

海思AI芯片HI3516DV300上SSD代码的移植和优化

前一段时间一直在做海思AI芯片 HI3516DV300上SSD代码的优化工作,这里总结一下优化的一些心得体会。之所以要对海思AI芯片 HI3516DV300上SSD代码做优化,是因为SSD有一部分是运行在CPU上,而HI3516DV300上的CPU性能比较差,网络只要稍微复杂一点,CPU部分运行就会很慢。下表给出了一些模型在芯片上运行的时间,可以看到CPU部分运行的时间占据了大部分。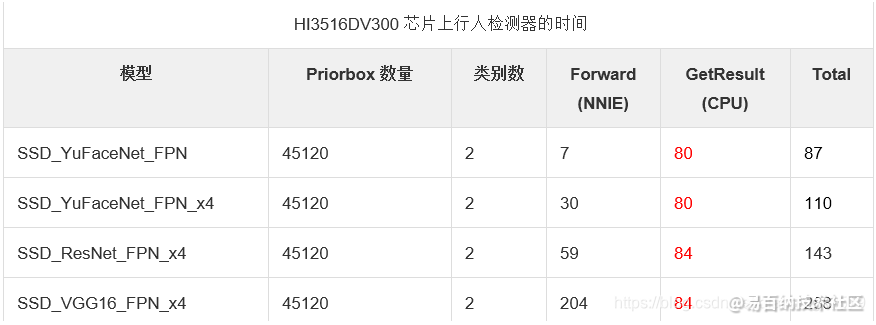
注意:
这里的Forward对应SAMPLE_SVP_NNIE_Forward()函数,这个函数基本上是运行在NNIE上的,GetResult对应SAMPLE_SVP_NNIE_Ssd_GetResult函数,这个函数是运行在CPU上的,后面直接使用GetResult表示这个函数
DetectionOutForward的优化
首先分析性能瓶颈。通过对GetResult函数分析发现主要耗时在两个函数中:SVP_NNIE_Ssd_SoftmaxForward和SVP_NNIE_Ssd_DetectionOutForward,后面直接使用SoftmaxForward和DetectionOutForward表示。

进一步对DetectionOutForward函数进行分析,其中DetectionOutForward主要包含了两个步骤,这两个部分分别对应了两个for循环:
- decode box: 将网络输出的预测值转换为实际的坐标值,这一部分记为Loop1
- NMS: 对每一类目标的前topk个置信度最高的bbox做NMS,这一部分记为Loop2
发现主要耗时在Loop1中

