

【深度学习】基于弱监督学习处理图像的应用
1 概述
什么是弱监督学习呢?文章里说,弱监督学习可以分为三种典型的类型,不完全监督(Incomplete supervision),不确切监督(Inexact supervision),不精确监督(Inaccurate supervision)。
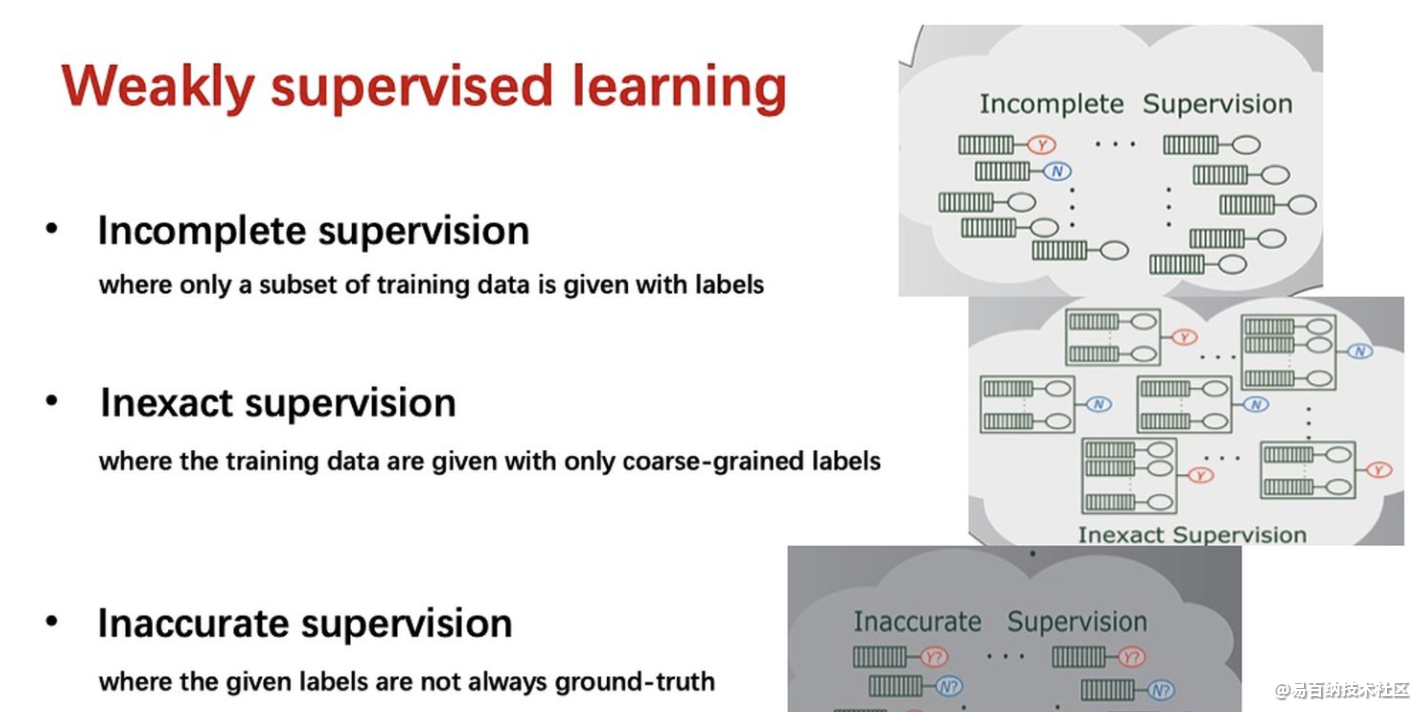
不完全监督是指,训练数据中只有一部分数据被给了标签,有一些数据是没有标签的。
不确切监督是指,训练数据只给出了粗粒度标签。我们可以把输入想象成一个包,这个包里面有一些示例,我们只知道这个包的标签,Y或N,但是我们不知道每个示例的标签。
不精确监督是指,给出的标签不总是正确的,比如本来应该是Y的标签被错误标记成了N。
我们还是用最简单的西瓜的例子来直观理解一下这三者的区别。
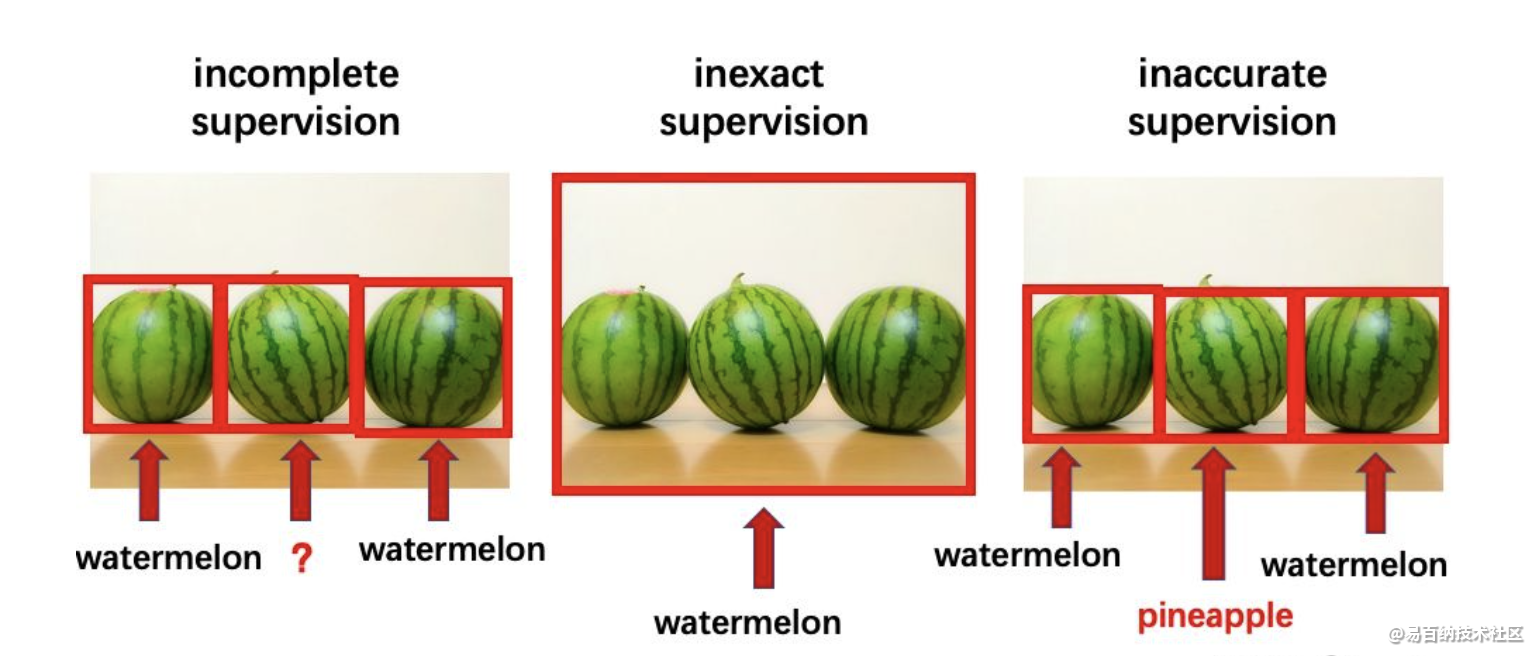
中间的是不确切监督。对于这种情况,我们可以把这个想象成一个包,只知道这里面有西瓜,但是不知道西瓜在哪个位置,也不知道有几个,这种情况叫不确切监督。
最右边的是不精确监督。即假设我们有一些西瓜,但是有一些被错误标注为菠萝,那我们称之为不精确监督。
我们将分别对待这些类型的弱监督学习,但值得一提的是,在实际操作中,它们经常同时发生。

实际上,弱监督学习普遍存在。
比如,在图像分类任务中,训练数据的Groud-Truth标签由人类注释者给出; 虽然很容易从互联网上获取大量图像,而由于人工成本,只能注释一小部分图像。(不完全监督)
在重要目标检测中,我们常常仅有图片级标签,而没有对象级标签。(不确切监督)
在众包数据分析中,当图像标记者粗心或者疲倦时,或者有些图片很难去分类时,这将会导致一些标签被标记错误。(不精确监督)
2 常用的弱监督分割算法
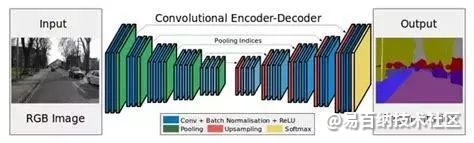
说完了基本概念和必要性,下面我们从输入的角度具体聊一下常用的弱监督分割算法有哪些。在分割任务中,常用的分割网络有AlexNet、VGG、GoogleNet、ResNet和ReNet等,且通常借助迁移学习和必要的数据处理及扩张实现较好的分割。这些方法和结构在弱监督分割算法中也非常常见。具体而言,分割任务中常用的方法有译码器(decoder)的变体;整合上下文信息的方法,如条件随机场、扩张卷积、多尺度估计、特征融合等。
下图就是一个典型的编码器-解码器结构。
考虑到关于分割算法的综述有许多,本文着重介绍弱监督分割算法中特殊的处理方法。针对不同任务需求,每种输入下的算法都按照语义分割、实例分割进行归纳(前景分割被归入语义分割中);而全景分割要同时完成两种分割任务,因此单独列出来。总体上,目前弱监督的语义分割研究成果比较多,但是实例分割与全景分割则要少很多。由于论文数量庞大,这里每种场景仅列出一篇有代表性的论文作为范例。
2.1 基于image-level tags的分割算法
Image-level tags已经在前文给出了示例,可以看出这一种标注中主要包含的是相同类别之间的共性,但无法区分实例(比如所有的车都会被标注成“车”,而不会区分颜色、形状、大小、牌子等等)。因此基于image-level tags的算法大多用于语义分割,或是具有语义分割功能的实例分割或全景分割算法。下面就按照分类介绍部分基于image-level tags的深度学习分割算法。
《Built-in Foreground/Background Prior for Weakly-Supervised Semantic Segmentation》
这篇论文中提出的方法,是利用目标标签作为语义分割训练的先验,从而实现更高精度的分割效果。为了实现这个目的,这个方法中构建了一个预训练网络,其作用是给出前景像素点信息,而忽略背景信息。
下图是具体的网络结构。给定输入图像,网络经过了一个典型的编码器-解码器结构,随后通过一个条件随机场(CRF)生成最后的mask。整个网络的训练只需要image-level tags就可以。
