

【深度学习】Transformer在语义分割上的应用探索
【深度学习】Transformer在语义分割上的应用探索
文章目录
1 Segmenter
2 Swin-Unet:Unet形状的纯Transformer的医学图像分割
3 复旦大学提出SETR:基于Transformer的语义分割
4 Cell-DETR:基于Transformer的细胞实例分割网络
5 总结1 Segmenter
图像分割在单个图像patches级别通常是ambiguous,需要上下文信息才能达成标签共识。
在本文中,我们介绍了Segmenter,这是一种用于语义分割的Transformer模型。
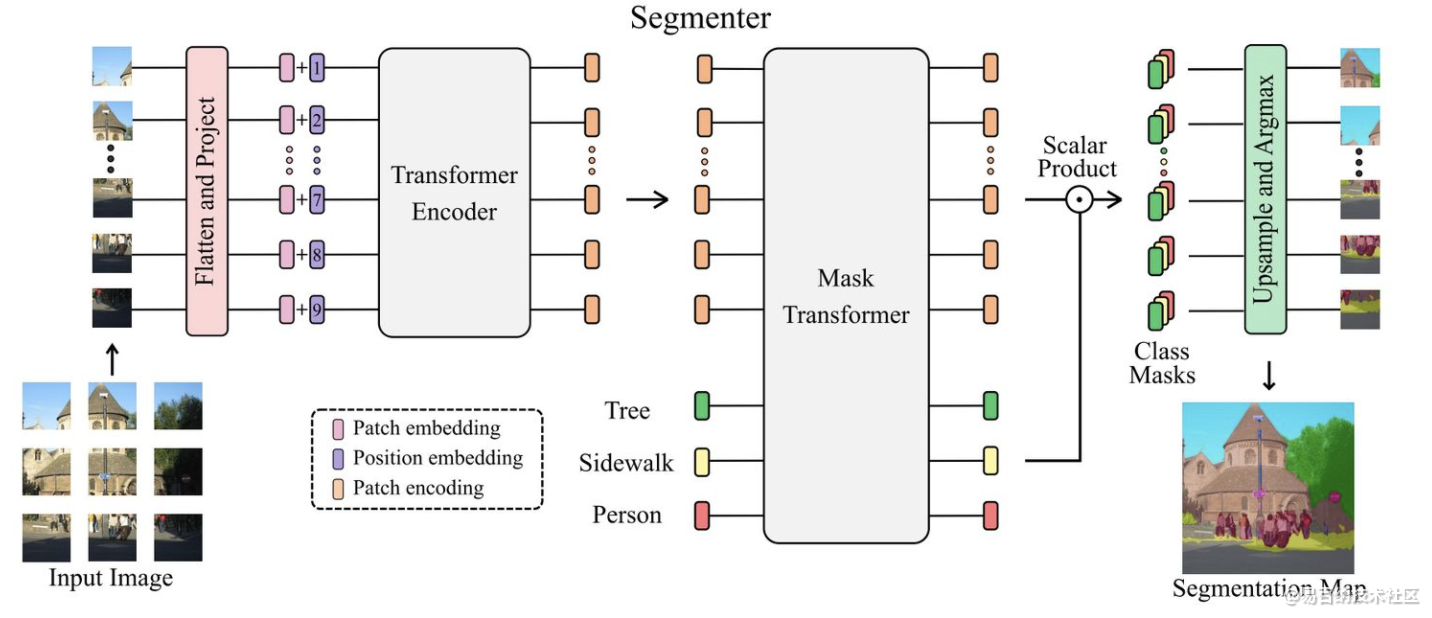
与基于卷积的方法相比,我们的方法允许在第一层和整个网络中对全局上下文进行建模。我们以最新的视觉Transformer(ViT)为基础,并将其扩展到语义分割。
为此,我们依赖于与图像块相对应的输出嵌入,并使用逐点线性解码器或掩码Transformer。解码器从这些嵌入中获取类标签。

