

【深度学习】Transfomer在文本处理上的应用(风格识别)
【深度学习】Transfomer在文本处理上的应用(风格识别)

文章目录
1 Transformers简介
2 数据预处理
3 作家风格识别
4 实验内容
4.1 介绍数据集
4.2 数据集预处理
4.3 模型代码
# 5 实验结果1 Transformers简介
现目前NLP任务最热门的方式即是:大规模预训练+微调的方式,完成模型训练。即通过大规模预训练模型,训练出词向量表达。然后在特定的NLP任务下进行微调训练的方式完成训练。
Transformers(以前称为pytorch-transformers和pytorch-pretrained-bert)提供用于自然语言理解(NLU)和自然语言生成(NLG)的通用体系结构(BERT,GPT-2,RoBERTa,XLM,DistilBert,XLNet等) )包含超过32种以100多种语言编写的预训练模型,以及TensorFlow 2.0和PyTorch之间的深度互操作性。
简单来说,我们可以通过使用Transformers的框架来更方便的调用现在nlp常用的大规模预训练模型,同时Transformers也封装了一些常见的下游任务来进行精调。Transformers现目前封装的下游任务包括:文本分类、提取式问答、语言建模、命名实体识别。
本文的目的在于介绍使用Transformers的基本流程,入门了解Transformers使用方法。之后可根据自身需求对该框架进行更多的了解。关于如何安装在官方文档中已经介绍的很完整了,按照要求完成安装即可。下面是Transformers的官方文档。
https://link.zhihu.com/?target=https%3A//huggingface.co/transformers/
2 数据预处理
这里的数据预处理主要涉及到将文本数据处理成能输入到对应的预训练模型的步骤。
这里的数据预处理主要涉及到将文本数据处理成能输入到对应的预训练模型的步骤。
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_name)
这里的model_name为你的预训练模型名字:
(1)可以为官方准备好的预训练模型,模型会直接下载相关模型,只是因为网络原因还是建议方案(2)
(2)直接下载预训练模型到本地,这里model_name填写为本地预训练模型的文件夹地址。
然后直接将我们的文本输入到tokenizer,然后输出我们模型需要的三个内容:input_ids、token_type_ids、attention_mask。
encoded_input = tokenizer("Hello, I'm a single sentence!")
print(encoded_input)
{'input_ids': [101, 138, 18696, 155, 1942, 3190, 1144, 1572, 13745, 1104, 159, 9664, 2107, 102],
'token_type_ids': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0],
'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}如果处理多个句子可以通过将它们作为列表发送到令牌生成器来有效地做到这一点:
batch_sentences = ["Hello I'm a single sentence",
"And another sentence",
"And the very very last one"]
encoded_inputs = tokenizer(batch_sentences)
print(encoded_inputs)
{'input_ids': [[101, 8667, 146, 112, 182, 170, 1423, 5650, 102],
