

边缘计算系列-YOLOV5在海思HI3516DV300部署

目录
三、Blob(源Blob、输出Blob)和YOLOv3的输出关系
本文目标有两个:
- 海思平台/软件做一个介绍和环境搭建。
- 对例程YOLOv3NNIE前向计算过程的分析。
一、平台/软件介绍和环境搭建
Hi3516DV300 作为新一代行业专用 Smart HD IP 摄像机 SOC,集成新一代 ISP、业界最新的 H.265 视频压缩编码器,同时集成高性能 NNIE 引擎,使得 Hi3516DV300 在低码率、高画质、智能处理和分析、低功耗等方面引领行业水平。
SVP(Smart Vision Platform)是海思媒体处理芯片智能视觉异构加速平台。该平台包含了CPU、DSP、NNIE(Neural Network Inference Engine)等多个硬件处理单元和运行在这些硬件上 SDK 开发环境,以及配套的工具链开发环境。
NNIE(Neural Network Inference Engine)是海思媒体SoC中专门针对神经网络特别是深度学习卷积神经网络进行加速处理的硬件单元。目前NNIE配套软件及工具链仅支持以Caffe框架,且以Caffe-1.0版本为基础。使用其他框架的网络模型需要转化为Caffe框架下的模型。
nnie_mapper,简称mapper,该工具将用户通过开源深度学习框架训练得到的模型转化成在Hi35xx芯片上或者在仿真库中可以加载的数据指令文件(*.wk)。
RuyiStudio集成windows版的NNIE mapper、Runtime mapper和仿真库,具有生成NNIE wk功能、Runtime wk功能和仿真NNIE功能,同时具有代码编辑、编译、调试、执行功能、网络拓扑显示、目标检测画框、向量相似度对比、调试定位信息获取等功能。
查看《指南》可知,YOLOv3中的特殊网络层(如Shortcut、Route、Upsample等)都已经被SVP工具支持(或可被类似功能网络层替换),这极大地方便了我们的移植,但如果想获得更高的性能,则必须进行二次开发,详见后文。在Windows平台上仿真网络模型所需的RuyiStudio和Mapper、仿真库之间的关系如下图1-1所示:
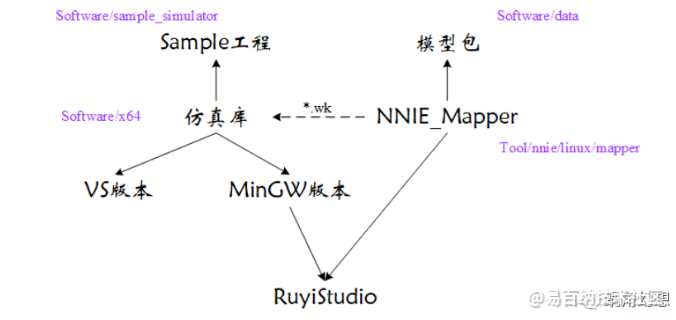
图1-1 SVP-NNIE工具关系图
RuyiStudio环境搭建
具体的安装步骤可以分为:
(1)安装wget-1.11.4-1-setup.exe
(2)解压MinGW-w64-x86_64-7.3.0-release-posix-seh-rt_v5-rev0.7z到C:\mingw64目录。
(3)解压msys+7za+wget+svn+git+mercurial+cvs-rev13.7z到C:\msys目录。
(4)将HiSVP_PC_V1.2.0.0\tools\nnie\windows\ruyi_env_setup-2.0.41目录拷贝到C:\ruyi_env_setup目录下,该目录将作为最终SVP所需Python3.5+Caffe目录使用。
(5)拷贝libraries_v140_x64_py35_1.1.0.tar.bz2文件到C:\ruyi_env_setup目录下。
(6)在当前目录下建立python35目录,拷贝随文资源中Ruyi Python35 Lib Needed目录下所有压缩包到此目录,并执行C:\ruyi_env_setup\setup_python.bat。
