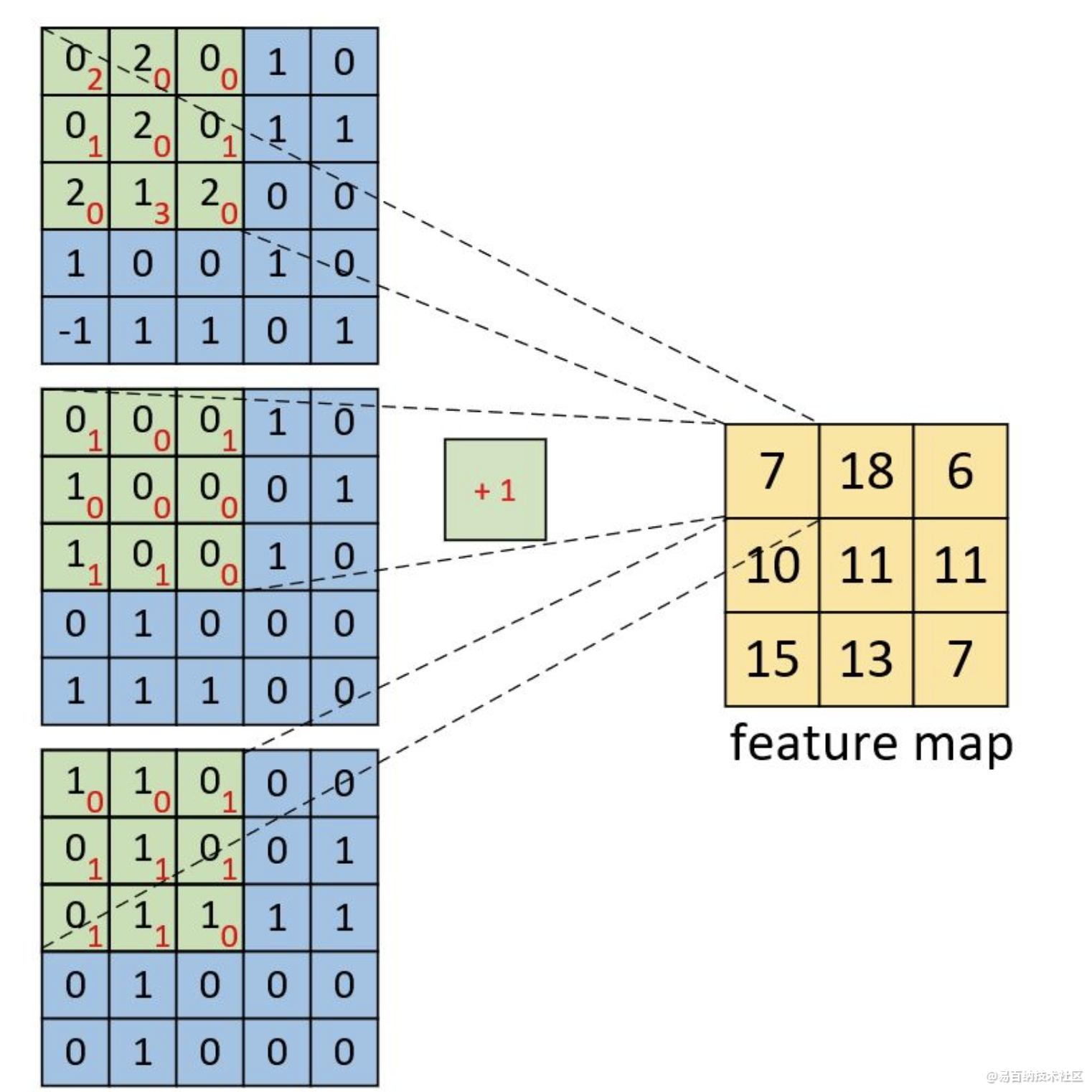

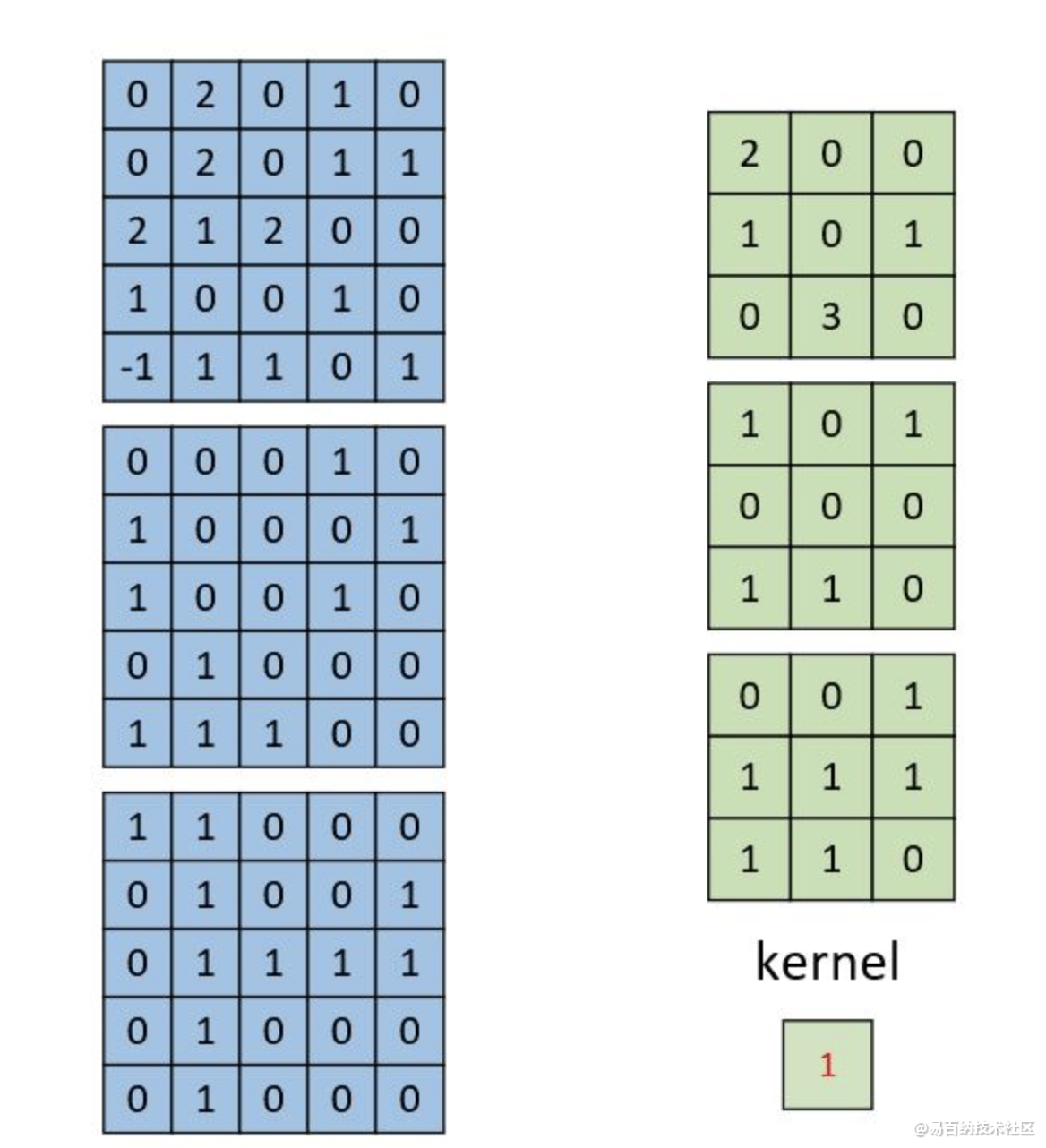
多通道多卷积核

左边依旧为输入矩阵,我们现在要用右边所示的两个卷积核对其进行卷积处理。对于第二个卷积核,都是将每个通道上的卷积结果进行相加,最后再加上偏置。形状为[3,3,2]的卷积特征图。
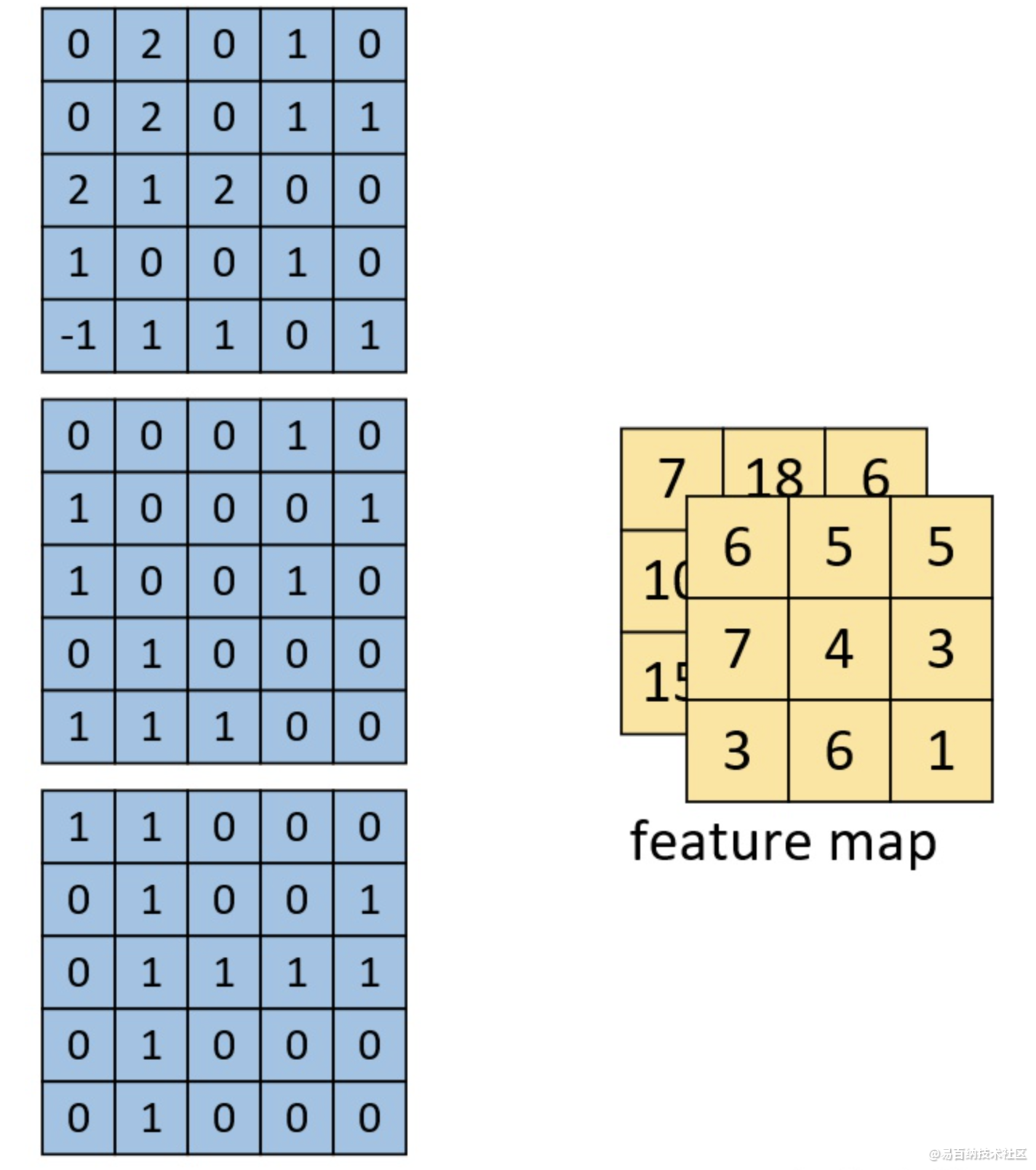
可以理解为一个卷积核一般输出一个featuremap。
深度可分离卷积网络与普通卷积网络
深度可分离卷积神经网络是卷积神经网络的一个变种,可以对卷积神经网络进行替代。对于普通的卷积申请网络,如下图左边部分所示,由卷积层,批归一化操作与激活函数构成的。对于深度可分离卷积网络,它是由一个3x3深度可分离的卷积层,批归一化,激活函数,1x1普通卷积层,批归一化,激活函数构成。在卷积神经网络中,将下图左边部分替换为右边部门,那么卷积神经网络就成为了深度可分离卷积网络。
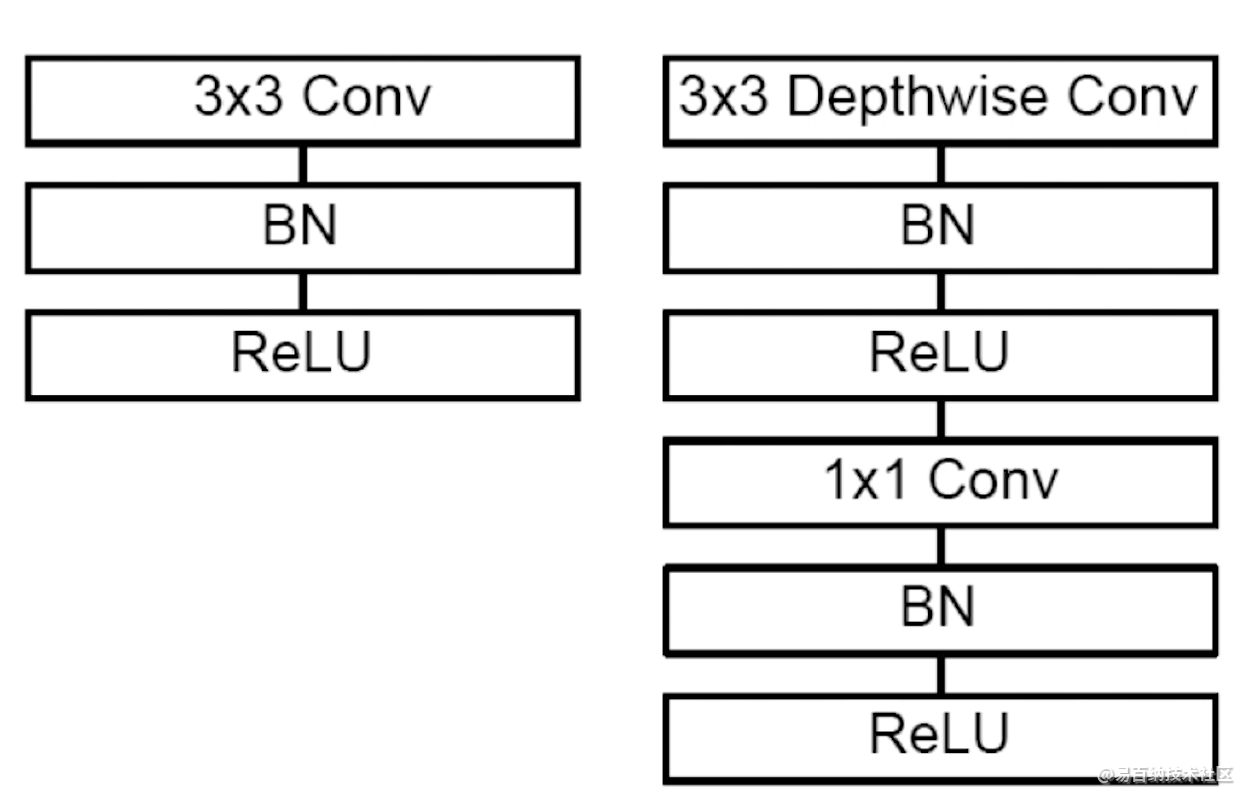
对于普通的卷积神经网络,输出通道是和所有的输入通道有关的。在深度可分离卷积网络里,输出通道只与单个输入通道有关。
1.1 正常卷积
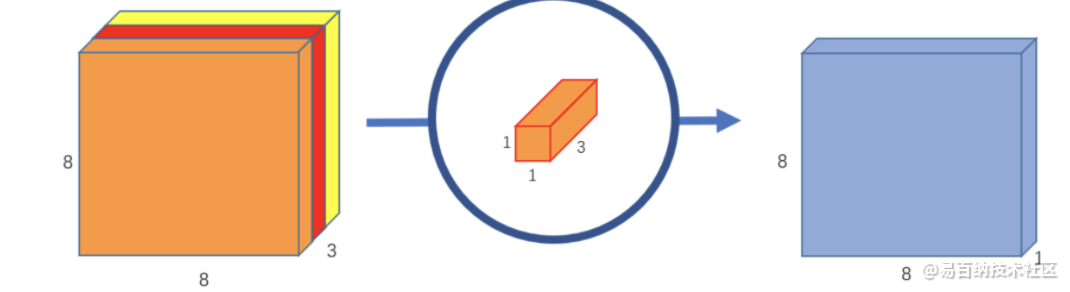
原始图像是二维的,大小是12x12。由于是RGB格式的,所以有三个通道,这相当于是一个3维的图片。其输入图片格式是:12x12x3。滤波器窗口大小是5x5x3。这样的话,得到的输出图像大小是8x8x1。
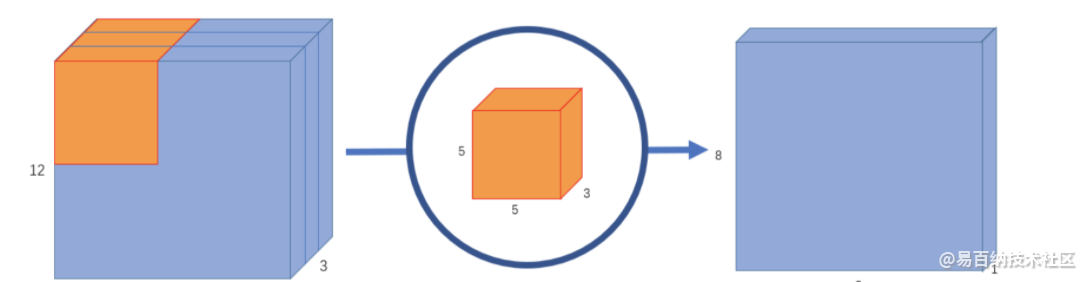
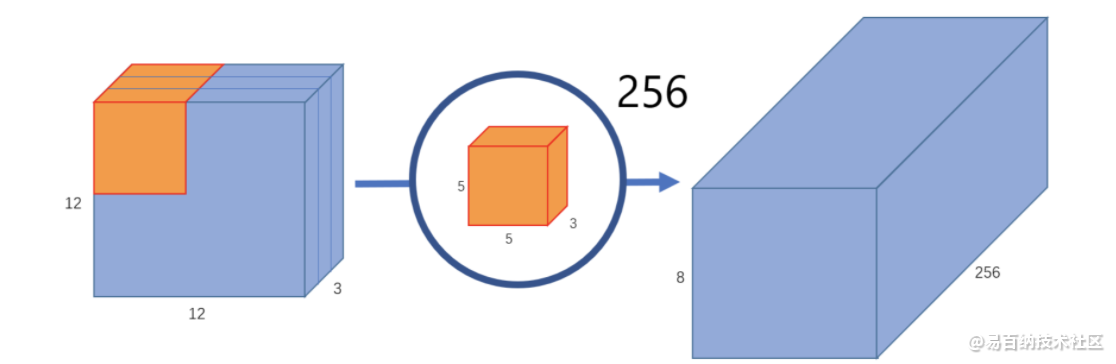
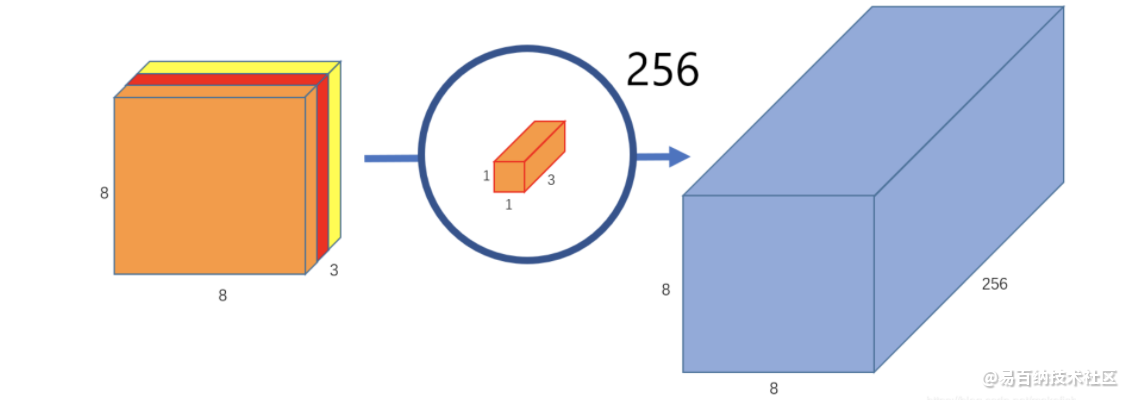
这仅仅提取到的图片里面的一个属性。如果希望获取图片更多的属性,譬如要提取256个属性,则:
1.2 Depth可分离卷积
深度可分离卷积的方法有所不同。正常卷积核是对3个通道同时做卷积。也就是说,3个通道,在一次卷积后,输出一个数。深度可分离卷积分为两步,第一步是用三个卷积对三个通道分别做卷积,这样在一次卷积后,输出3个通道的属性值
