

技术专栏
Python人工智能:使用Keras库实现基于神经网络的噪声分类算法

操作系统为Ubuntu 22.04。
本文设计的总体思路如下图所示:
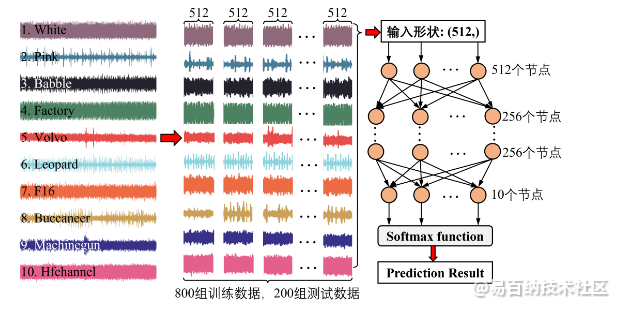
如图所示,本文设计的神经网络结构为:
- (1) 输入节点为512;
- (2) 两个隐含层,且没层的节点数为256;
- (3) 输出节点为10。
一、噪声数据的获取与预处理
1.1 噪声数据集的获取
- (1) 本文使用SPIB开源噪声数据集NoiseX-92中的15种噪声数据进行基于神经网络的噪声分类算法,官方下载下载地址为:Signal Processing Information Base (SPIB),下载的时候需要一个个下载且下载速度比较慢。
- (2) 也可以通过百度网盘下载,
链接:https://pan.baidu.com/s/1FDZ3tMHyLbDPj275hEiuqQ,提取码: ayrr。
1.2 噪声数据的预处理
使用Python对NoiseX-92噪声数据集进行预处理使用了如下四个python库:
- (1) scipy库:使用其中的loadmat方法用于提取.mat格式文件中的噪声数据;
- (2) sklearn库:主要使用其中的StandardScaler方法用于实现数据的正则化处理;以及train_test_split方法将数据划分训练集与测试集;
- (3) numpy库:用于处理数据的获取与存储方式。
本文选取其中10种噪声为分析对象,噪声数据预处理代码:
from scipy.io import loadmat
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import numpy as np
def noise_data_pro(
length=1024, # 每个样本的信号长度
number=100, # 每种信号的样本数
enc_step=28 # 每次增强时候的步长
):
# 读取噪声数据,并存储在files字典中
files = {}
# 依次读取NOISEX-92_mat文件夹中的.mat格式的噪声数据
# (1) 白噪声数据的获取
white = loadmat('./NOISEX-92_mat/white.mat')
files['white'] = white['white'].ravel()
# (2) 粉噪声数据的获取
pink = loadmat('./NOISEX-92_mat/pink.mat')
files['pink'] = pink['pink'].ravel()
# (3) babble噪声数据的获取
babble = loadmat('./NOISEX-92_mat/babble.mat')
files['babble'] = babble['babble'].ravel()
# (4) factory噪声数据的获取
factory = loadmat('./NOISEX-92_mat/factory1.mat')
files['factory'] = factory['factory1'].ravel()
# (5) volvo噪声数据的获取
volvo = loadmat('./NOISEX-92_mat/volvo.mat')
files['volov'] = volvo['volvo'].ravel()
# (6) leopard噪声数据的获取
leopard = loadmat('./NOISEX-92_mat/leopard.mat')
files['leopard'] = leopard['leopard'].ravel()
# (7) f16噪声数据的获取
f16 = loadmat('./NOISEX-92_mat/f16.mat')
files['f16'] = f16['f16'].ravel()
# (8) buccaneer噪声数据的获取
buccaneer = loadmat('./NOISEX-92_mat/buccaneer1.mat')
files['buccaneer'] = buccaneer['buccaneer1'].ravel()
# (9) machinegun噪声数据的获取
machinegun = loadmat('./NOISEX-92_mat/machinegun.mat')
files['machinegun'] = machinegun['machinegun'].ravel()
# (10) hfchannel噪声数据的获取
hfchannel = loadmat('./NOISEX-92_mat/hfchannel.mat')
files['hfchannel'] = hfchannel['hfchannel'].ravel()
keys = files.keys() # 得到files字典的键值
Train_Samples = {} # 所有训练噪声数据样本的暂存字典
# 使用随机滑动的方法分别将10种噪声切分为number个样本,
# 且每个样本的长度为length,滑动的步长为enc_step。
for i in keys:
slice_data = files[i] # 读取每种噪声数据的序列
all_lenght = len(slice_data) # 获取每种噪声数据的长度
end_index = int(all_lenght) # 获得每种噪声数据的结束位置
samp_train = int(number) # 每个样本的噪声信号长度
Train_sample = [] # 存放每种噪声数据的列表
# 随机滑动获得噪声数据切片
enc_time = length // enc_step
samp_step = 0
for j in range(samp_train):
random_start = np.random.randint(
low=0, high=(end_index - 2*length)
)
label = 0
for h in range(enc_time):
samp_step += 1
random_start += enc_step
sample = slice_data[random_start:random_start+length]
Train_sample.append(sample)
if samp_step == samp_train:
label = 1
break
if label:
break
Train_Samples[i] = Train_sample
x_train = [] # 训练数据
y_train = [] # 训练数据标签
label = 0
# 以0-9来表示10种噪声数据的标签
for i in Train_Samples.keys():
x = Train_Samples[i]
x_train += x
lenx = len(x)
y_train += [label] * lenx
label += 1
# 使用StandardScaler()方法对噪声数据进行正则化处理
# 注意:此时x_train由list格式数据转变为ndarray格式
x_train = StandardScaler().fit_transform(x_train)
# 将y_train列表格式数据也转换为ndarray格式
y_train = np.array(y_train)
# 下面将数据集划分训练数据集与测试数据集
X_train, X_test, y_train, y_test = train_test_split(
x_train, y_train,
test_size=0.2 # 训练数据集与测试数据集的比例为8:2
)
# 返回值:
# (1) 训练数据集: X_train, y_train
# (2) 测试数据集: X_test, y_test
# (3) 噪声数据标签:keys
return X_train, X_test, y_train, y_test, keys将上述代码存放到如下图所示的noise_data_pro.py文件中,并将下载的NOISEX-92噪声数据聚集放入到同样的目录下。