网络训练方式的选择
最终的网络模型移植将在RuyiStudio工具中完成。因此我们应选取Caffe1.0神经网络计算框架或将最终模型文件转化为Caffe1.0的格式。整体的训练和开发流程如下图1-2所示:
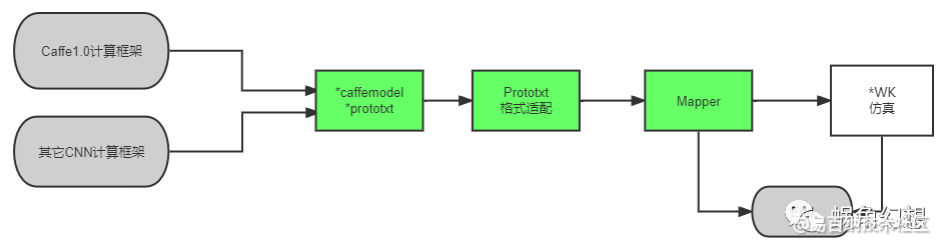
由上图可知,网络训练的重点在于如何得到网络的Caffe模型(*.caffemodel + *.prototxt)。在海思SVP开发SDK中,提供了可用于学习的YOLOv1~YOLOv3预训练模型的caffemodel文件和prototxt文件,它是从YOLO的Darknet版本生成的网络模型转化而来得到的。由此不难想到几种网络训练方式(叙述以YOLO为例):
- 使用Darknet或其它框架(如Pytorch或Keras)训练网络,最后使用如Darknet2Caffe等工具对模型进行转化;
- 查找已有的可训练版本的Caffe实现,适配编译得到的Caffe进行训练得到最终的模型;
- 基于Caffe源码中的examples,编写YOLOv3的训练描述文件,适配编译得到的Caffe进行训练得到最终的模型。
- Python的版本(Python2.7 v.s. Python3.5)、CUDA版本和操作系统(Windows v.s. Linux)多种多样,故上述训练方式有众多的可组合路径。由于网络最终需要转换为Caffe模型,因此无论采用上述哪种方式,均需Caffe环境并为其添加Upsample,Focus等必要的算子。
二、例程YOLOv3NNIE前向计算过程
本节以SVP-NNIE例程中对YOLOv3的处理过程为例,简要记录整个处理流程及其中关键之处,并为后面使用NNIE加速网络预测打好基础。由于文档的形式并不适合解读源码,因此这里仅叙述一些程序理解上的关键之处。你在阅读源码的时候应该至少关注以下问题:
- 使用NNIE加速神经网络模型的处理流程是怎样的?
- 待检测图像是如何输入到网络模型中的?
- 从NNIE中输出的预测结果数据的内存分布图是怎样的,与Pytorch框架下的网络输出结果是否一致?
- 从网络输出到最终结果需要做怎样的NMS处理?
- 示例程序的运行速度如何、主要性能瓶颈在哪里,以及实时性优化可以从哪些方面入手?
例程中对YOLOv3网络模型的初始化操作
阅读NNIE例程的时候,需要明白一些重要概念:
- 网络分层
网络分段的描述可参见《HiSVP API参考05版(2019-06-25)》P29。YOLOv3网络属于端到端的One-Stage网络模型,且在例程中由应用程序处理网络的最终输出,因此仅有一个网络分段。一个网络分段中可以包含众多的网络层。
三、Blob(源Blob、输出Blob)和YOLOv3的输出关系
YOLOv3模型具有一个输入层和3个输出层(YOLO层),因此具有一个源blob和3个输出blobs。Blob是Caffe框架中的基本类,用于网络层之间的数据传递。因此获取网络段的输出blob即为获取网络的最终输出数据。
和大部分程序一样,在平台上运行网络模型同样遵循“初始化-使用-去初始化”的流程,在例程中,初始化完成的工作主要有:
- 复制网络模型到MMZ内存并加载;
- 为NNIE硬件计算申请所需内存,该片内存分为三个部分:
- 模型计算所需要的辅助内存(u32TmpBufSize),具体大小由加载模型时得到的模型描述结构体提供;
- 网络模型中各分段任务缓冲区(u32TotalTaskBufSize),具体大小通过调用 HI_MPI_SVP_NNIE_GetTskBufSize API获得;
- 在各网络段之间传输的源Blob和输出Blob所占空间(astBlobSize),如原始图像和网络段输出等。
- 为软件计算初始化必要的参数,并为用于处理网络输出数据的辅助空间申请所需内存。辅助空间存放从网络段输出Blobs得到的原始数据,这些数据经过后级计算、排序和NMS等操作,得到最终的输出结果(s32DstRoi、st32DstScore、u32ClassRoiNum)。辅助空间由两部分组成:
- 用于存放从网络输出Blob获取的和计算过程中的临时数据的空间(u32TmpBufTotalSize),具体大小在例程库中通过 SAMPLE_SVP_NNIE_Yolov3_GetResultTmpBuf 函数计算。该部分空间又由三部分组成:
- 用于完整获取各输出Blob的内存空间,空间大小为各网络段输出Blob的最大值;
- 用于存储所有原始输出Blobs(即网络的3个YOLO层)的所有网格(即13×13、26×26、52×52)的所有输出目标(对应3个锚框)的信息(即4bbox+1objectness+80classes)的内存空间;
- 其它临时变量(例程中为快排操作所需的SAMPLE_SVP_NNIE_STACK_S类型的结构体空间)。
- 用于存放最终过滤后的目标结果的空间(u32DstRoiSize+u32DstScoreSize+u32ClassRoiNumSize)。
图像的输入
在程序初始化网络模型的硬件参数时,将申请的源blob内存空间地址记录在了 s_stYolov3NnieParam.astSegData[0].astSrc[0] 中,因此按照网络训练时的输入图像格式将待检测图像拷贝到源blob地址空间即可完成图像输入,而后需刷新MMZ缓存以同步数据。
NNIE输出数据的内存分布图
由于例程中使用的YOLOv3网络模型是从原作者Darknet网络预训练权重直接转化而来,因此网络输出数据格式也遵循了原网络输出。所不同的是:海思NNIE为了更好地进行加速,对每行数据进行了对齐操作(参见《HiSVP API参考05版(2019-06-25)》P30)。因此获取网络输出时需要略过这些用于对齐的无效字节。
和输入一样,申请的输出blob内存空间地址记录在了astSegData[0].astDst[0:2]中,对应着YOLOv3网络的3个YOLO层。以13×13的YOLO网络层举例,其输出张量(13 × 13 × [ 3 × ( 4 + 1 + 80 ) ] 13×13×[3×(4+1+80)]13×13×[3×(4+1+80)])在内存中的存储布局如下图1-3所示:
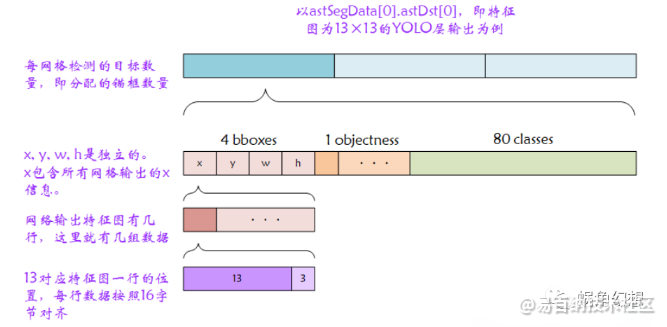
图 1-3 SVP-NNIE-YOLOv3网络输出内存分布图-1
将数据按照特征图每行排列可以更直观地看到输出内存空间的全貌,如下图1-4所示:
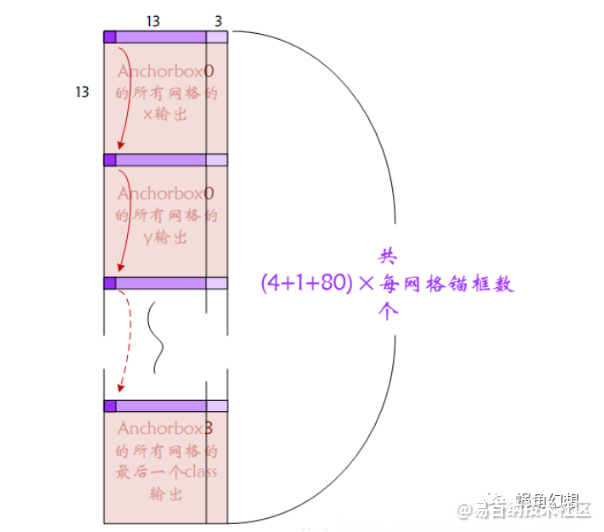
图 1-4 SVP-NNIE-YOLOv3网络输出内存分布图-2
网络的NMS处理
知道了输出数据在内存中的存储格式,那么例程又是如何对数据进行处理的呢?