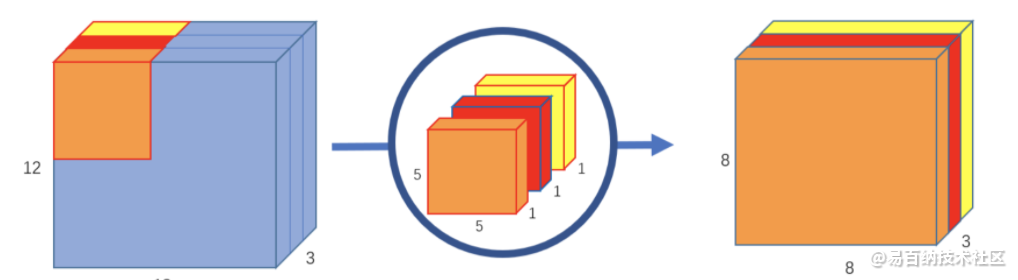
第二步是用卷积核1x1x3对三个通道再次做卷积,这个时候的输出就和正常卷积一样,是8x8x1:
如果要提取更多的属性,则需要设计更多的1x1x3卷积核心就可以
因为深度可分离神经网络的输出通道只与单个输入通道有关,所以很大程度上降低了参数计算量
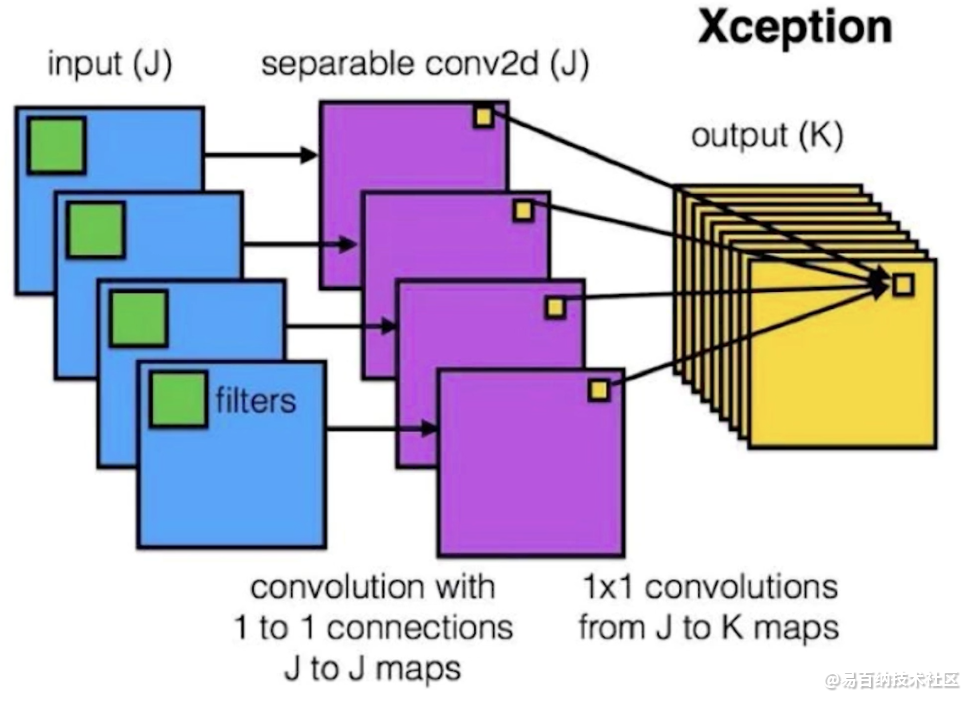
2 深度可分离卷积的优点
可以看出运用深度可分离卷积比普通卷积减少了所需要的参数。重要的是深度可分离卷积将以往普通卷积操作同时考虑通道和区域改变成,卷积先只考虑区域,然后再考虑通道。实现了通道和区域的分离。
3 空洞(扩张)卷积(Dilated/Atrous Convolution)
空洞卷积(dilated convolution)是针对图像语义分割问题中下采样会降低图像分辨率、丢失信息而提出的一种卷积思路。利用添加空洞扩大感受野,让原本3x3的卷积核,在相同参数量和计算量下拥有5x5(dilated rate =2)或者更大的感受野,从而无需下采样。扩张卷积(dilated convolutions)又名空洞卷积(atrous convolutions),向卷积层引入了一个称为 “扩张率(dilation rate)”的新参数,该参数定义了卷积核处理数据时各值的间距。换句话说,相比原来的标准卷积,扩张卷积(dilated convolution) 多了一个hyper-parameter(超参数)称之为dilation rate(扩张率),指的是kernel各点之前的间隔数量,【正常的convolution 的 dilatation rate为 1】。
上图是一个扩张率为2的3×3卷积核,感受野与5×5的卷积核相同,而且仅需要9个参数。你可以把它想象成一个5×5的卷积核,每隔一行或一列删除一行或一列。
在相同的计算条件下,空洞卷积提供了更大的感受野。空洞卷积经常用在实时图像分割中。当网络层需要较大的感受野,但计算资源有限而无法提高卷积核数量或大小时,可以考虑空洞卷积。

4 构建模型