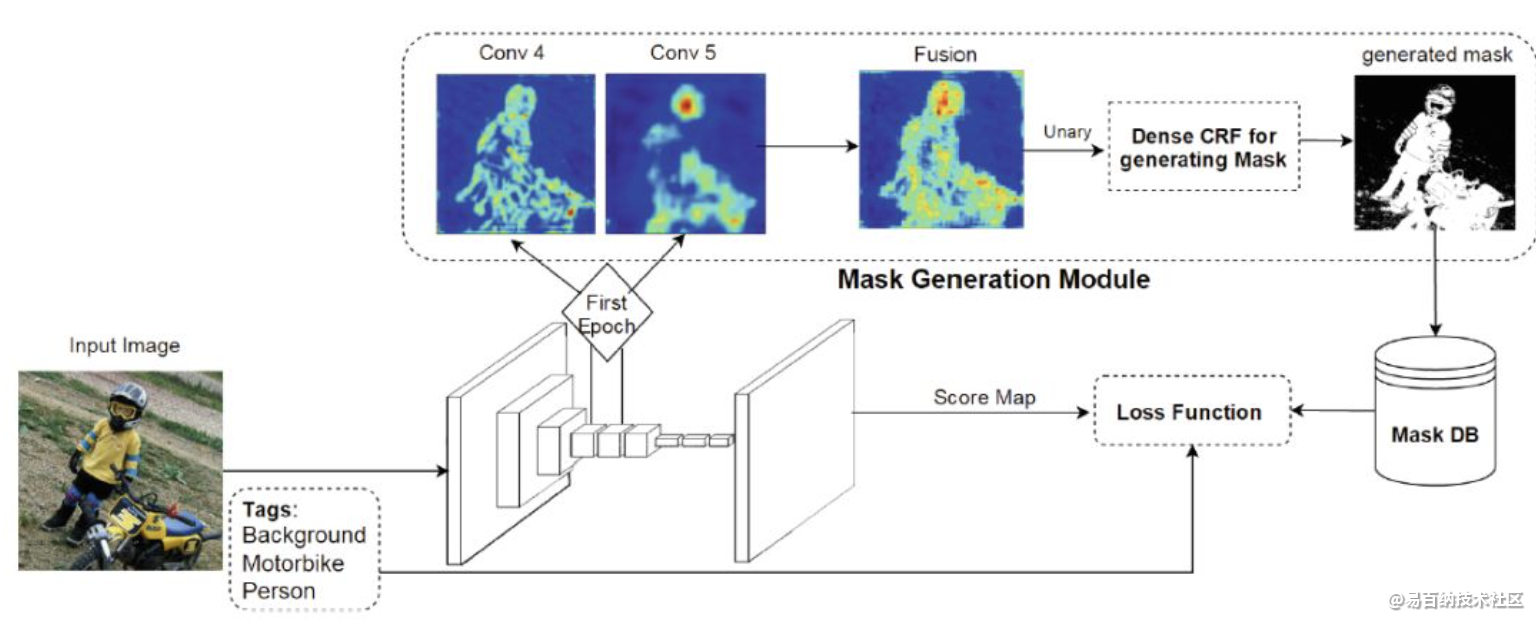
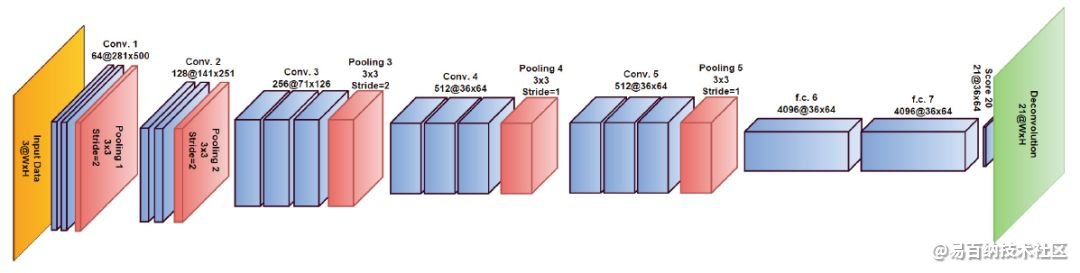
上图是编码器-解码器神经网络部分的完整结构,图片来源于论文。该网络结构是从VGG-16网络结构来的,感受野128,步长8。
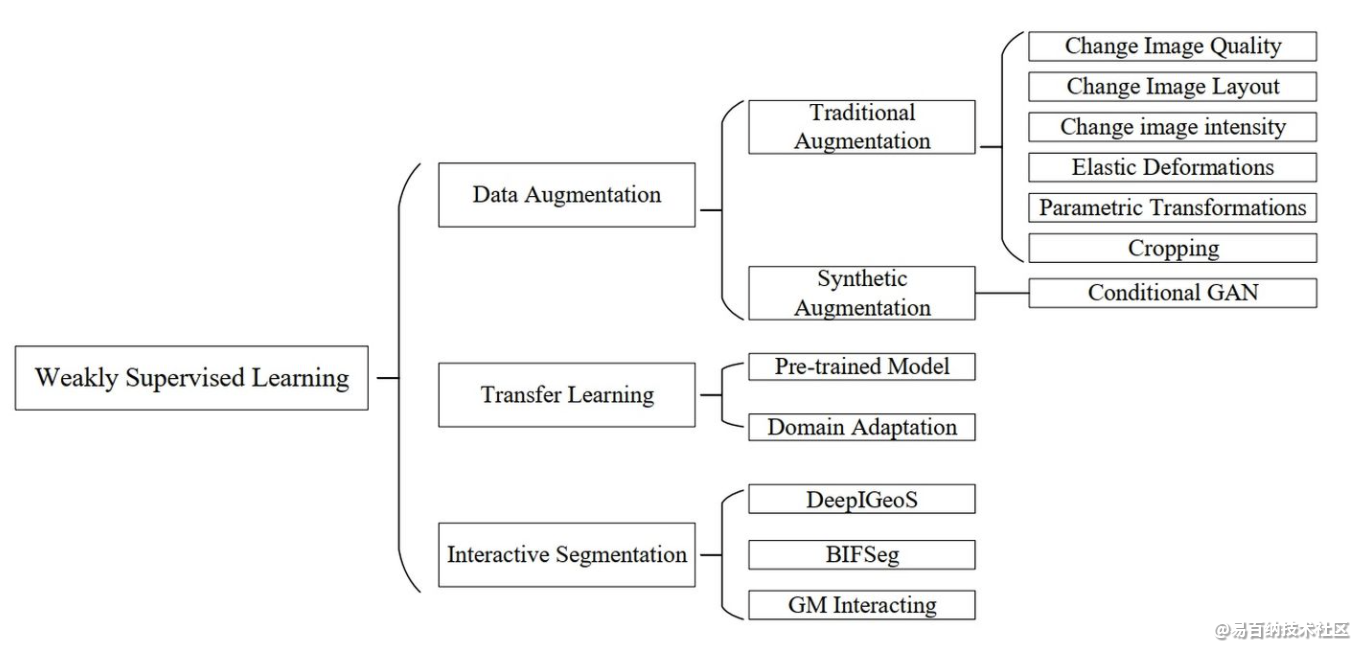
2.2 弱监督学习医学图像分割
对于弱监督学习方法,我们分别根据数据增广,迁移学习和交互式分割来研究文献。
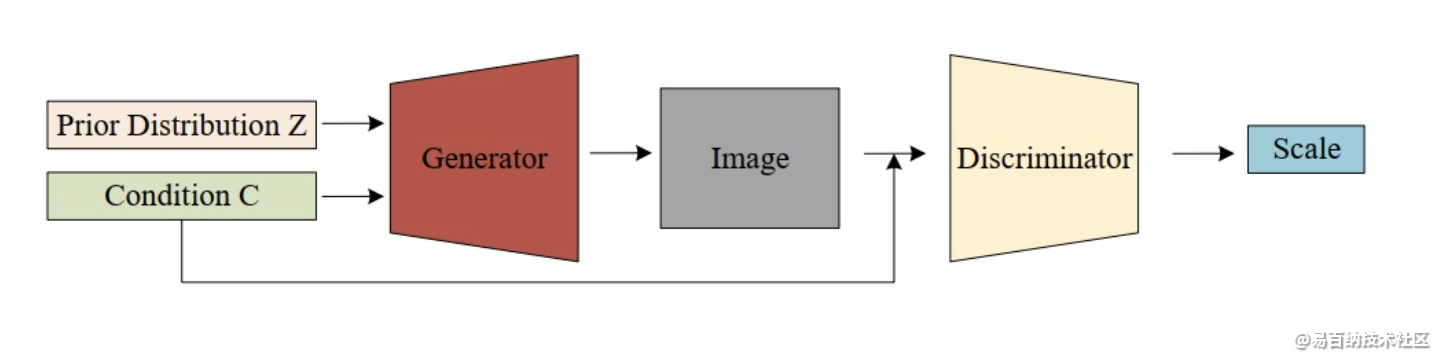
3 实例分割
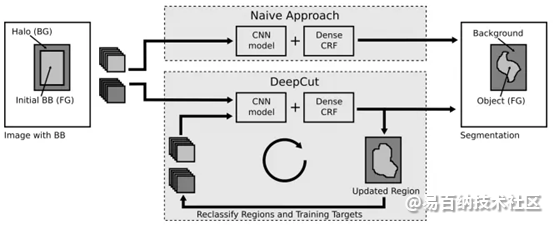
《DeepCut: Object Segmentation from Bounding Box Annotations using Convolutional Neural Networks》
文中提出了一种给定弱标注的实例分割方法。将微软研究院提出的迭代图割-GrabCut进行扩展,可以实现给定bounding boxes的神经网络分类器训练。该文将分类问题视为在稠密连接的条件随机场下的能量最小化问题,并通过不断迭代实现实例分割。
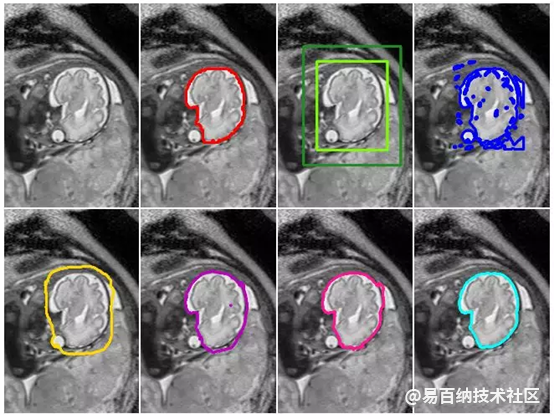
文中还提出了一些DeepCut方法的变体,并将它们与其它算法在弱监督条件下进行了比较。值得注意的是,该算法在解决大脑和肺的两个问题上已经得到了实验,精度还不错(使用的数据库是fetal magnetric resonance dataset)。下图是基本的DeepCut网络结构:
下图是实验结果:
4 弱监督图像语义分割文献
转:https://zhuanlan.zhihu.com/p/341198853
一. 研究背景
在当前图像语义分割的深度学习方法中大绝大多数是基于有监督的,即告诉机器训练图像中每一个像素对应的正确的类别。这样的方法固然能取得很好的效果,但数据标注的成本是极其高昂的。比如,对于PASCAL VOC数据集,需要十余工人来标注27374个bounding box(标注框),而对于ImageNet甚至需要25000名人员对上千万张数据进行标注。MIT的Antonio Torralba曾经在CVML会议上讲过一个非常有意思的故事,他的退休的母亲帮他做了20余万分割目标的精细标注,他开玩笑说希望有更多的父母参与到这份工作中来。那有没有一个方法可以只给机器一点提示就能让它学会分割出图像中不同的实体。比如我只告诉它这幅图里由背景、狗和人,那它能不能依靠这些线索把这三类从图像中分割出来.弱监督学习应运而生。弱监督是指为实现某个计算机视觉任务,采用了比该任务更弱的一种人工标注作为监督信息。一般来讲,这种弱监督的标注比原始的标注更容易获取。例如,对于目标检测任务,image-level(图像层面)的标签相比物体的bounding box是一种弱监督的标注;对于语义分割任务,image-level的标签和物体的bounding box相比pixel-level(像素层面)的标签则是一种弱监督的标注。据统计,从2013年至今,“weak”作为关键词在计算机视觉的三大顶会上(ICCV,ECCV,CVPR)发表的论文数量逐渐增加,“弱监督”也受到了越来越多的关注。
二. 所选论文介绍
