

【深度学习】弱/半监督学习解决医学数据集规模小、数据标注难问题
【深度学习】弱/半监督学习解决医学数据集规模小、数据标注难问题

文章目录
1 概述
2 半监督学习
3 重新思考空洞卷积: 为弱监督和半监督语义分割设计的简捷方法
4 弱监督和半监督分割的训练和学习
5 总结1 概述
随着标注数据的大量增加,深度学习在图像分割方面获得了巨大地成功。然而,对于医学图像来说,标注数据的获取通常是昂贵的,因为生成准确的注释需要专业知识和时间,特别是在三维图像中。为了降低标记成本,近年来人们提出了许多方法来开发一种高性能的医学图像分割模型,以减少标记数据。例如,将用户交互与深度神经网络相结合,交互式地进行图像分割,可以减少标记的工作量。自监督学习方法是利用无标签数据,以监督的方式训练模型,学习基础知识然后进行知识迁移。半监督学习框架直接从有限地带标签数据和大量的未带标签数据中学习,得到高质量的分割结果。弱监督学习方法从边框、涂鸦或图像级标签中学习图像分割,而不是使用像素级标注,这减少了标注的负担。但是,弱监督学习和自监督学习在医学图像分割任务上性能依旧受限,尤其是在三维医学图像的分割上。除此之外,少量标注数据和大量未标注数据更加符合实际临床场景。本文总结了近些年出现的用于医学影像的半监督学习方法,这些方法大致可以分为:
(1),基于数据扰动或模型扰动或数据模型同时扰动正则化;
(2),基于多任务层面的一致性约束。医疗影像的数据紧缺问题我就不再多bibi了,为了解决这个问题,出现了很多的方法,像主动学习,迁移学习,半监督学习等弱监督学习方法,部分方法在图像分类中有很突出的应用。但是!图像分割尤其是医疗影像分割方面的弱监督方法还有待发掘~当然,也存在一些简单的方法,比如使用少量的数据训练的模型去预测未标注的数据,得到伪标签然后加入训练集继续训练。。。(在分类任务中比较常用)
先搞一下要点:
半监督学习
影像分割
正则化loss
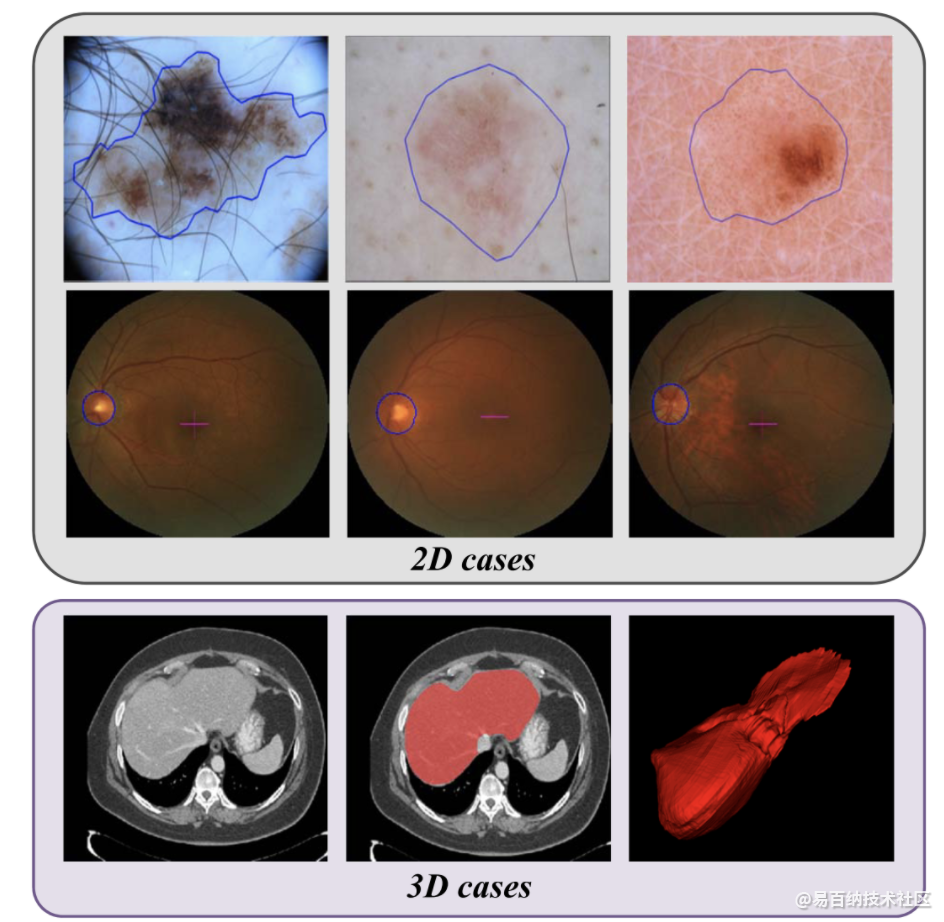
三个医疗影像数据集:skin lesion ISIC 2017 dataset,optic disc REFUGE dataset,liver LiTS dataset
2 半监督学习
Transformation equivariant representation
在不管是分类还是分割中,我们通常会需要数据增强来防止过拟合,并且提高精度。但是数据在进行增强时,比如图像顺时针旋转90度,而网络的参数是不会旋转的,其中的feature map也不一定与直接将不旋转的图像数据得到的feature map顺时针旋转90度一样,等价。但是他们的输入的确相同的,不过是其中一个多了90度的扰动。
注意: 在图像分割的任务中,默认是transformation equivariant!!