我们利用针对图像分类进行预训练的模型,并表明我们可以在可用于语义分割的中等大小的数据集上进行微调。线性解码器已经允许获得出色的结果,但是可以通过生成类掩码的掩码Transformer来进一步提高性能。
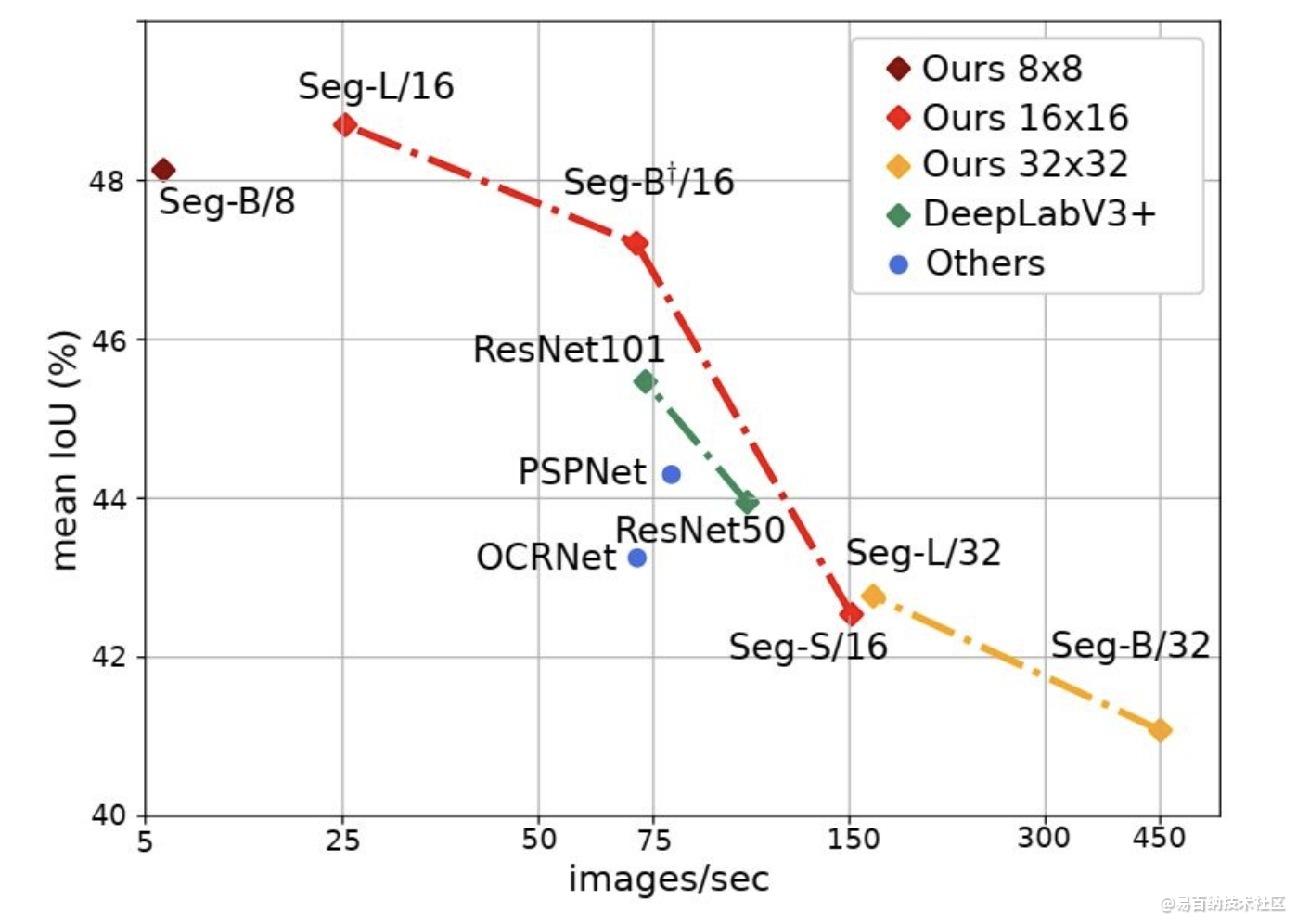
实验结果
我们进行了广泛的消融研究,以显示不同参数的影响,特别是对于大型模型和小patch sizes而言,性能更好。分割器在语义分割上取得了极好的效果。
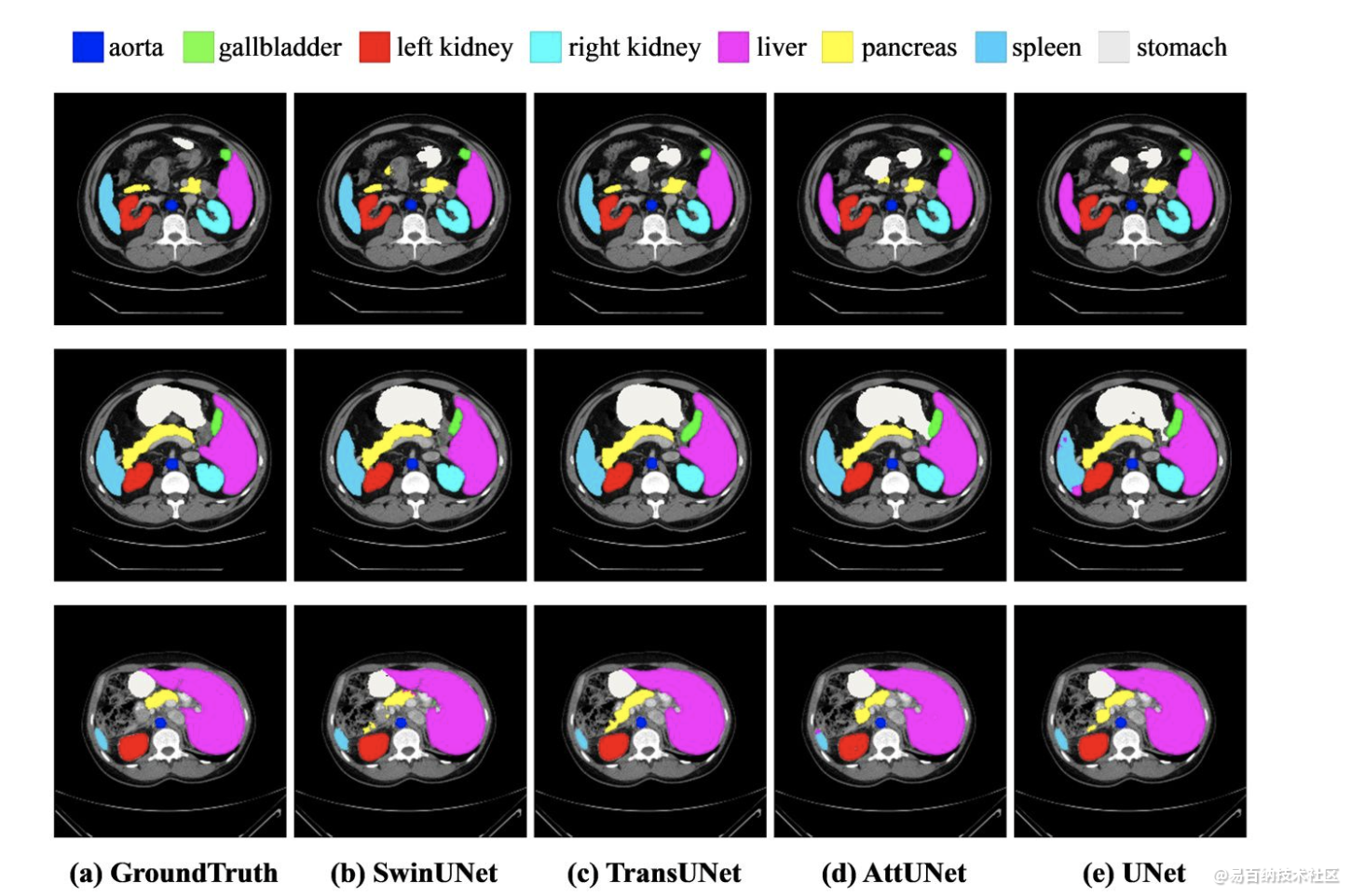
2 Swin-Unet:Unet形状的纯Transformer的医学图像分割
在过去的几年中,卷积神经网络(CNN)在医学图像分析中取得了里程碑式的进展。尤其是,基于U形架构和跳跃连接的深度神经网络已广泛应用于各种医学图像任务中。但是,尽管CNN取得了出色的性能,但是由于卷积操作的局限性,它无法很好地学习全局和远程语义信息交互。
在本文中,我们提出了Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer。标记化的图像块通过跳跃连接被馈送到基于Transformer的U形En-Decoder架构中,以进行局部全局语义特征学习。