本篇综述选取的十篇文章均是与弱监督学习有关的,应用主要集中在语义分割、物体识别领域。他们有的使用了形态各异的弱监督信息:Suha Kwak, Seunghoon Hong等人使用超体素作为标注信息,构筑了网络SPN(Superpixel Pooling Network), 通过图像级别的超体素信息来对特征图谱进行处理,得到低级别的图像结构信息和语义特征,从而用来进行后续的语义分割[2];Jiwoon Ahn等人设计了一个深度神经网络AffinityNet 用来获取像素之间的关系,而这个网络训练所需要的标签只是简单的几个点和点之间的连接线(用来表示图像中的物体间的联系),再使用这个网络来得到所需分割的图像的标签并用于该图像的分割[3];有的提出了新颖的基于弱监督学习的方法:Weifeng Ge等人在他们的论文中提出了一种应用于多标签分类、物体识别以及语义分割的新方法——多证据过滤与融合。具体的流程包括:物体定位,过滤和融合物体实例,像素标签获取和特定任务网络训练[4];Zilong Huang等人将传统的语义分割的方法——Seeded region growing引入到弱监督学习中,实现了非常出色的效果[5];Fatemeh Sadat Saleh等人针对图像分割中存在的多背景问题,使用分类器热图(heatmaps)来设计损失函数训练深度神经网络,该网络在youtube视频数据集上取得了不错的成绩[6];Xiang Wang等人提出了一种方法通过迭代不断挖掘待分割物体的特征,分割的效果随着迭代不断变好[8];Yanzhao Zhou等人为了获取物体实例的位置信息用作弱监督信息,利用了图像的类别峰值响应(Class Peak Response)[9]。也有作者提出了对弱监督学习影响深远的理论:等人提出的非局部神经网络(Nonlocal Neural Network),针对传统卷积操作只能捕获局部信息的缺陷提出了一种非局部的操作,能够使用更大范围的信息帮助网络对学习到的图像特征进行优化,最终得到更加精细的结果[7];Yunchao Wei等人深入探讨研究了孔洞卷积(Dilated Convolution)在弱监督学习中的可用性,并且提出了使用孔洞卷积来获取紧密的物体定位图谱(dense localization map)的深度学习网络[1]。这些文章对弱监督学习的发展作出了巨大的贡献,是我们进行这方面研究的基础。
三. 论文分析
- Revisiting Dilated Convolution: A Simple Approach for Weakly- and SemiSupervised Semantic Segmentation
1.1 论文背景与研究动机
尽管弱监督语义分割已经取得了突出的进展,但相比于全监督的语义分割,弱监督语义分割效果依然不理想。作者观察到这其中的效果差距主要来自于仅仅依靠图像级别的标注,无法得到密集完整的像素级别的物体位置信息用来训练分割模型。本文重新探索空洞卷积并且阐明了它如何使分类网络生成密集的物体定位信息。通过依靠不同的倍率的空洞卷积来显著增大卷积核的感受野,分类网络能定位物体的非判别性区域,最终产生可靠的物体区域,有助于弱监督和半监督的语义分割。尽管该方法过程简单,但是能取得目前最高的语义分割性能。具体地说,该方法在弱监督语义分割和半监督语义分割的情况下,在 Pascal VOC 2012 测试集上能达到目前最高的 60.8% 和 67.6% mIOU.
1.2 论文实现方式
使用多种尺寸的卷积模块的训练网络结构如下图所示:
图1. 原论文网络结构图
同时,作者通过实验观察到:通过改变卷积核的扩张速率,可以将信息从最初的判别区域转移到其他区域, 可以利用不同扩张率的多卷积块来生活来生成密集的对象定位图。再利用这种密集定位图用于弱监督语义分割网络.
图2 不同扩张率的结果
1.3 论文总结
这篇论文重新审视了孔洞卷积,并提出利用不同扩张率的多个卷积块来生成密集的对象定位图。这种方法易于实现,并且生成的密集定位图可用于以弱或半监督的方式学习语义分段网络。
- Weakly Supervised Semantic Segmentation Using Superpixel Pooling Network
2.1 论文背景与研究动机