上面这个概念可以很好的由下面的图解释:
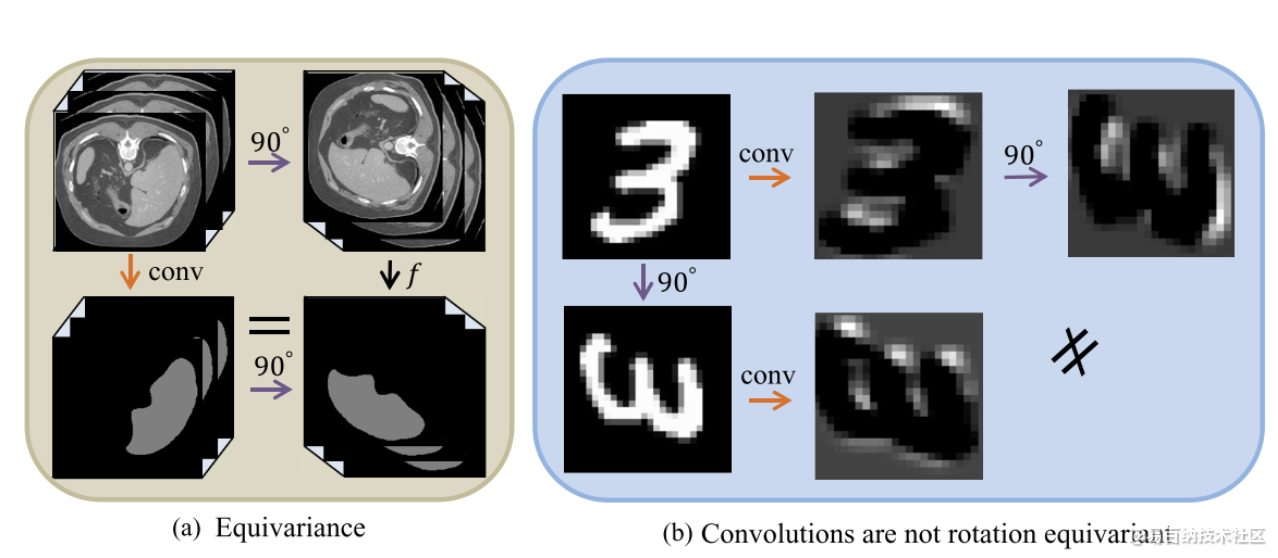
什么叫transformation equivariant,即上图a所示,但是在卷积中这并不是等价的,所以目前有很多在卷积中做转换等价的研究,包括同时旋转滤波器或者是特征图。
本论文利用了这个不等价的特性,加入了正则化平方差loss,这个后面再谈。
训练流程
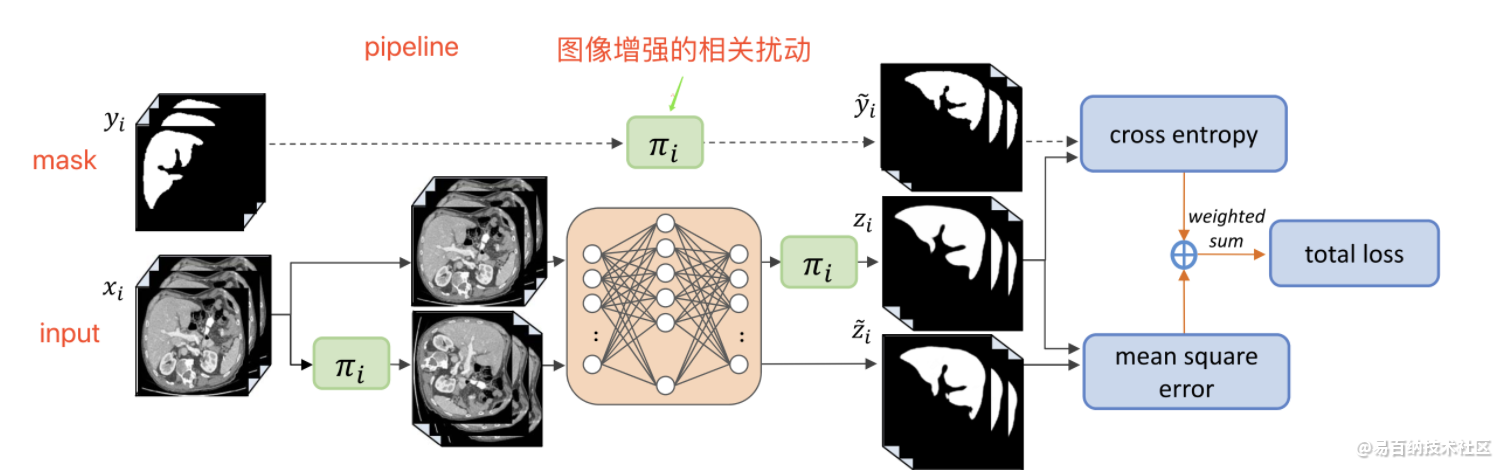
整体算法流程:

实验结果
不用说,论文上的肯定不错。
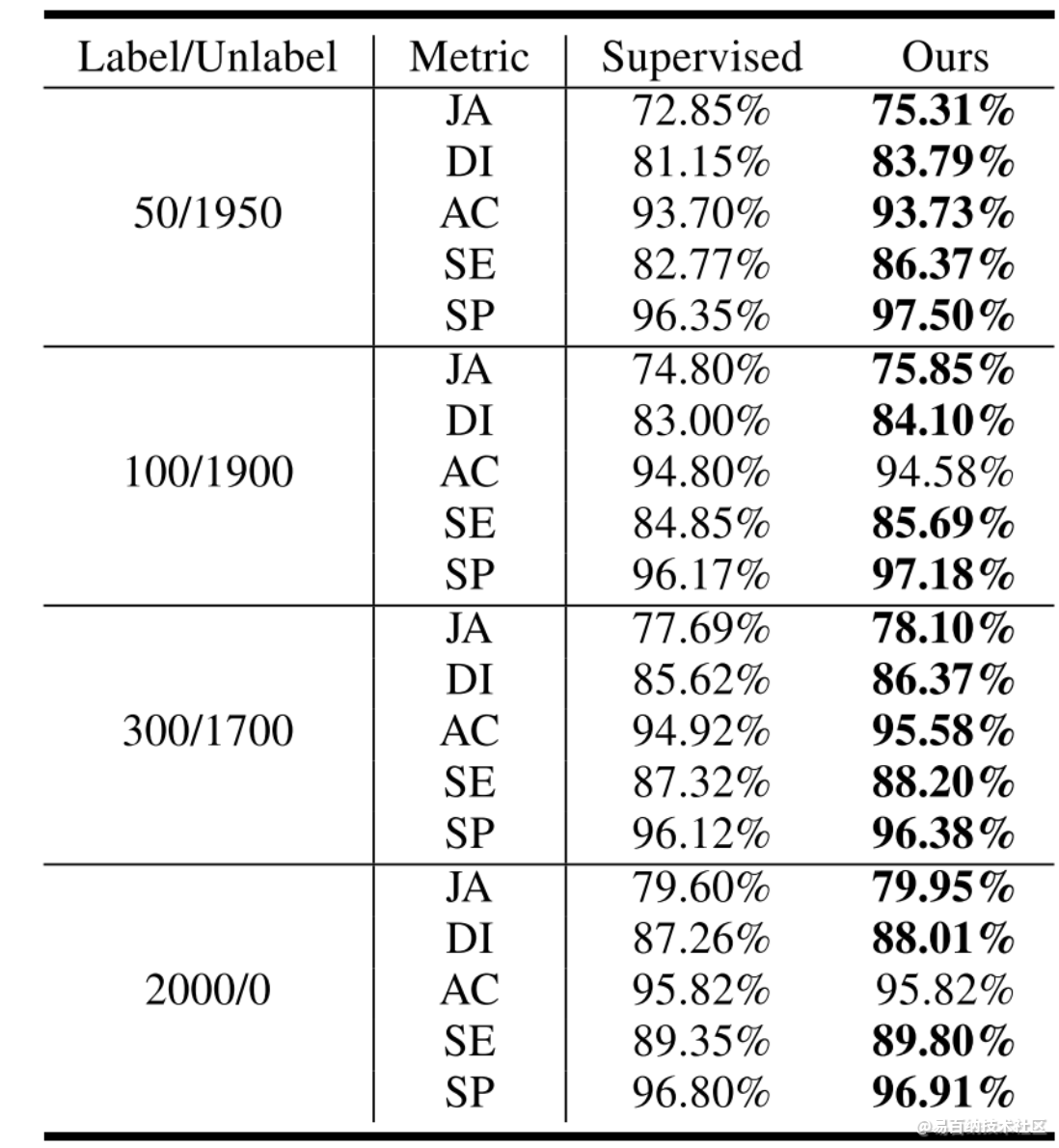
三个不同的数据集:
3 重新思考空洞卷积: 为弱监督和半监督语义分割设计的简捷方法
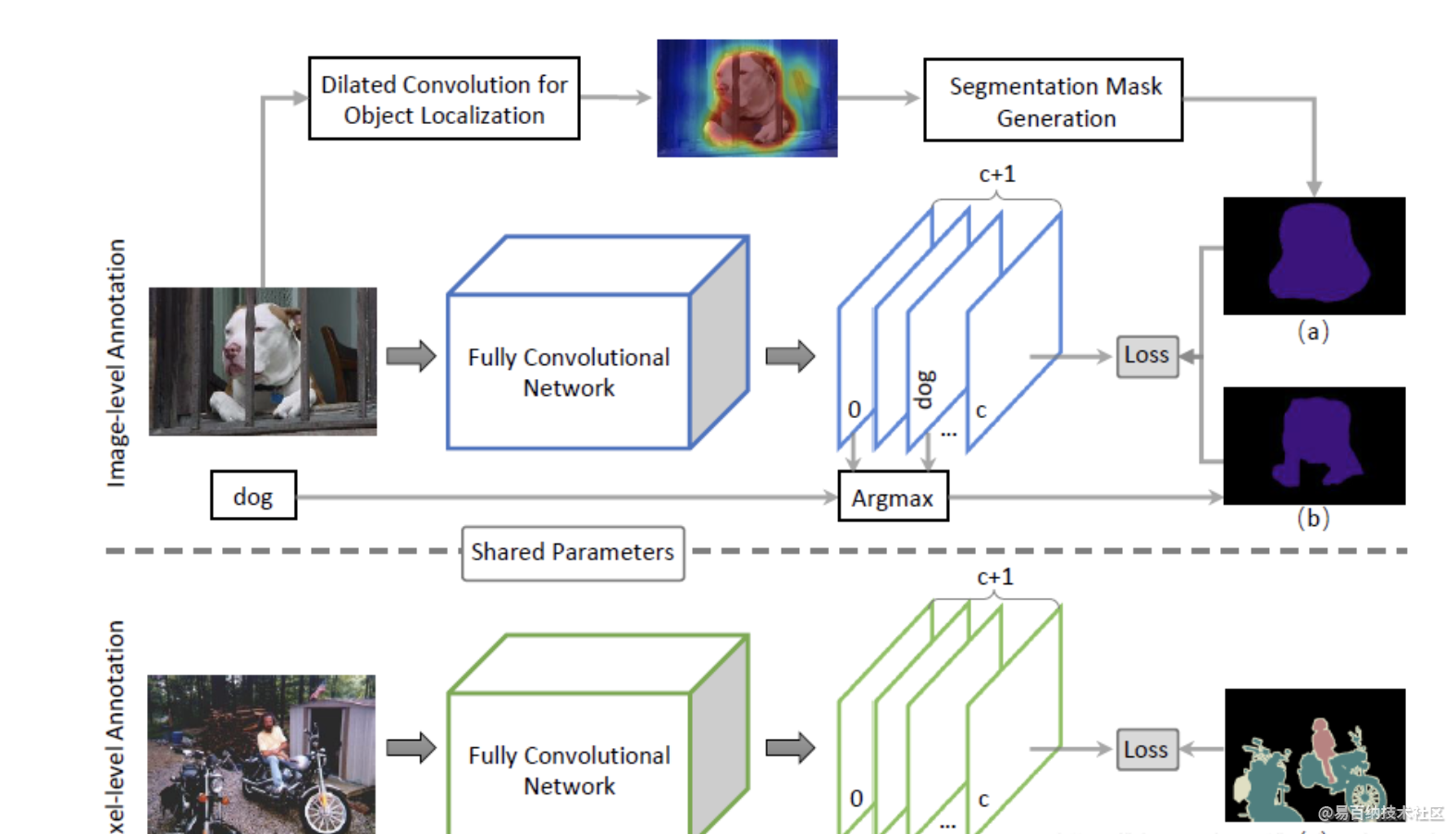
现有的一些方法使用分类网络能够分割物体的部分区域,该论文进一步增强分类模型使其能够将判明区域的信息传送给邻近未判明区域来克服上面的问题。如下图所示,空洞卷积能够使信息传输:
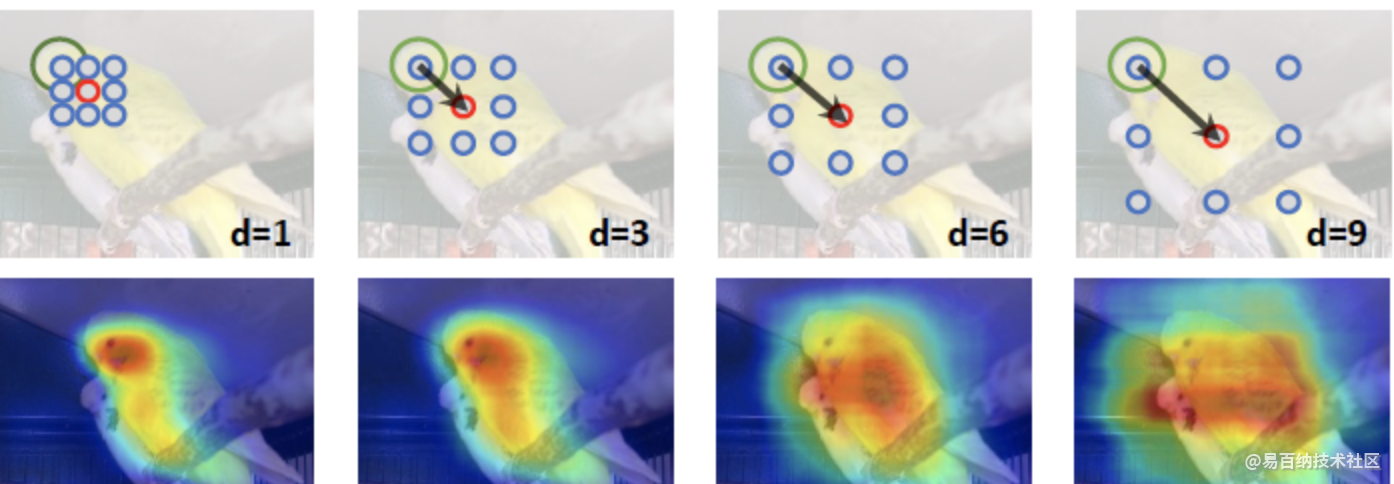
图片中鸟的头部是分类器给出的判明的区域,通过扩大空洞率,越来越多的区域也被判明。为了证明这个空洞卷积确实能提高热图中响应程度较低的区域的的分割效果,论文使用CAM产生了不同的定位图可以观察到在空洞率为1的定位图可以通过其他不同空洞率的卷积有效地提升响应程度。
