

【深度学习】基于Pytorch的线性模型概念辨析和实现(一)


文章目录
1 为什么要谈线性回归?
2 建立模型基本形式
3 实现
3.1 损失函数
3.2 解析解
3.3 小批量随机梯度下降
3.4 矢量化加速
3.5 正态分布与平方损失
4 从线性回归到深度网络
5 最大似然估计1 为什么要谈线性回归?
理论层面的重要性
Linear Regression:是回归问题的基础
Logistic Regression:是分类问题的基础
可扩展性:使用基函数来解决非线性问题
应用层面的重要性——在工业中最广泛应用的模型
高效易用(简单、易训练)
可解释性强(参数直接反应特征强弱)
适合预估(概率形式)
资源丰富(开源资料、文档、文献、论文)
很多人包括我在开始学习机器学习的时候都看不上线性回归,觉得这种算法太老太笨,不够 fancy,草草学一下就去看随机森林、GDBT、SVM甚至神经网络这些模型去了。但是上了班才发现线性回归依然是工业界使用最广泛的模型。和学校项目及Kaggle不同的是,工业界尤其是大一点的互联网公司,除了NLP和CV方向,一般缺的不是数据而是算力。同时因为数据量够多,线性回归这种简单的模型也可以产生不错的效果。而使用更复杂的模型不仅速度会大幅下降,准确率也不见得能提高多少。在很多场景下,因为公司没办法根据黑盒模型去做相应的策略,所以业务方也更需要可解释性的模型,如线性回归,决策树,知识图谱等。站在决策者的角度,他们也很难在重大问题上去相信无法解释的模型。所以线性回归,依旧是工业界使用最广泛,效果非常好的模型
2 建立模型基本形式
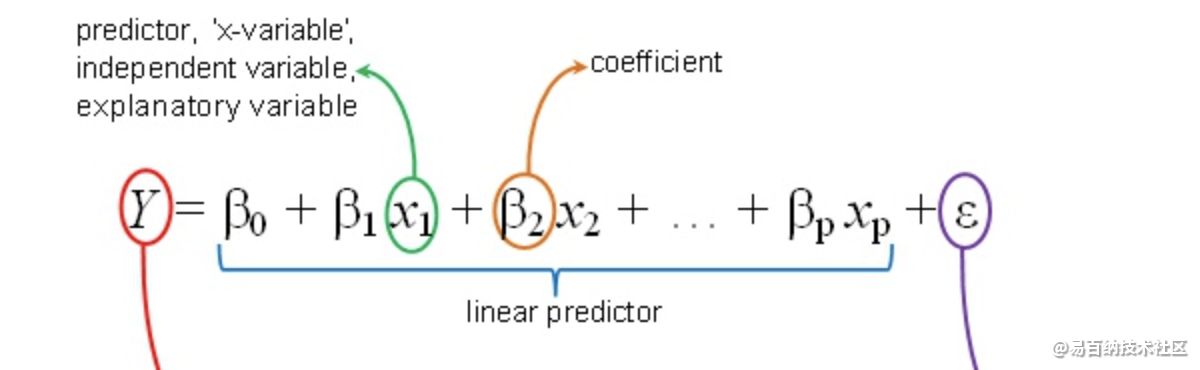
为什么需要b(Bias Parameter):类似于线性函数中的截距,在线性模型中补偿了目标值的平均值(在训练集上的)于基函数值的加权平均值之间的差距。即打靶打歪了,但是允许通过平易固定向量的方式移动到目标点上(每个预测点和目标点之间的偏置都必须是固定的)
3 实现
3.1 损失函数
平方误差可以定义为以下公式:
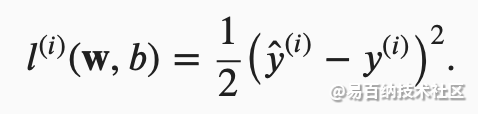
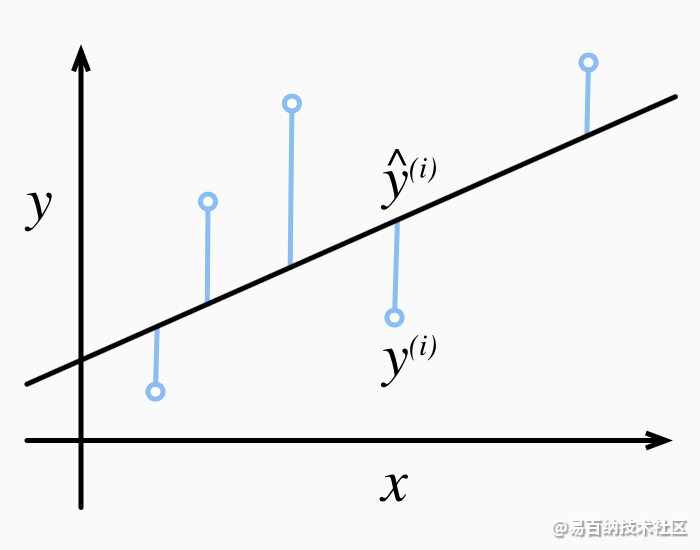
常数1/2不会带来本质的差别,但这样在形式上稍微简单一些,表现为当我们对损失函数求导后常数系数为1。由于训练数据集并不受我们控制,所以经验误差只是关于模型参数的函数。为了进一步说明,来看下面的例子。我们为一维情况下的回归问题绘制图像,如下图所示。
为了度量模型在整个数据集上的质量,我们需计算在训练集 𝑛个样本上的损失均值(也等价于求和)。
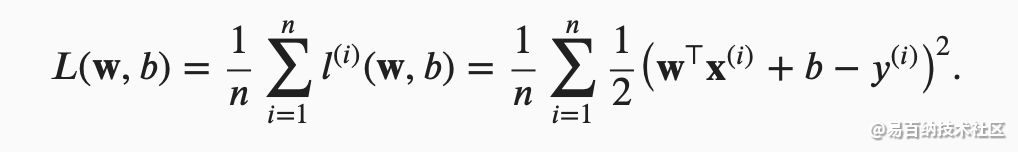
这组参数能最小化在所有训练样本上的总损失。如下式:

3.2 解析解
线性回归刚好是一个很简单的优化问题。与我们将在本书中所讲到的其他大部分模型不同,线性回归的解可以用一个公式简单地表达出来,这类解叫作解析解(analytical solution)。