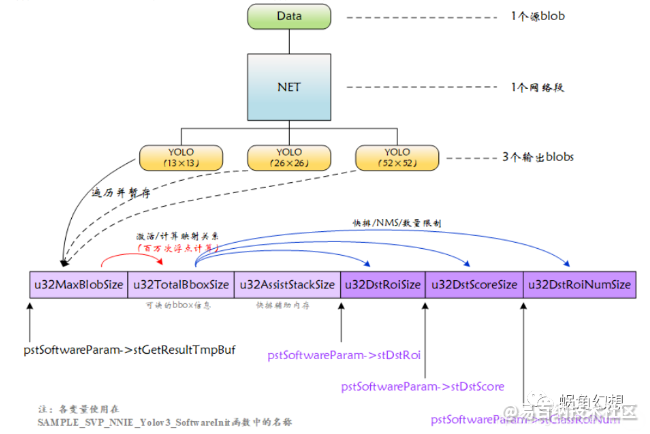
图 1-5 SVP-NNIE-YOLOv3网络后级处理
如上图所示,处理函数遍历了3个YOLO网络层输出,每一次遍历将blob暂存在 pstSoftwareParam->stGetResultTmpBuf (在处理函数 SVP_NNIE_Yolov3_GetResult 中为 pf32Permute 指针)指向的空间内,而后对该blob数据进行Sigmoid计算和映射关系计算,得到每个网格针对每个锚框预测的bbox信息。遍历结束后,对这些bbox进行快排和NMS等操作即得到最终的输出结果。
通过阅读转换函数可知,存储在 pf32Permute 指向的空间中的数据组织形式为:
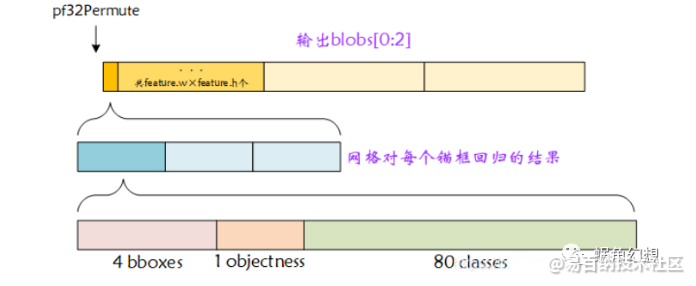
图 1-6 SVP-NNIE-YOLOv3网络结果转换blob临时空间内存分布图
性能分析和优化思路
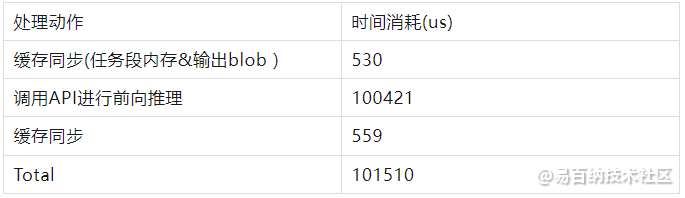
在Hi3516DV300平台上执行YOLOv3实例程序是主要部分耗时如下:
前向计算过程
结果获取和处理过程
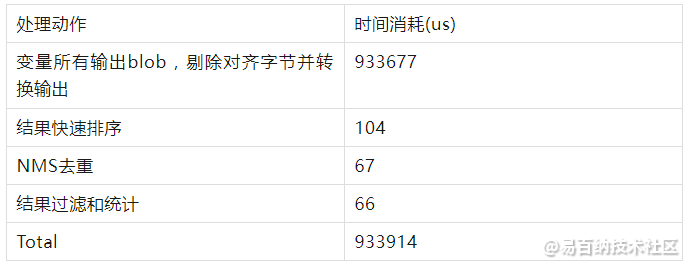
例程使用的测试图像包含的目标较少,因此快排和NMS没有明显耗时,但从上述结果来看,网络的前项推理和后续对各输出blob的遍历的确花费了大量的时间。阅读代码可知,例程中遍历了所有网格(13×13、26×26、52×52)的所有预测(3个),并对坐标、置信度和类概率执行了Sigmoid计算,对宽高做了exp计算。仅浮点计算次数就以百万计,这其中不乏大量的空预测和无效预测,不加区分地处理每个输出严重浪费了处理器性能。
对于例程中采用的结果处理方法,有以下几种改进策略:
- 先进行过滤处理,再对有效预测结果做激活和映射等浮点运算每个网格会为每个尺度的anchorbox预测结果输出80个分类的类概率,而最终处理又仅会选取其中得分最大的作为最终结果类别,因此可先进行数值比较再对单一分类的结果做浮点计算。
- 重新训练网络,减少网络预测的分类数减少网络分类数也就减少了网络的输出张量,进而在加快前向计算的同时降低了后级处理的开销。
- 网络前向计算速度则快很多,但100ms+的耗时依然没有达到实时性要求,好在对于目标任务,我们并不需要像YOLOv3这样“完美”的网络,因此在网络深度和输出上有不少可裁剪甚至重新设计的空间。例如考虑到监控摄像头所处角度较高,因此拍摄到的目标较小,甚至不会占满半个屏幕,因此可以裁剪特征图较小的输出层;视频监控不需要严格定位目标的边界,而更倾向于对目标的检测和类别的识别,因此可以减少骨干网络后用于特征合并和坐标预测的网络层;另外,诸如“使用深度可分离卷积替换常规卷积核”和“对网络进行剪枝”等方法可能会对减小网络模型体积、提升网络预测速度有帮助。
- 事实上,YOLO系列发展至今,从工程应用出发,基于YOLOv3改进已经没有太大的必要性了,在该系列后面的文章中,我们将看到一个更快、更轻、更好的YOLOv5模型,它将比YOLOv3更适合实时性的工程应用。