模型利用keras自带的keras.layers.SeparableConv2D来实现,模型的结构与TensorFlow2.0(九)–Keras实现基础卷积神经网络中的结构一样,只是用深度可分离卷积代替了普通卷积:
# tf.keras.models.Sequential()用于将各个层连接起来
model = keras.models.Sequential()
# 第一层卷积层
model.add(keras.layers.SeparableConv2D(filters = 32, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu', # 激活函数relu
input_shape = (28, 28, 1))) # 输入维度是1通道的28*28
# 第二层卷积层
model.add(keras.layers.SeparableConv2D(filters = 32, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu')) # 激活函数relu
# 最大池化层
model.add(keras.layers.MaxPool2D(pool_size=2))
# 第三层卷积层
model.add(keras.layers.SeparableConv2D(filters = 64, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu')) # 激活函数relu
# 第四层卷积层
model.add(keras.layers.SeparableConv2D(filters = 64, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu')) # 激活函数relu
# 最大池化层
model.add(keras.layers.MaxPool2D(pool_size = 2))
# 第五层卷积层
model.add(keras.layers.SeparableConv2D(filters=128, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu')) # 激活函数relu
# 第六层卷积层
model.add(keras.layers.SeparableConv2D(filters=128, # 卷积核数量
kernel_size = 3, # 卷积核尺寸
padding = 'same', # padding补齐,让卷积之前与之后的大小相同
activation = 'relu')) # 激活函数relu
# 最大池化层
model.add(keras.layers.MaxPool2D(pool_size = 2))
# 全连接层
model.add(keras.layers.Flatten()) # 展平输出
model.add(keras.layers.Dense(128, activation = 'relu'))
model.add(keras.layers.Dense(10, activation = "softmax")) # 输出为 10的全连接层
5 U-Net网络更换空洞卷积
import numpy as np
import os
import skimage.io as io
import skimage.transform as trans
import numpy as np
from tensorflow.keras.models import *
from tensorflow.keras.layers import *
from tensorflow.keras.optimizers import *
from tensorflow.keras.callbacks import ModelCheckpoint, LearningRateScheduler
from tensorflow.keras import backend as keras
def unet(pretrained_weights=None, input_size=(256, 256, 1)):
inputs = Input(input_size) # 初始化keras张量
#第一层卷积
#实际上从unet的结构来看每一次卷积的padding应该是valid,也就是每次卷积后图片尺寸减少2,
#但在这里为了避免裁剪,方便拼接,把padding设成了same,即每次卷积不会改变图片的尺寸。