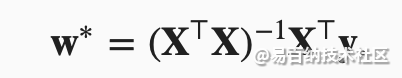
像线性回归这样的简单问题存在解析解,但并不是所有的问题都存在解析解。解析解可以进行很好的数学分析,但解析解的限制很严格,导致它无法应用在深度学习里。
3.3 小批量随机梯度下降
梯度下降最简单的用法是计算损失函数(数据集中所有样本的损失均值)关于模型参数的导数(在这里也可以称为梯度)。但实际中的执行可能会非常慢:因为在每一次更新参数之前,我们必须遍历整个数据集。因此,我们通常会在每次需要计算更新的时候随机抽取一小批样本,这种变体叫做小批量随机梯度下降(minibatch stochastic gradient descent)。
我们用下面的数学公式来表示这一更新过程( ∂表示偏导数):
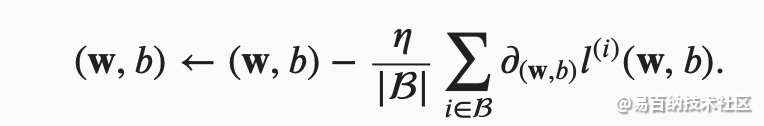
3.4 矢量化加速
在训练我们的模型时,我们经常希望能够同时处理整个小批量的样本。为了实现这一点,需要我们对计算进行矢量化,从而利用线性代数库,而不是在Python中编写开销高昂的for循环。
%matplotlib inline
import math
import time
import numpy as np
import torch
from d2l import torch as d2l
为了说明矢量化为什么如此重要,我们考虑(对向量相加的两种方法)。 我们实例化两个全1的10000维向量。在一种方法中,我们将使用Python的for循环遍历向量。在另一种方法中,我们将依赖对 + 的调用。
n = 10000
a = torch.ones(n)
b = torch.ones(n)class Timer: #@save
"""记录多次运行时间。"""
def __init__(self):
self.times = []
self.start()
def start(self):
"""启动计时器。"""
self.tik = time.time()
def stop(self):
"""停止计时器并将时间记录在列表中。"""
self.times.append(time.time() - self.tik)
return self.times[-1]
def avg(self):
"""返回平均时间。"""
return sum(self.times) / len(self.times)
def sum(self):
"""返回时间总和。"""
return sum(self.times)
def cumsum(self):
"""返回累计时间。"""
return np.array(self.times).cumsum().tolist()现在我们可以对工作负载进行基准测试。
首先,[我们使用for循环,每次执行一位的加法]。
c = torch.zeros(n)