在test.ipynb中输入如下所示的代码且输出结果如下图所示:
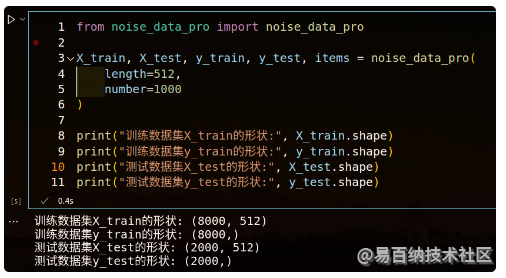
调用上面的数据预处理方法如下图所示:
二、基于Keras的神经网络噪声分类算法实现方法
from noise_data_pro import noise_data_pro
import keras
from keras.models import Sequential
from keras.layers import Dense
from keras.utils import np_utils
X_train, X_test, y_train, y_test, items = noise_data_pro(
length=512,
number=1000
)
# 将目标标签y_train、y_test转换为分类数据格式
y_train = np_utils.to_categorical(y_train, 10)
y_test = np_utils.to_categorical(y_test, 10)
# 创建神经网络
model = Sequential()
model.add(Dense(
256,
activation='relu',
input_shape=(512,)
))
model.add(Dense(
256,
activation='relu',
input_shape=(512,)
))
model.add(Dense(10, activation='softmax'))
# 编译模型
model.compile(
loss='categorical_crossentropy',
optimizer='adam',
metrics=['accuracy']
)
# 训练模型
model.fit(
X_train, y_train,
batch_size=128,
epochs=10,
verbose=1,
validation_data=(X_test, y_test)
)
# 评估模型
score = model.evaluate(X_test, y_test, verbose=0)
print("Test loss:", score[0])
print("Test Accuracy:", score[1])代码执行结果如下图所示:
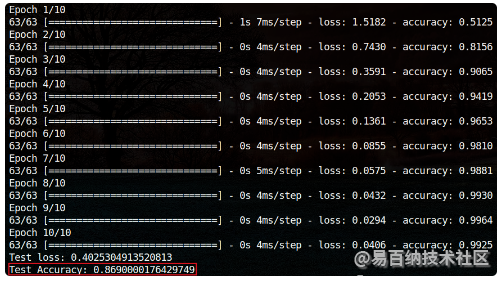
预测精度为86.9。
声明:本文内容由易百纳平台入驻作者撰写,文章观点仅代表作者本人,不代表易百纳立场。如有内容侵权或者其他问题,请联系本站进行删除。
红包
点赞
收藏
评论
打赏
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
评论
0个
手气红包
 暂无数据
暂无数据相关专栏
-
浏览量:1395次2023-09-27 15:48:35
-
浏览量:1225次2023-09-02 09:45:20
-
浏览量:5560次2021-07-26 11:28:05
-
浏览量:393次2023-07-14 14:21:54
-
浏览量:141次2023-08-31 08:46:00
-
浏览量:4764次2021-04-19 14:54:23
-
浏览量:1687次2024-02-01 14:28:23
-
浏览量:5693次2020-12-24 22:06:12
-
浏览量:1292次2023-05-13 21:35:31
-
浏览量:1484次2024-02-22 16:35:06
-
浏览量:1622次2023-09-27 11:34:33
-
浏览量:775次2023-06-08 10:35:09
-
浏览量:7657次2020-12-24 23:03:55
-
浏览量:9306次2021-05-28 16:59:43
-
浏览量:6233次2021-05-28 16:59:25
-
浏览量:267次2023-07-25 11:57:50
-
2020-10-21 14:00:04
-
浏览量:167次2023-08-16 18:03:17
-
浏览量:229次2023-08-03 15:44:04
关于作者
Uncle
暂无个性签名~
原创5
阅读7.3k
收藏0
点赞1
评论0



切换马甲
上一页
下一页
TA最新文章
打赏用户
共 0 位
我要创作
分享技术经验,可获取创作收益
分类专栏
-
5篇
置顶时间设置
结束时间
删除原因
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
打赏作者
Uncle
您的支持将鼓励我继续创作!
打赏金额:
¥1
¥5
¥10
¥50
¥100
支付方式:
 微信支付
微信支付
举报反馈
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
发布时间设置
发布时间:
请选择发布时间设置
是否关联周任务-专栏模块
审核失败
失败原因
请选择失败原因
备注
请输入备注



关注公众号
联系我们
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
回顶部