附录(在caffe上添加网络层)
添加网络层的一般步骤简述为:
- 实现网络层的C++代码、头文件和CUDA代码,将头文件放在 /include/caffe/layers 目录下,将源文件放在 /src/caffe/layers 目录下;
- 修改Caffe原型文件 src/caffe/proto/caffe.proto ,在 message LayerParameter 结构中增加新网络层定义,并分配不同于现有的标号;
message LayerParameter{
# 早先的定义
...
optional NewLayerParameter newlayer_param = 1111; # 分配号不可重复,一般按顺序分配,此处仅为示例
}3.接上一步,在文件中(如最末尾处)为新网络层添加message LayerParameter描述,以告知网络层所需的参数;
message UpsampleParameter{
optional 变量类型 变量名 = 变量值 [default = 默认值];
...
}4.在VS工程中增加对新网络层的编译,或重新生成VS工程;
5.重新编译Caffe
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2444次2024-01-13 18:14:30
-
浏览量:2714次2024-06-06 09:47:33
-
浏览量:6458次2024-05-22 15:23:49
-
浏览量:5187次2024-01-22 17:46:51
-
浏览量:6431次2024-02-05 10:41:25
-
浏览量:2849次2024-01-08 16:49:01
-
浏览量:5528次2020-09-30 18:01:11
-
浏览量:1724次2024-02-05 17:05:51
-
浏览量:9644次2022-06-01 10:01:04
-
浏览量:6482次2023-03-20 13:32:44
-
浏览量:2755次2024-01-22 17:02:06
-
浏览量:3859次2023-07-12 15:22:31
-
浏览量:4019次2023-06-28 15:57:28
-
浏览量:5084次2022-10-13 17:29:06
-
浏览量:2971次2023-06-12 14:34:37
-
浏览量:3071次2023-06-12 14:18:20
-
浏览量:3921次2022-10-14 10:34:46
-
浏览量:16575次2020-12-18 17:44:33
-
浏览量:3055次2023-11-06 11:04:59






-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
圈圈

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