timer = Timer()
for i in range(n):
c[i] = a[i] + b[i]
f'{timer.stop():.5f} sec'
或者,我们使用重载的 + 运算符来计算按元素的和)。
结果很明显,第二种方法比第一种方法快得多。矢量化代码通常会带来数量级的加速。另外,我们将更多的数学的运算放到库中,而无需自己编写那么多的计算,从而减少了出错的可能性。
3.5 正态分布与平方损失
正态分布(normal distribution),也称为 高斯分布(Gaussian distribution)
其正态分布概率密度函数如下:
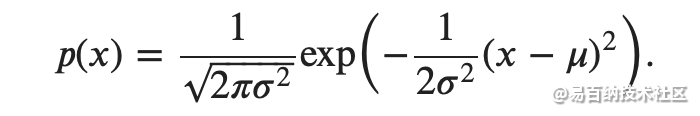
def normal(x, mu, sigma):
p = 1 / math.sqrt(2 * math.pi * sigma**2)
return p * np.exp(-0.5 / sigma**2 * (x - mu)**2)# 再次使用numpy进行可视化
x = np.arange(-7, 7, 0.01)
# 均值和标准差对
params = [(0, 1), (0, 2), (3, 1)]
d2l.plot(x, [normal(x, mu, sigma) for mu, sigma in params], xlabel='x',
ylabel='p(x)', figsize=(4.5, 2.5),
legend=[f'mean {mu}, std {sigma}' for mu, sigma in params])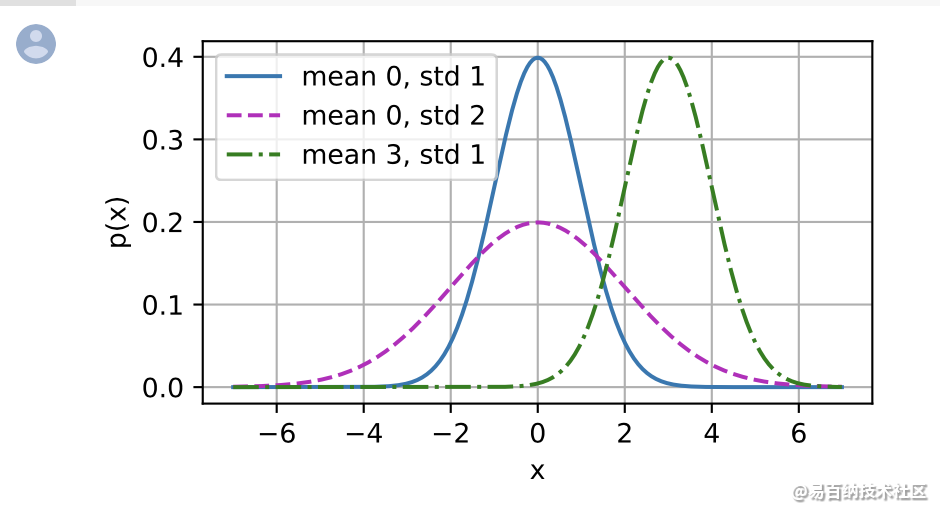
就像我们所看到的,改变均值会产生沿 𝑥 轴的偏移,增加方差将会分散分布、降低其峰值。
均方误差损失函数(简称均方损失)可以用于线性回归的一个原因是:我们假设了观测中包含噪声,其中噪声服从正态分布。噪声正态分布如下式:
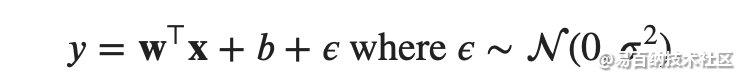

4 从线性回归到深度网络
到目前为止,我们只谈论了线性模型。 尽管神经网络涵盖了更多更为丰富的模型,我们依然可以用描述神经网络的方式来描述线性模型,从而把线性模型看作一个神经网络。 首先,让我们用“层”符号来重写这个模型。
对于线性回归,每个输入都与每个输出(在本例中只有一个输出)相连,我们将这种变换( :numref:fig_single_neuron 中的输出层)称为 全连接层(fully-connected layer)(或称为 稠密层 dense layer)。下一章将详细讨论由这些层组成的网络。
我们可以将线性回归模型视为仅由单个人工神经元组成的神经网络,或称为单层神经网络。
5 最大似然估计
极大似然估计,通俗理解来说,就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值!