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(inputs)
# filters:输出的维度
# kernel_size:卷积核的尺寸
# activation:激活函数
# padding:边缘填充,实际上在该实验中并没有严格按照unet网络结构进行卷积,same填充在卷积完毕之后图片大小并不会改变
# kernel_initializer:kernel权值初始化
conv1 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)#采用2*2的最大池化
#第二层卷积
#参数类似于第一层卷积,只是输出的通道数翻倍
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool1)
conv2 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
#第三层卷积
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(pool2)
conv3 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
#第四层卷积
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal',dilation_rate=2)(pool3)
conv4 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal',dilation_rate=2)(conv4)
drop4 = Dropout(0.5)(conv4) # 每次训练时随机忽略50%的神经元,减少过拟合
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
#第五层卷积
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal',dilation_rate=2)(pool4)
conv5 = Conv2D(1024, 3, activation='relu', padding='same', kernel_initializer='he_normal',dilation_rate=2)(conv5)
drop5 = Dropout(0.5)(conv5)# 每次训练时随机忽略50%的神经元,减少过拟合
#第一次反卷积
up6 = Conv2D(512, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(drop5)) # 先上采样放大,在进行卷积操作,相当于转置卷积
# merge6 = merge([drop4, up6], mode='concat', concat_axis=3)
#将第四层卷积完毕并进行Dropout操作后的结果drop4与反卷积后的up6进行拼接
merge6 = concatenate([drop4, up6], axis=3) # (width,heigth,channels)拼接通道数
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge6)
conv6 = Conv2D(512, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv6)
#第二次反卷积
up7 = Conv2D(256, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv6))
# merge7 = merge([conv3, up7], mode='concat', concat_axis=3)
#将第三层卷积完毕后的结果conv3与反卷积后的up7进行拼接
merge7 = concatenate([conv3, up7], axis=3)
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge7)
conv7 = Conv2D(256, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv7)
#第三次反卷积
up8 = Conv2D(128, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv7))