这篇论文提出了一种基于深度神经网络的弱监督语义分割算法,该算法仅依赖于图像级类标签。所提出的算法在生成分割注释和使用生成的注释学习语义分割网络之间交替。该框架成功的关键决定因素是仅在给定图像级标签的情况下构建可靠初始注释的能力。为此,我们提出了超像素池化网络(SPN),它利用输入图像的超像素分割作为汇集布局,以反映用于学习和推断语义分割的低级图像结构。然后,使用由SPN生成的初始注释来学习估计像素方式语义标签的另一神经网络。分段的体系结构网络将语义分割任务分解为分类和分割,以便网络在嘈杂的注释之前学习类别不可知的形状。事实证明,两个网络对于提高语义分割准确性至关重要。与具有挑战性的PASCAL VOC 2012分割基准的现有技术相比,所提出的算法在弱监督语义分割任务中实现了出色的性能。
2.2 论文实现方式
SPN的网络架构如下所示。首先包括一个卷积部分,使用的是VGG16的卷积部分,生成特征图
.这部分网络的参数是在ImageNet上pre-trained的模型参数,并且在训练的过程中, 这部分参数保持不变。生成的feature map分成两个分支,下面那个分支直接使用GAP(Global Average Pooling), 每类生成一个class-level的prediction;对于上面那个分支,不能直接使用Superpixel Pooling,因为生成的feature map太小了,所以先有一个upsample的模块,然后在这个基础上做Superpixel Pooling.通过轮流使用一个网络的结果作为另外一个网络的输入来依次训练,经过几次迭代,最终可以得到期望的结果。
图3 原论文网络结构图
2.3 论文总结
这篇文章的主要贡献在于提出了SPN(Superpixel Pooling Network),用来生成初始语义分割的标记。SPN的一个特点是它利用了图像的low-level structure information。
- Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
3.1 论文背景与研究动机
分割标签的不足是图像语义分割的主要障碍之一。为了缓解这个问题,我们提出了一种新颖的框架,可以根据图像级别的标签生成图像的分割标签。在这种弱监督的环境中,已知训练的模型将局部判别部分而不是整个对象区域分割。我们的解决方案是将这种本地响应传播到属于同一语义实体的附近区域。为此,我们提出了一种名为AffinityNet的深度神经网络(DNN),它可以预测一对相邻图像坐标之间的语义关联。然后通过AffinityNet预测的亲和力随机游走来实现语义传播。更重要的是,用于训练AffinityNet的监督由初始判别部分分割给出,其作为分割注释是不完整的,但足以用于学习小图像区域内的语义关联。因而整个框架仅依赖于图像级类标签,不需要任何额外的数据或注释。在PASCAL VOC 2012数据集中,通过该论文的方法生成的分段标签学习的DNN优于之前使用相同监督级别训练的模型,甚至与依赖于更强监督的模型相比具有竞争力。
3.2 论文实现方式
论文方法的流程如下图所示,对象类和背景的显着区域首先由CAMs(Class Activation Maps)定位在训练图像中。 从显着区域,我们采样成对的相邻坐标,并根据它们的类一致性为它们分配二进制标签。 然后使用标记的对来训练AffinityNet。经过训练的AffinityNet反过来预测局部图像区域内的语义联系,这些区域与随机游走(Random Walk)结合以修改CAM并生成分割用的label,最后将这些label用来进行语义分割。
图4 原论文方法实现过程
3.3 论文总结
这篇论文利用简单的关联性标注信息,训练出一个网络用来学习这种关联性,之后再集合图论中的随机游走理论可以得到非常准确的图像标注,然后就可以用有监督的方式,输入图像和对应生成的标注进行图像的语义分割。
- Multi-Evidence Filtering and Fusion for Multi-Label Classification, Object Detection and Semantic Segmentation Based on Weakly Supervised Learning