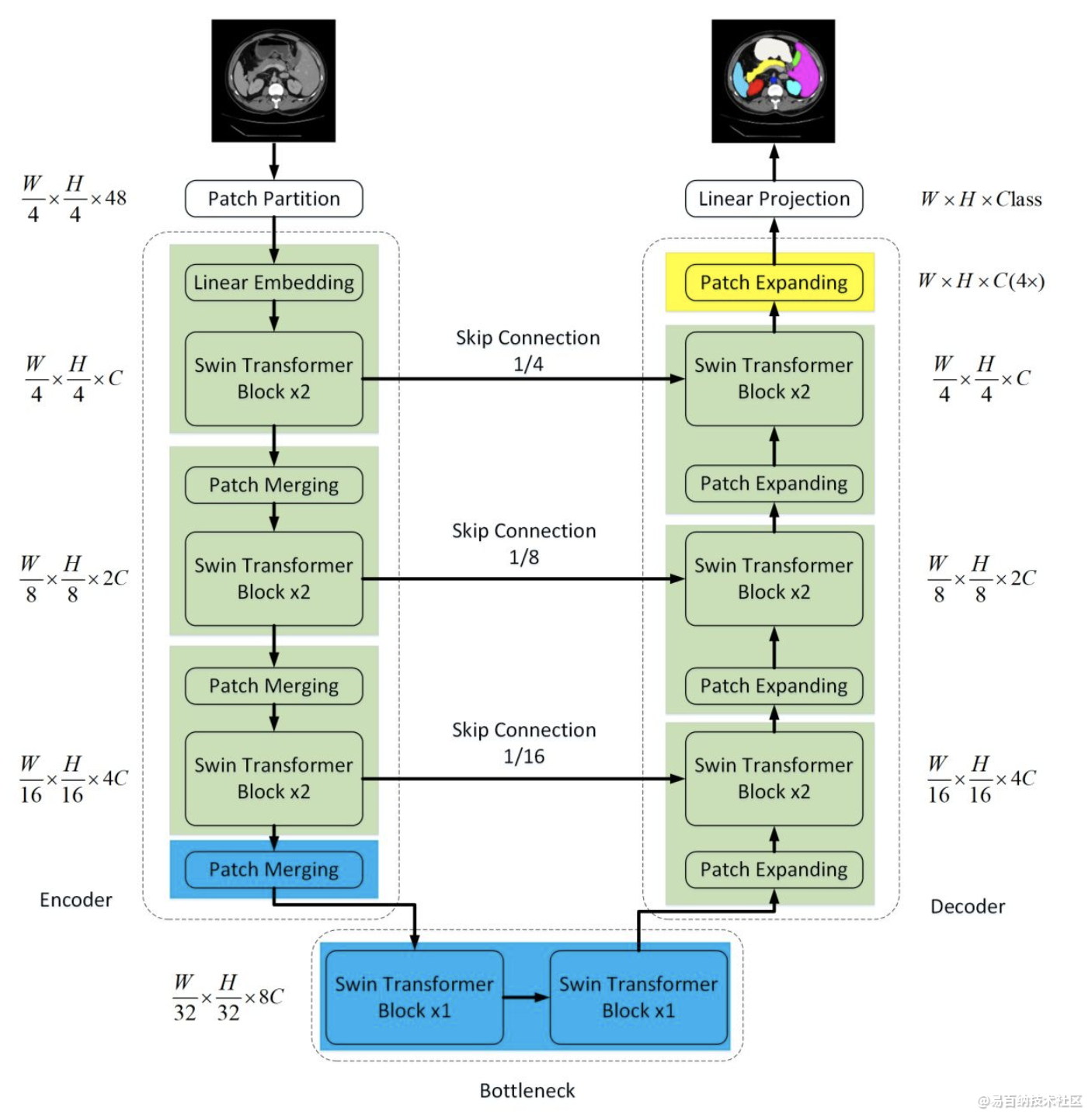
具体来说,我们使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。
实验结果
在对输入和输出进行4倍的直接下采样和上采样的情况下,对多qiguan和心脏分割任务进行的实验表明,基于纯Transformer的U形编码器/解码器网络优于那些全卷积或者Transformer和卷积的组合。
3 复旦大学提出SETR:基于Transformer的语义分割
最新的语义分割方法采用具有编码器-解码器体系结构的全卷积网络(FCN)。编码器逐渐降低空间分辨率,并通过更大的感受野学习更多的抽象/语义视觉概念。由于上下文建模对于分割至关重要,因此最新的工作集中在通过扩张/空洞卷积或插入注意力模块来增加感受野。但是,基于编码器-解码器的FCN体系结构保持不变。
在本文中,我们旨在通过将语义分割视为序列到序列的预测任务来提供替代视角。具体来说,我们部署一个纯 transformer(即,不进行卷积和分辨率降低)将图像编码为一系列patch。