Loop1对应了如下代码:
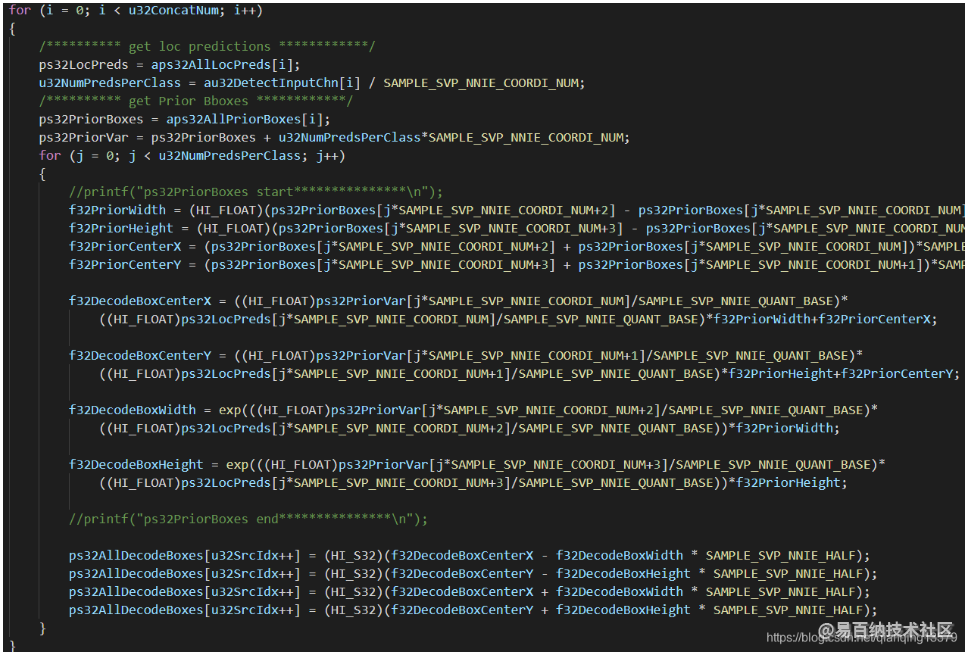
分析Loop1代码,Loop1主要功能是对所有anchor的预测值进行解码转换为anchor在图像中实际的坐标值。
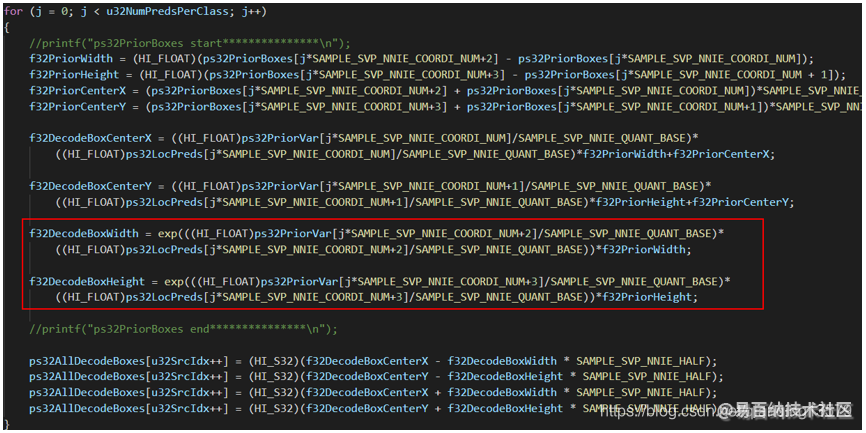
对每一个anchor都需要调用两次exp()函数(上图中红框标出的部分),这个函数是一个非常耗时的函数,45120个anchor一共调用90240次exp(),通过测试发现90240次exp()调用需要耗时21ms,如果能够减少exp()的调用次数,将会大大减少时间。
由于实际做NMS的时候,我们只对前topk个置信度最高的bbox做NMS,也就是说只会用到前topk个bbox的真实坐标值,其他bbox的坐标值用不到,所以我们只需要计算出前topk个bbox的真实坐标值就可以了,这里topK设置为400,也就是说只需要执行800次exp操作就可以,而800次exp操作只需要0.2ms,可以大大减少时间。
但是最后做NMS的时候,使用的是图1中蓝框中的4个变量,而如果要计算出真实坐标值,就必须要知道网络输出的预测值和priorbox的坐标,也就是如果要计算出前topk个bbox的真实坐标值,就必须要知道每个bbox对应的8个变量,图1中红框和绿框中的8个值。
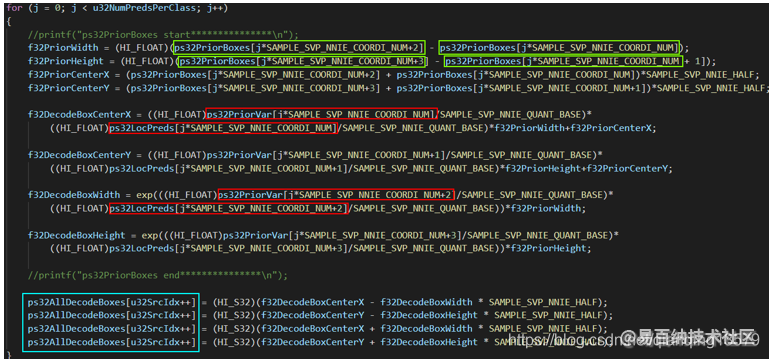
8个值:
ps32PriorBoxes[jSAMPLE_SVP_NNIE_COORDI_NUM]
ps32PriorBoxes[jSAMPLE_SVP_NNIE_COORDI_NUM+1]
ps32PriorBoxes[jSAMPLE_SVP_NNIE_COORDI_NUM+2]
ps32PriorBoxes[jSAMPLE_SVP_NNIE_COORDI_NUM+3]
ps32LocPreds[jSAMPLE_SVP_NNIE_COORDI_NUM]
ps32LocPreds[jSAMPLE_SVP_NNIE_COORDI_NUM+1]
ps32LocPreds[jSAMPLE_SVP_NNIE_COORDI_NUM+2]
ps32LocPreds[jSAMPLE_SVP_NNIE_COORDI_NUM+3]
下面的问题就是如何将每个bbox对应的这8个变量编码到4个变量中,通过对每个bbox对应的8个变量分析发现:
- 由于网络输入大小是512,也就是图像中的坐标在[0,512]之间,也就是ps32PriorBoxes的值也在[0,512]之间,也就表示ps32PriorBoxes的值可以通过3位数来表示
- ps32LocPreds的值有正有负,而且值的范围可以使用5位数表示
基于上面的发现,设计了以下编码方式:
ps32LocPreds 10000+ps32PriorBoxes 10+flag
其中flag为标记位,当ps32LocPreds值为负数时,flag为0,当ps32LocPreds值为正数时,flag为1,而且编码之后的值全部转换为正数,便于解码。
这个编码的含义就是:最后一位是标记位,倒数第2到第4位是priorbox的值,剩下的位数是位置预测值,示例:
-3852,125→38521250
5017,96→50170961
-13590,145→135901450
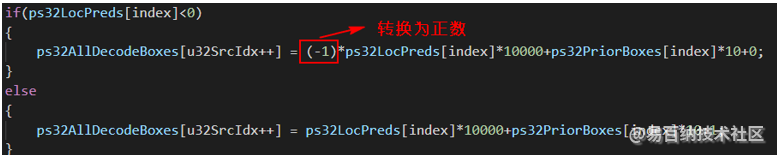
最后,在NMS的时候,进行解码就可以计算出真实坐标值了,比如对每个bbox编码之后的4个值的第一个值进行解码:
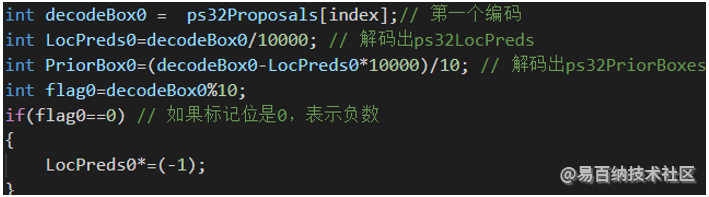
这样就可以得到需要的8个值,最后根据这8个值就可以计算出该bbox的真实坐标值了