4 弱监督和半监督分割的训练和学习
使用上面的方法产生的热图分别训练半监督分割模型和弱监督分割模型。
TCSM-V1: Semi-supervised Skin Lesion Segmentation via Transformation Consistent Self-ensembling Model. (BMVC2018)
总结:这篇文章的方法类似于Temporal ensembling for semi-supervised learning(ICLR2017)通过给输入数据加扰动(transformation)来正则化模型 (一次迭代模型需要前向传播两次,输入分别是未变化的图像和变化后的图像,然后变化后图像得到的结果进行反变换然后构建这两个预测结果的一致性损失),直接将未标注数据利用起来,想法很简洁但效果很不错。
TCSM-V2: Transformation-Consistent Self-Ensembling Model for Semisupervised Medical Image Segmentation. (TNNLS2020)
总结:这篇在Mean Teacher (NIPS2017) 的基础上引入了更多的数据扰动(flip, rotate, rescale,noise等等)和模型扰动(dropout)来构建同一输入在不同扰动下的一致性。然后取得了很不错的效果。
以上两篇的文章代码也已开源:
https://github.com/xmengli999/TCSM
5 总结
弱监督学习的三种类型
不完全监督(incomplete supervision): 只有一部分的训练数据含有标注信息,其他数据则没有标签
不确切监督(inexact supervision): 训练数据仅仅具有粗粒度的标注信息,例如在图像领域中的实例分割任务,仅仅含有bbox标注
不精确监督(inaccurate supervision): 训练数据的标注信息有误并不完全正确
不完全监督(incomplete supervision)
不完全监督主要应对只有训练集的一个很小的子集含有标签,而大量的样本为无标注的样本。如果仅仅采用有标注的信息训练模型,往往不能得到一个泛化能力强, 非常鲁棒的模型。
应对此不完全监督任务的两种解决方案是:主动学习和半监督学习
主动学习(active learning)
主动学习假设存在一个oracle(我也不知道怎么翻译,神谕???),主动学习假设可以从oracle查询选定的未标注实例的真值标签。
简单起见,假设模型的损失依赖于询问的数目,主动学习的目标就是最小化询问的数目,以此来最小化训练模型的损失
对于给定的一部分数目较少的标注样本和大量的无标注样本,主动学习试图寻找最有价值的无标注样本及逆行询问(query),有两种广泛使用的选择策略:信息性与代表性。信息性衡量一个无标注样本降低统计模型不确定性的程度;代表性衡量无标注样本对于表达输入范式的有用程度。