通过在 transformer的每一层中建模全局上下文,此编码器可以与简单的解码器组合以提供功能强大的分割模型,称为SEgmentation TRansformer(SETR)。
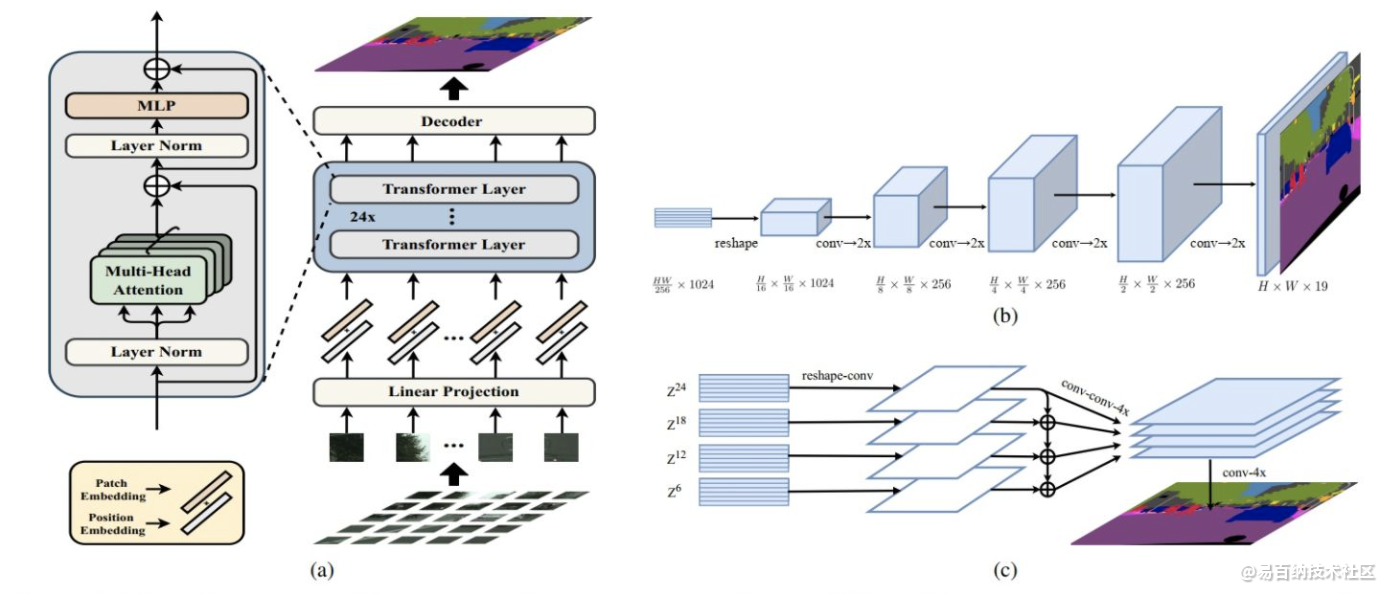
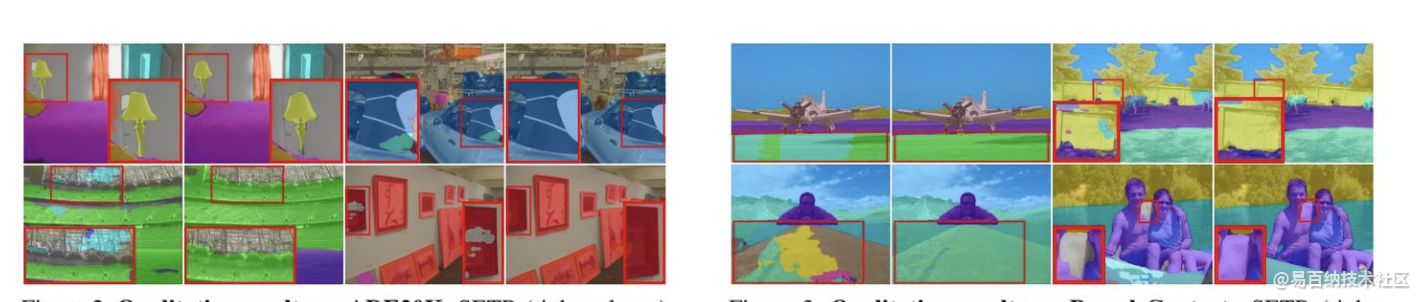
实验结果
大量实验表明,SETR在ADE20K(50.28%mIoU),Pascal Context(55.83%mIoU)上取得了新的技术水平。
4 Cell-DETR:基于Transformer的细胞实例分割网络
在生物医学应用中,检测和分割对象实例是一项常见的任务。示例包括从在功能性磁共振图像上检测病变,到在组织病理学图像中检测肿瘤,以及从显微镜成像中提取定量单细胞信息,其中细胞分割是一个主要瓶颈。基于注意力的转换器是一系列深度学习领域中的最新技术。最近有人提出将它们用于分割任务,在这些任务中它们开始表现优于其他方法。我们提出了一种新颖的基于注意力的细胞检测变换器(Cell-DETR),用于直接的端到端实例分割。