4.1 论文背景与研究动机
监督对象检测和语义分割需要对象甚至像素级标注。当仅存在图像级标签时,弱监督算法难以实现准确的预测。顶级弱监督算法所达到的准确度仍远低于有监督的算法。该文提出了一种新的弱监督课程学习流程,用于多标签对象识别,检测和语义分割。在这个流程管道中,作者首先获得训练图像的中间对象定位和像素标记结果,然后使用这些结果以完全监督的方式训练任务特定的深度网络。整个过程包括四个阶段,包括训练图像中的对象定位,过滤和融合对象实例,训练图像的像素标记以及任务特定的网络训练。为了在训练图像中获得干净的对象实例,这篇论文提出了一种新的算法,用于对从多个解决方案中收集的对象实例进行过滤,融合和分类机制。此算法结合了度量学习和基于密度的聚类来过滤检测到的对象实例。实验表明,弱监督管道在多标签图像分类以及弱监督对象检测方面取得了最新成果,在弱监督语义分割方面取得了非常有竞争力的结果。
4.2 论文实现方式
论文提出的方法的流程如下图所示,在图像级别阶段,融合物体的热图(heat map)和图像注意力图(Attention Map)以生成用于实例级别阶段的对象实例R,并提供这两个用于在像素级阶段进行信息融合的图;在实例级阶段,对异常值检测执行基于三元组丢失的度量学习和基于密度的聚类,并训练单个标签实例分类器以进行例如过滤。在像素级阶段,整合物体的热图,实例注意力图和图像注意力图生成具有不确定性的像素标注。一旦使用上述网络重新标记了训练图像中具有不确定标签的所有像素用于语义分割,就可以在这些中生成对象实例。通过计算连接像素的边界框来生成图像共享相同的语义标签。
图5 原论文方法实现过程
4.3 论文总结
这篇文章提出了一种新的弱监督对象识别,检测和分割流程。 与以前的算法不同,融合和过滤来自不同方法的对象实例并执行具有不确定性的像素标记。最后,使用生成的像素级标注生成用于对象检测的标准框和用于多标签分类的注意力映射。
- Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing
5.1 论文背景与研究动机
本文研究了仅使用图像级标签作为监督来学习图像语义分割网络的问题,这很重要,因为它可以显着减少人类的注释工作。最近关于该问题的最新方法首先使用深度分类网络推断每个对象类的稀疏和判别区域,然后使用判别区域作为监督来训练语义分割网络。受传统的种子区域生长的传统图像分割方法的启发,本文提出从判别区域开始训练语义分割网络,逐步增加种子区域生长的像素级监督。种子区域增长模块集成在深度分割网络中,可以从深层特征中受益。与具有固定/静态标签的传统深度网络不同,所提出的弱监督网络使用图像内的上下文信息生成新标签。所提出的方法明显优于使用静态标签的弱监督语义分割方法,并获得最先进的性能,其在PASCAL VOC 2012测试集中具有63.2%的mIoU分数,在COCO数据集上具有26.0%的mIoU分数。
图6 原论文网络结构图
5.2 论文实现方式
论文方法的流程如图6所示,深度种子区域生长(Deep Seed Region Growing)模块采用种子线索和CNN输出的概率图谱作为输入产生更多的像素监督信息,使其比种子线索更准确和更完整。方法在细化像素监督和优化分割网络的参数之间进行迭代,不断提高网络的分割性能。
5.3 论文总结
论文文只通过使用图像级的标注即可得到高质量的种子(seeds)或者区分度分高的物体区域,但是仅仅这样结果还是很粗糙的,作者又提出了一种DSRG训练方法,逐步提高对象区域的质量和范围,并且本身也是对象区域的监督。通过这样,最终可以取得很好的效果。
- Bringing Background into the Foreground:Making All Classes Equal in Weakly-supervised Video Semantic Segmentation
6.1 论文背景与研究动机