半监督学习(semi-supervised learning)
半监督学习无需人工的参与,自动开发无标注的数据,来提升模型的性能。
存在一种特殊的半监督学习,称为直推式学习(transductive learning);直推式学习和(纯)半监督学习的主要区别在于,它们对测试数据,即训练过的模型需要进行预测的数据,假设有所不同。直推式学习持有「封闭世界」假设,即,测试数据是事先给出的、目标是优化测试数据的性能;换言之,未标注数据正是测试数据。纯半监督式学习则持有「开放世界」假设,即,测试数据是未知的,未标注数据不一定是测试数据
在半监督学习中有两个主要的假设就是:聚类假设和流形假设,二者都是关于数据分布的假设。前者假设数据具有连续的聚类结构,因此在相同聚类簇中的结果有相同的类别。后者假设数据依赖于流形,因此相近的实例具有相同的类别。这两种假设都依赖于相似的数据点有相似的输出,因此无标注的数据对相似点的发现有帮助。
半监督学习有四种主要的方法:生成式方法,基于图的方法,低密度分离方法,基于不一致的方法
生成式方法假设有标注与无标注的样本由同一个连续模型生成。因此无标注样本的label作为生成式模型的丢失值,采用EM算法评估。这些模型的不同点在于使用不同的生成式模型来拟合数据,为了能够得到更好的效果通常需要domain的知识来获得充足的生成式模型,也有很多人尝试去混合生成式模型与判别式模型。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:15067次2021-07-08 09:43:47
-
浏览量:8522次2021-05-06 12:40:38
-
浏览量:8373次2021-07-19 17:08:40
-
浏览量:267次2023-07-25 11:57:50
-
浏览量:17739次2021-07-29 10:22:10
-
浏览量:319次2023-07-26 14:33:08
-
浏览量:13905次2021-05-12 12:35:30
-
浏览量:1484次2023-01-12 17:13:47
-
浏览量:1859次2024-07-12 09:12:43
-
浏览量:393次2023-07-14 14:21:54
-
2023-06-02 17:41:55
-
浏览量:2034次2023-02-01 09:16:22
-
浏览量:1141次2023-07-05 10:16:37
-
2023-01-13 11:33:00
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:5211次2021-04-19 14:55:00
-
浏览量:2515次2018-10-15 21:38:57
-
浏览量:2122次2023-02-14 14:48:11
-
浏览量:2147次2023-01-21 10:13:45

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