[101, 1262, 1330, 5650, 102],
[101, 1262, 1103, 1304, 1304, 1314, 1141, 102]],
'token_type_ids': [[0, 0, 0, 0, 0, 0, 0, 0, 0],
[0, 0, 0, 0, 0],
[0, 0, 0, 0, 0, 0, 0, 0]],
'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 1, 1],
[1, 1, 1, 1, 1],
[1, 1, 1, 1, 1, 1, 1, 1]]}预训练模型选择与下游任务微调
这里选择使用pytorch框架进行演示,Transformers官方文档同时提供了TF和Pytorch两个版本。我们在载入预训练模型然后进行微调时有两种选择。一个是载入单纯的预训练模型然后自己在网络中编写下游任务。一个载入Transformers封装好的下游预训练模型。我们这里以常见的文本分类,以及预训练模型bert作为例子举例。其他任务和模型根据官方文档换个名字即可。这里演示用官方封装好的模型进行训练。
from transformers import BertForSequenceClassification
import torch
#官方封装好的bert+下游任务
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', return_dict=True)
model.train()
#载入优化器
from transformers import AdamW
optimizer = AdamW(model.parameters(), lr=1e-5)
#设置训练参数:设置权重衰减参数,和学习率。
no_decay = ['bias', 'LayerNorm.weight']
optimizer_grouped_parameters = [
{'params': [p for n, p in model.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01},
{'params': [p for n, p in model.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0}
]
optimizer = AdamW(optimizer_grouped_parameters, lr=1e-5)
#将上文以处理好的数据输入到模型训练
input_ids = encoded_inputs['input_ids']
attention_mask = encoded_inputs['attention_mask']
labels = torch.tensor([1,0]).unsqueeze(0)
outputs = model(input_ids, attention_mask=attention_mask, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
#保存模型参数
torch.save(model.state_dict(), PATH)
#加载模型参数
model.load_state_dict(torch.load("roberta_model.pth"))这里只做了最简单的演示,大概了解Transformers框架。让新手能够跑起来,之后更多的进阶,完全可以参考官方文档进行更深入学习。
3 作家风格识别
1.实验介绍
1.1实验背景
作家风格是作家在作品中表现出来的独特的审美风貌。
通过分析作品的写作风格来识别作者这一研究有很多应用,比如可以帮助人们鉴定某些存在争议的文学作品的作者、判断文章是否剽窃他人作品等。
作者识别其实就是一个文本分类的过程,文本分类就是在给定的分类体系下,根据文本的内容自动地确定文本所关联的类别。 写作风格学就是通过统计的方法来分析作者的写作风格,作者的写作风格是其在语言文字表达活动中的个人言语特征,是人格在语言活动中的某种体现。