像素级注释是昂贵且耗时的。 因此,仅使用图像标签的弱监督可能对语义分割产生重大影响。 近年来,无论是来自单个图像还是来自视频,弱监督语义分割都取得了很大进展。 但是,大多数现有方法旨在处理单个后台类。 在实际应用中,例如自主导航,推理多个背景类通常是至关重要的。 在本文中,我们通过使用分类器热图来介绍这样做的方法。 然后我们发展一个双流深度架构,共同利用外观和运动,并根据我们的热图设计损失来训练它。 实验证明了本文的分类器热图和双流架构在具有挑战性的城市场景数据集和YouTube-Objects基准测试中的优势,均获得了最先进的结果。
6.2 论文实现方式
该篇论文提出的网络结构如下如所示:双流语义分割网络利用图像和光流来提取特征。 这些功能分为两个阶段。 早期可训练的融合,将空间和时间信息对应,以及将得到的时空流与最终预测的外观融合的后期融合。
图7 原论文网络结构图
6.3 论文总结
本文提出了第一个弱监督视频语义分割方法,它考虑了多个前景和后台类。 为此,引入了一个利用光流和RGB图像的双流网络,使用基于分类器热图的损失进行训练。
- Non-local Neural Networks
7.1 论文背景与研究动机
通常的CNN网络模拟人的认知过程,在网络的相邻两层之间使用局部连接来获取图像的局部特性,一般认为人对外界的认知是从局部到全局的,而图像的空间联系也是局部的像素联系较为紧密,而距离较远的像素相关性则较弱。因而,每个神经元其实没有必要对全局图像进行感知,只需要对局部进行感知,然后在更高层将局部的信息综合起来就得到了全局的信息。网络部分连通的思想,也是受启发于生物学里面的视觉系统结构,底层的去捕捉轮廓信息,中层的组合轮廓信息,高层的组合全局信息,最终不同的全局信息最终被综合,但由于采样以及信息逐层传递损失了大量信息,所以传统cnn在全局信息捕捉上存在局限性。 在本文中,将非局部操作呈现为用于捕获远程依赖性的通用构建块系列。 受计算机视觉中经典的非局部均值方法的启发,本文提出的非局部操作将位置处的响应计算为所有位置处的特征的加权和。 该构建块可以插入许多计算机视觉架构中。 关于视频分类的任务,即使没有任何特殊的技巧,本文提出的非局部模型都可以竞争或超越当前的Kinetics和Charades数据集的获胜者。 在静态图像识别中,本文的非局部模型改进了对象检测/分割并对COCO任务组进行姿态估计。
7.2 论文实现方式
作者训练好用于视频分类的一个网络,在时空上进行非局部运算的示例。计算时,位置 Xi 的响应等于时空中所有位置的特征的加权和。注意第一帧里球的位置与后两帧球的关联。
图8 像素关系表示
在本文中,将非局部运算作为一个高效、简单和通用的模块,用于获取深度神经网络的长时记忆。我们提出的非局部运算是计算机视觉中经典的非局部均值运算的一种泛化结果。直观地说,非局部运算将某一处位置的响应作为输入特征映射中所有位置的特征的加权和来进行计算。这些位置可以是空间位置,也可以是时间位置,还可以是时空位置,这意味着我们的计算适用于图像、序列和视频问题。
一个时空非局部组件如下图所示。特征映射被表示为张量,⊗表示矩阵乘法,⊕表示单元和。每一行进行softmax。蓝框表示1×1×1的卷积。图中显示的是嵌入式高斯版本,具有512个通道的瓶颈。
图9 Nonlocal模块
7.3 论文总结
作者在论文中写道,使用非局部运算有几大好处:(a)与递归和卷积运算的渐进的操作相比,非本局部运算直接通过计算任意两个位置之间的交互来获取长时记忆,可以不用管其间的距离;(b)正如他们在实验中所显示的那样,非局部运算效率很高,即使只有几层(比如实验中的5层)也能达到最好的效果;(c)最后,他们的非局部运算能够维持可变输入的大小,并且能很方便地与其他运算(比如实验中使用的卷积运算)相组合。
- Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features
8.1 论文背景与研究动机