换句话说,极大似然估计提供了一种给定观察数据来评估模型参数的方法,即:“模型已定,参数未知”。
可能有小伙伴就要说了,还是有点抽象呀。我们这样想,一当模型满足某个分布,它的参数值我通过极大似然估计法求出来的话。比如正态分布中公式如下:
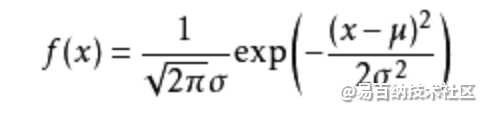
如果我通过极大似然估计,得到模型中参数miu和xigema的值,那么这个模型的均值和方差以及其它所有的信息我们是不是就知道了呢。确实是这样的。
极大似然估计中采样需满足一个重要的假设,就是所有的采样都是独立同分布的。
假设我们要统计全国人民的年均收入,首先假设这个收入服从服从正态分布,但是该分布的均值与方差未知。我们没有人力与物力去统计全国每个人的收入。我们国家有10几亿人口呢?那么岂不是没有办法了?
不不不,有了极大似然估计之后,我们可以采用嘛!我们比如选取一个城市,或者一个乡镇的人口收入,作为我们的观察样本结果。然后通过最大似然估计来获取上述假设中的正态分布的参数。
有了参数的结果后,我们就可以知道该正态分布的期望和方差了。也就是我们通过了一个小样本的采样,反过来知道了全国人民年收入的一系列重要的数学指标量!
那么我们就知道了极大似然估计的核心关键就是对于一些情况,样本太多,无法得出分布的参数值,可以采样小样本后,利用极大似然估计获取假设中分布的参数值。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:6605次2021-08-03 11:36:18
-
浏览量:5630次2021-08-05 09:21:07
-
浏览量:6241次2021-08-02 09:34:03
-
浏览量:5755次2021-08-05 09:20:49
-
浏览量:7303次2021-08-09 16:09:53
-
浏览量:5765次2021-08-13 15:39:02
-
浏览量:5453次2021-08-09 16:10:30
-
浏览量:5870次2021-08-09 16:10:57
-
浏览量:5527次2021-08-02 09:33:43
-
浏览量:8561次2021-08-10 10:06:51
-
浏览量:6621次2021-05-17 16:52:58
-
浏览量:5575次2021-07-26 11:25:51
-
浏览量:6696次2021-07-26 17:43:04
-
浏览量:1362次2023-12-14 16:38:19
-
浏览量:5561次2021-07-26 11:28:05
-
浏览量:20377次2021-07-15 10:45:21
-
浏览量:1688次2024-02-01 14:28:23
-
浏览量:6770次2021-07-30 10:33:41
-
浏览量:13905次2021-05-12 12:35:30

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