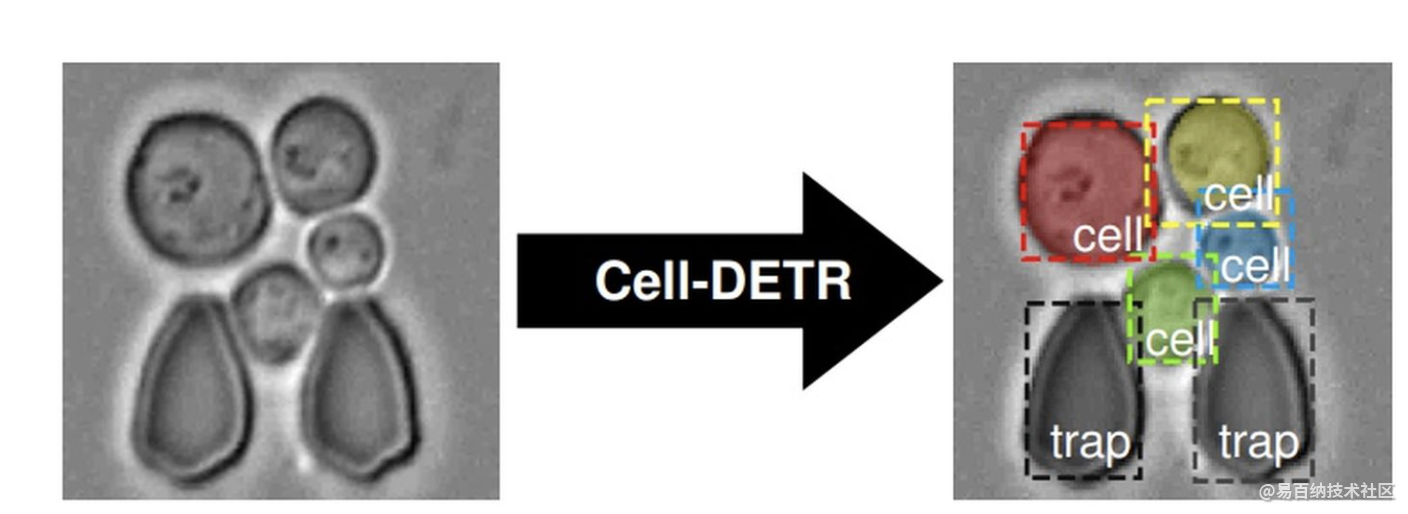
虽然分割性能与最新的实例分割方法相当,但是Cell-DETR更简单,更快。我们在系统或合成生物学中常用的微结构化环境中细分酵母的典型用例中展示了该方法的贡献。
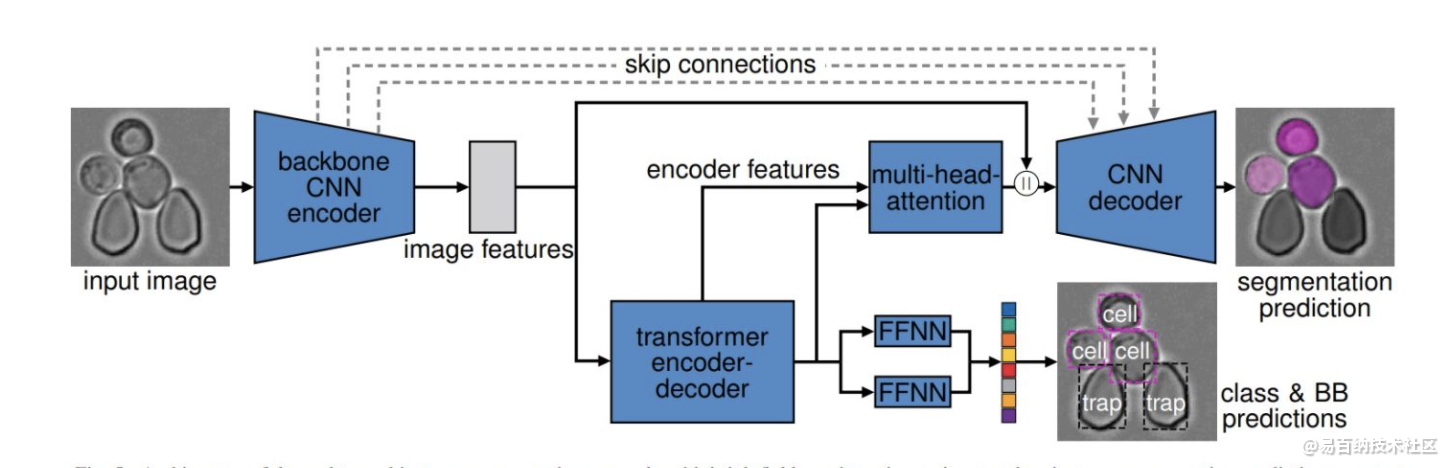
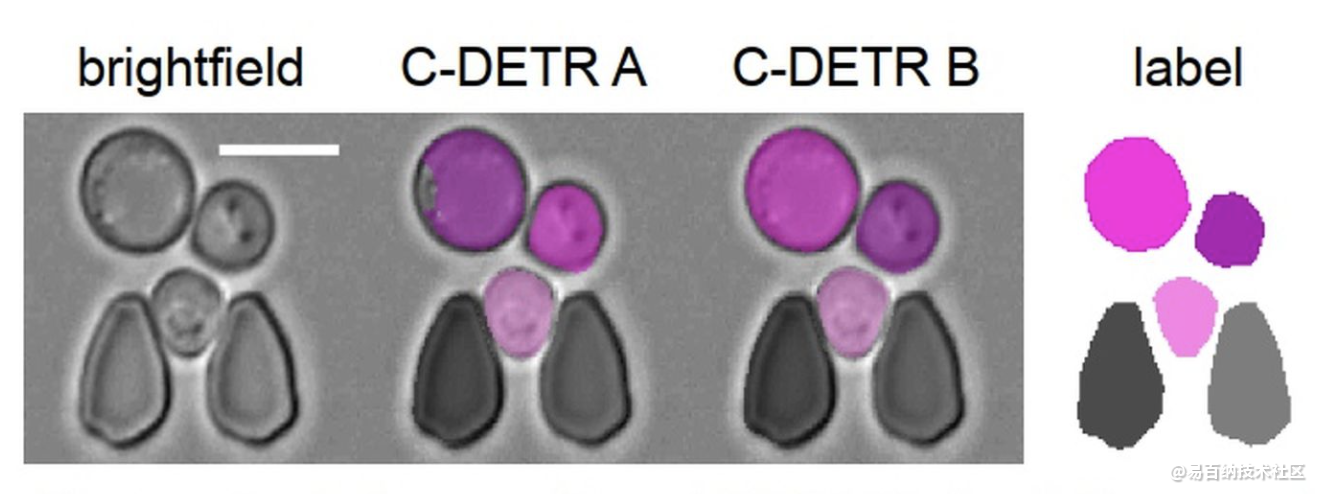
实验结果
对于特定的用例,所提出的方法超越了用于语义分割的最新工具,并且还可以预测各个对象实例。快速准确的实例分割性能提高了后验数据处理的实验信息产量,并使在线监测实验和闭环最佳实验设计变得可行。
5 总结
Transformer中抛弃了传统的CNN和RNN,整个网络结构完全是由Attention机制组成。更准确地讲,Transformer由且仅由self-Attenion和Feed Forward Neural Network组成。一个基于Transformer的可训练的神经网络可以通过堆叠Transformer的形式进行搭建,作者的实验是通过搭建编码器和解码器各6层,总共12层的Encoder-Decoder,并在机器翻译中刷新了BLEU值。