图像标签监督下的弱监督语义分割是一项具有挑战性的任务,因为它直接将高级语义与低级别外观相关联。为了弥合这一差距,在本文中,我们提出了一个迭代的自下而上和自上而下的框架,它可以扩展对象区域并优化分割网络。我们从分类网络产生的初始本地化开始。虽然分类网络只响应小而粗略的判别对象区域,本文认为,这些区域包含有关对象的重要共同特征。因此,在自下而上的步骤中,从初始本地化中挖掘常见对象特征,并使用挖掘的特征扩展对象区域。为了补充非判别区域,然后在贝叶斯框架下考虑显着性图以细化对象区域。然后在自上而下的步骤中,精制对象区域用作监督以训练分割网络并预测对象掩模。这些对象蒙版提供更准确的本地化并包含更多对象区域。此外,本文还将这些对象蒙版作为初始定位并从中挖掘出常见的对象特征。迭代地进行这些过程以逐步产生精细对象掩模并优化分割网络。 Pascal VOC 2012数据集的实验结果表明,所提出的方法大大超过了以前最先进的方法。
8.2 论文实现方式
本文提出的MCOF(Mining Common Object Features)框架如下图所示,具体的流程为:首先(t==0),我们从初始对象种子中挖掘出常见的对象特征。 我们将(a)图像分割成(b)超像素区域,并用(d)初始对象种子训练(c)区域分类网络RegionNet。 然后,我们使用经过训练的RegionNet重新预测训练图像区域以获得对象区域。 虽然对象区域可能仍然只关注对象的判别区域,但我们通过(e)显着引导的细化来获得(f)精细对象区域。 然后使用细化的对象区域来训练(g)PixelNet。 通过训练有素的PixelNet,我们重新预测(d)训练图像的分割掩模,然后将它们用作监督训练RegionNet,并且迭代地进行上述过程。 通过迭代,可以挖掘更精细的对象区域,并在最后一次迭代中训练的PixelNet用于推理。
图10 论文方法实现过程
8.3 论文总结
这种迭代的自下而上和自上而下的框架,它通过迭代挖掘来自对象种子的公共对象特征来容忍不准确的初始定xingyun位。我们的方法逐步扩展对象区域并优化分割网络。在自下而上的步骤中,从粗略但有辨别力的对象种子开始,我们从它们中挖掘共同的对象特征以扩展对象区域。为了补充非判别对象区域,提出了显着引导细化方法。然后在自上而下的步骤中,这些区域用作监督以训练分割网络并预测分割掩模。预测的分割掩码包含比初始更完整的对象区域,因此可以进一步挖掘它们的常见对象特征。并且迭代地执行过程以逐步地校正不准确的初始定位并且产生用于语义分割的更准确的对象区域。、
- Weakly Supervised Instance Segmentation using Class Peak Response
9.1 论文背景与研究动机
使用图像级标签的弱监督实例分割来取代昂贵的像素级标注,至今仍然是一个需要探索的领域。在本文中,我们通过利用类峰值响应来启用分类网络(例如掩码提取)来解决这一具有挑战性的问题。仅使用图像标签监控,完全卷积方式的CNN分类器可以生成类响应图,其指定每个图像位置处的分类置信度。我们观察到类响应图中的局部最大值(即峰值)通常对应于驻留在每个实例内的强视觉提示。受此启发,我们首先设计一个过程,以激发从类响应图中出现的峰值。然后,出现的峰值被反向传播并有效地映射到每个对象实例的高信息区域,例如实例边界。我们将从类峰值响应生成的上述映射称为峰值响应映射(PRM)。 PRM提供精细详细的实例级表示,即使使用一些现成的方法也可以提取实例掩码。据我们所知,我们首次报告了具有挑战性的图像级监督实例分割任务的结果。大量实验表明,我们的方法还可以提高弱监督的逐点定位以及语义分割性能,并在流行的基准测试中报告最先进的结果,包括PASCAL VOC 2012和MS COCO。
9.2 论文实现方式
下图展示了本文中峰值响应图(PRM)生成和利用。 刺激过程选择性地激活驻留在每个对象内的强视觉线索到类峰值响应。 反向传播过程进一步从结果峰中提取每个实例的精细细节。 最后,一起考虑来自候选的类感知线索,实例感知线索和对象先验,以预测实例掩码mask.