# merge8 = merge([conv2, up8], mode='concat', concat_axis=3)
#将第二层卷积完毕后的结果conv2与反卷积后的up8进行拼接
merge8 = concatenate([conv2, up8], axis=3)#拼接通道数
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge8)
conv8 = Conv2D(128, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv8)
#第四次反卷积
up9 = Conv2D(64, 2, activation='relu', padding='same', kernel_initializer='he_normal')(
UpSampling2D(size=(2, 2))(conv8))
# merge9 = merge([conv1, up9], mode='concat', concat_axis=3)
#将第一层卷积完毕后的结果conv1与反卷积后的up9进行拼接
merge9 = concatenate([conv1, up9], axis=3)#拼接通道数
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(merge9)
conv9 = Conv2D(64, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
conv9 = Conv2D(2, 3, activation='relu', padding='same', kernel_initializer='he_normal')(conv9)
#进行一次卷积核为1*1的卷积操作,卷积完毕后通道数变为1,作为输出结果
conv10 = Conv2D(1, 1, activation='sigmoid')(conv9)
model = Model(inputs=inputs, outputs=conv10)
#keras内置函数,对模型进行编译
model.compile(optimizer=Adam(lr=1e-4), loss='binary_crossentropy', metrics=['accuracy'])
# optimizer:优化器
# binary_crossentropy:与sigmoid相对应的损失函数
# metrics:评估模型在训练和测试时的性能的指标
if pretrained_weights:
model.load_weights(pretrained_weights)
return model
空洞卷积(Dilated/Atrous Convolution)主要是在第四层和第五层实现的。
处理前:

处理后:

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:7509次2021-05-06 12:40:04
-
浏览量:18503次2021-05-11 15:08:39
-
浏览量:8104次2021-06-24 10:38:30
-
浏览量:6080次2021-05-04 20:20:52
-
浏览量:9866次2021-05-13 12:53:50
-
浏览量:4614次2021-05-14 09:47:57
-
浏览量:17291次2021-04-28 16:21:52
-
浏览量:1476次2024-02-01 14:20:47
-
浏览量:4766次2021-04-19 14:54:23
-
浏览量:4568次2018-02-14 10:30:11
-
浏览量:1690次2024-02-01 14:28:23
-
浏览量:5030次2021-04-23 14:09:15
-
浏览量:5564次2021-07-26 11:28:05
-
浏览量:5350次2021-04-21 17:05:28
-
浏览量:1864次2024-02-06 11:56:53
-
浏览量:2719次2024-02-06 11:41:16
-
浏览量:5707次2021-04-12 16:28:50
-
浏览量:17273次2021-07-16 12:56:10
-
浏览量:5633次2021-08-05 09:21:07

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