1.2 实验要求
a)建立深度神经网络模型,对一段文本信息进行检测识别出该文本对应的作者。
b)绘制深度神经网络模型图、绘制并分析学习曲线。
c)用准确率等指标对模型进行评估。
1.3 实验环境
可以使用基于 Python 分词库进行文本分词处理,使用 Numpy 库进行相关数值运算,使用 Keras 等框架建立深度学习模型等。
4 实验内容
4.1 介绍数据集
该数据集包含了 8438 个经典中国文学作品片段,对应文件分别以作家姓名的首字母大写命名。
数据集中的作品片段分别取自 5 位作家的经典作品,分别是:
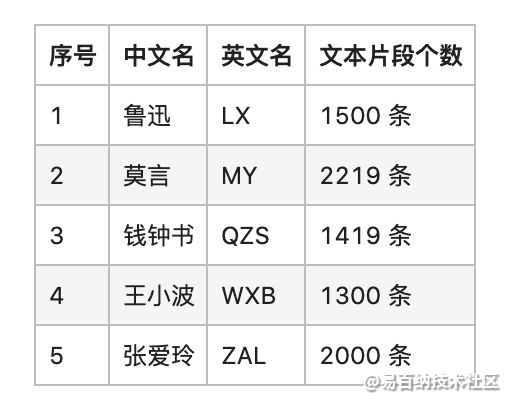
4.2 数据集预处理
在做文本挖掘的时候,首先要做的预处理就是分词。
英文单词天然有空格隔开容易按照空格分词,但是也有时候需要把多个单词做为一个分词,比如一些名词如 "New York" ,需要做为一个词看待。
而中文由于没有空格,分词就是一个需要专门去解决的问题了。
这里我们使用 jieba 包进行分词,使用精确模式、全模式和搜索引擎模式进行分词对比。
# 搜索引擎模式分词
titles = [".".join(jb.cut_for_search(t)) for t,_ in dataset.items()]
print("搜索引擎模式分词结果:\n",titles[0])4.3 模型代码
# Create train and validation dataloaders
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
val_dataloader = DataLoader(val_dataset, batch_size=batch_size, shuffle=False)
# Load the pretrained BERT model
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=num_labels,
output_attentions=False,
output_hidden_states=False)
model.to(device)5 实验结果
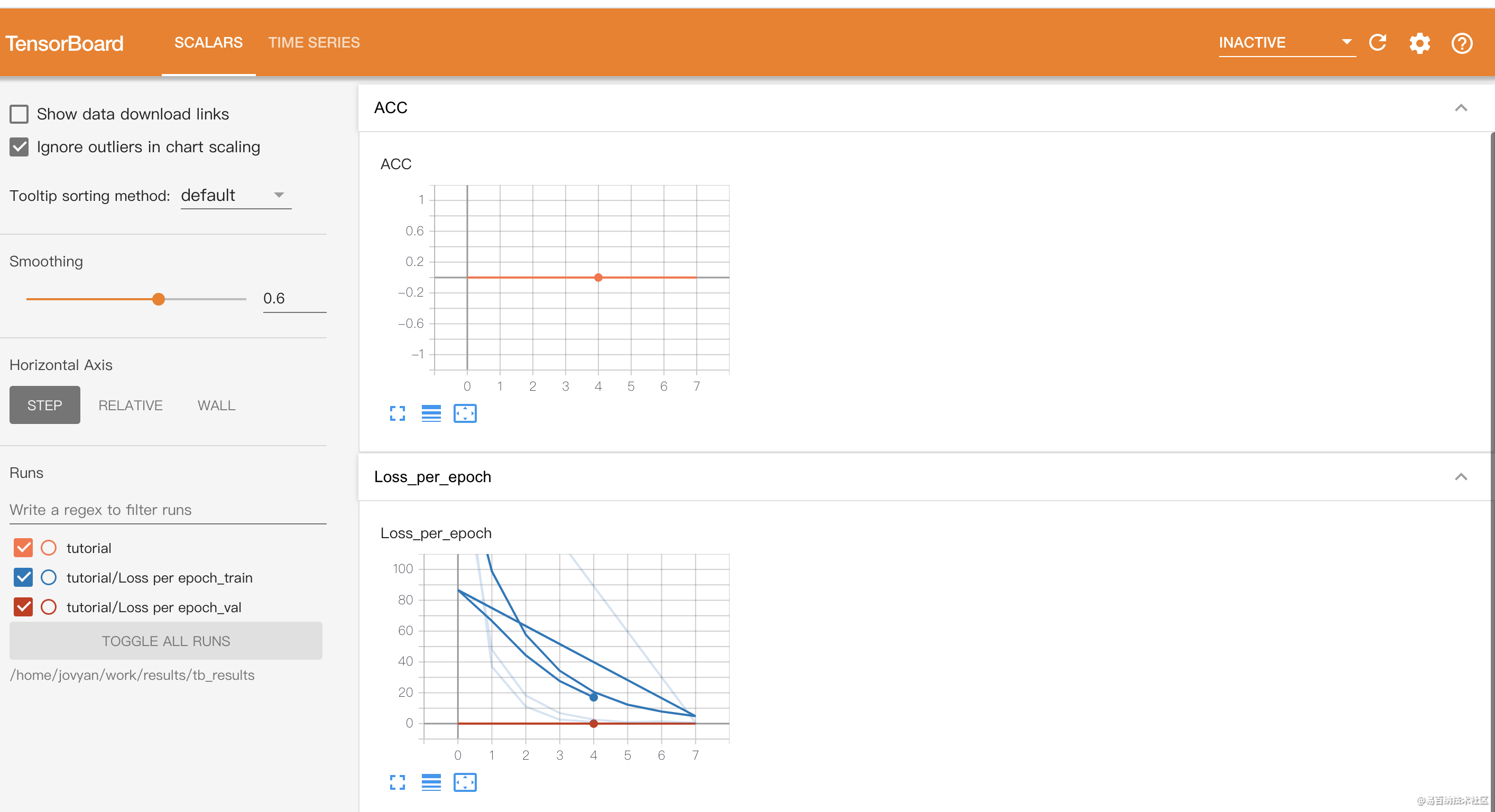
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:157次2023-08-30 15:28:02
-
浏览量:179次2023-08-23 10:15:21
-
浏览量:285次2023-08-02 20:35:16
-
浏览量:6466次2021-07-09 11:16:51
-
浏览量:15072次2021-07-08 09:43:47
-
浏览量:12062次2021-06-25 15:00:55
-
浏览量:8056次2021-06-07 09:27:26
-
浏览量:2148次2023-01-21 10:13:45
-
浏览量:123次2023-08-23 08:46:26
-
浏览量:1453次2023-06-02 17:41:27
-
浏览量:270次2023-07-30 18:35:03
-
浏览量:104次2023-08-30 20:18:28
-
浏览量:6580次2021-07-28 14:21:28
-
浏览量:50547次2021-07-28 14:21:08
-
浏览量:1282次2023-07-05 10:15:58
-
浏览量:2210次2020-08-30 00:47:29
-
浏览量:7282次2021-05-31 17:02:05
-
浏览量:2280次2023-04-13 10:45:45
-
浏览量:267次2023-07-25 11:57:50

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