目前Transformer应用到图像领域主要有两大挑战:
视觉实体变化大,在不同场景下视觉Transformer性能未必很好
图像分辨率高,像素点多,Transformer基于全局自注意力的计算导致计算量较大
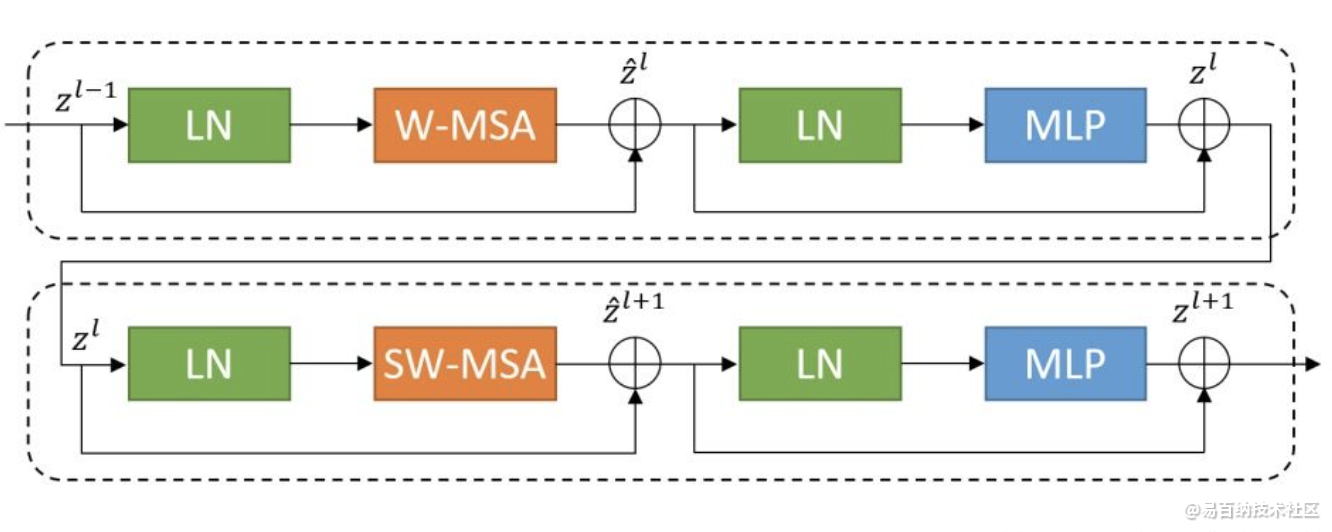
针对上述两个问题,我们提出了一种包含滑窗操作,具有层级设计的Swin Transformer。
其中滑窗操作包括不重叠的local window,和重叠的cross-window。将注意力计算限制在一个窗口中,一方面能引入CNN卷积操作的局部性,另一方面能节省计算量。
Swin Transformer最重要的两点是hierarchical feature representation和SW-MSA(Shifted Window based Multi-head Self-attention)。
Swin-Unet,它是用于医学图像分割的类似Unet的纯Transformer模型。标记化的图像块通过跳跃连接被送到基于Transformer的U形Encoder-Decoder架构中,以进行局部和全局语义特征学习。