图11 论文方法实现过程
9.3 论文总结
本文提出了一种简单而有效的技术来实现分类网络,例如掩码提取。 基于类峰值响应,峰值刺激显示有效加强对象定位,而峰值反向传播为每个实例提取精细详细的视觉提示。 除此之外。作者还展示了针对逐点定位以及弱监督语义分割的最佳结果。
10.W2F: A Weakly-Supervised to Fully-Supervised Framework for Object Detection
10.1 论文背景与研究动机
弱监督对象检测最近引起了很多关注,因为它不需要用于训练的边界框注释。尽管已经取得了重大进展,但在弱监督和全监督对象检测之间仍然存在很大的性能差距。最近,一些工作使用由弱监督检测器生成的伪地面实况来训练监督检测器。这些方法倾向于找到对象中最具代表性的部分,并且每个类只寻求一个地面实况框,即使存在许多同类实例。为了克服这些问题,本文提出了一种弱监督到全监督的框架,其中使用多实例学习来实现弱监督检测器。然后,这篇论文还提出了一种伪地面实况挖掘(PGE)算法来找到图像中每个实例的伪地面实况。此外,伪地面实况自适应(PGA)算法被设计用于进一步细化来自PGE的伪地面实况。最后,使用这些伪地面实例来训练一个完全监督的探测器。对具有挑战性的PASCAL VOC 2007和2012基准测试的广泛实验有力地证明了我们框架的有效性。本文分别在VOC2007和VOC2012上获得了52.4%和47.8%的mAP,这是对先前最先进方法的显着改进。
10.2 论文实现方式
下图为这篇论文提出的弱监督到完全监督的物体检测框架(W2F)的.给定仅具有图像级标签的图像集合,首先将弱监督深度检测网络(WSDDN)与在线实例分类器细化(OICR)相结合,以训练弱监督检测器,并且这里包括紧密边界框和对象的判别框。 然后,本文提出了一种pseudo ground-truth excavation(PGE)算法来保留那些紧密边界框作为pseudo ground truth,这又用于训练一个监督检测器,其RPN(Faster-RCNN中的区域建议网络)利用 我们提出的pseudo ground-truth adaptation(PGA)算法可以进一步微调ground truth.
图12 论文方法实现过程
10.3 论文总结
与以前的工作不同,我们的框架结合了全监督和弱监督的优势学习。 我们首先使用WSDNN和OICR来训练弱势监督检测器(WSD)端到端。 然后由pseudo ground-truth excavation(PGE)和pseudo ground-truth adaptation(PGA),本文得到方法从WSD中找到高质量的ground truth. 最后,将这些pseudo ground-truth 馈入全监督检测器以产生最终检测结果。
四. 总结
由于图像标签获取费时费力,且成本极高,半监督和弱监督学习势必成为图像语义分割中深度学习方法的主流。在本篇文献综述中,围绕“基于弱监督的图像语义分割”这一主题,选取了十篇最新的相关论文,它们均来自于该领域的顶级会议,例如CVPR,ICCV.这些文章在弱监督思想的指导下,有的结合了传统方法中著名的理论,有的另辟蹊径找到一种方法得到图像的label,再用有监督的方法进行训练,有的研究了对弱监督学习影响深远的理论技巧。 这些都与我的研究生课题有紧密的联系,通过对这些论文的学习,我对自己的课题有了更好的理解,对之后研究的方向有了更清晰的认识,也意识到弱监督学习正在变得越来越重要,能够参与到这个领域的研究学习是多么的幸运。
五. 参考文献
[1] Wei Y, Xiao H, Shi H, et al. Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation. In IEEE CVPR, 2018.
[2] Suha K, SEunghoon H, et al. Weakly Supervised Semantic Segmentation Using Superpixel Pooling Network. In AAAI, 2017.
[3] Ahn J, Kwak S. Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation. In IEEE CVPR,2018.
[4] Weifeng G, Sibei Y, et al. Multi-Evidence Filtering and Fusion for Multi-Label Classification, Object Detection and Semantic Segmentation Based on Weakly Supervised Learning. In IEEE CVPR,2018.
[5] Zilong H, Xinggang W, et al. Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing. In IEEE CVPR,2018.
[6] Saleh F S, Aliakbarian M S, Salzmann M, et al. Bringing Background into the Foreground: Making All Classes Equal in Weakly-supervised Video Semantic Segmentation[C]// IEEE International Conference on Computer Vision. IEEE Computer Society, 2017:2125-2135.
[7] Wang X, Girshick R, Gupta A, et al. Non-local Neural Networks. In IEEE CVPR,2017..
[8] Xiang W, Shaodi Y, et al. Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features. In IEEE CVPR,2018.
[9] Zhou Y, Zhu Y, Ye Q, et al. Weakly Supervised Instance Segmentation using Class Peak Response. In IEEE CVPR,2018.
[10] W2F: A Weakly-Supervised to Fully-Supervised Framework for Object Detection. In IEEE CVPR,2018.
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:17256次2021-07-16 12:56:10
-
浏览量:8518次2021-05-06 12:40:38
-
浏览量:267次2023-07-25 11:57:50
-
浏览量:13904次2021-05-12 12:35:30
-
浏览量:104次2023-08-30 20:18:28
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:7524次2021-06-18 17:21:06
-
浏览量:7306次2021-06-07 09:26:53
-
浏览量:8370次2021-07-19 17:08:40
-
浏览量:33699次2021-07-06 10:18:59
-
浏览量:2121次2023-02-14 14:48:11
-
浏览量:319次2023-07-26 14:33:08
-
浏览量:7811次2021-06-27 18:19:55
-
浏览量:1449次2023-06-02 17:41:27
-
浏览量:5754次2021-08-05 09:20:49
-
浏览量:5624次2021-08-05 09:21:07
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:8411次2021-07-12 11:03:00
-
浏览量:5526次2021-08-02 09:33:43

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