具体来说,使用带有偏移窗口的分层Swin Transformer作为编码器来提取上下文特征。并设计了一个symmetric Swin Transformer-based decoder with patch expanding layer来执行上采样操作,以恢复特征图的空间分辨率。在对输入和输出进行4倍的下采样和上采样的情况下,对多qiguan和心脏分割任务进行的实验表明,基于纯Transformer的U-shaped Encoder-Decoder优于那些全卷积或者Transformer和卷积的组合。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:8373次2021-07-19 17:08:40
-
浏览量:1173次2023-06-02 17:41:00
-
浏览量:2125次2023-02-14 14:48:11
-
浏览量:7867次2021-04-29 12:46:50
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:1376次2023-06-03 15:59:06
-
浏览量:8100次2021-06-24 10:38:30
-
浏览量:7667次2021-05-04 20:17:10
-
浏览量:5112次2021-05-18 15:15:50
-
浏览量:17892次2021-05-31 17:01:00
-
浏览量:6234次2021-06-17 11:39:26
-
浏览量:123次2023-08-23 08:46:26
-
浏览量:17289次2021-04-28 16:21:52
-
浏览量:7821次2021-06-27 18:19:55
-
浏览量:2086次2023-12-28 13:59:27
-
浏览量:50546次2021-07-28 14:21:08
-
浏览量:6580次2021-07-28 14:21:28
-
浏览量:5158次2021-04-20 15:50:27
-
浏览量:8050次2021-06-07 09:27:26

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