使用优化后的代码进行速度测试

行人检测器Loop1经过优化后从原来的34ms提高到了7ms,速度得到了明显提高,由于Loop2增加了解码的时间,所以Loop2会略微变慢,但是总体时间还是大大降低了。优化之后对精度是完全没有影响的。
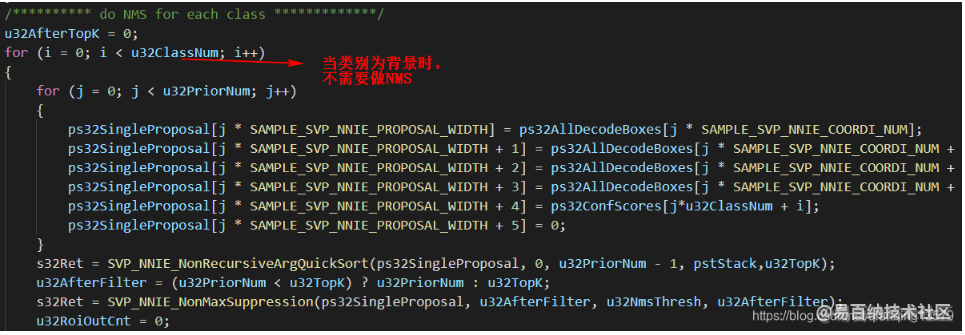
修改后的代码:
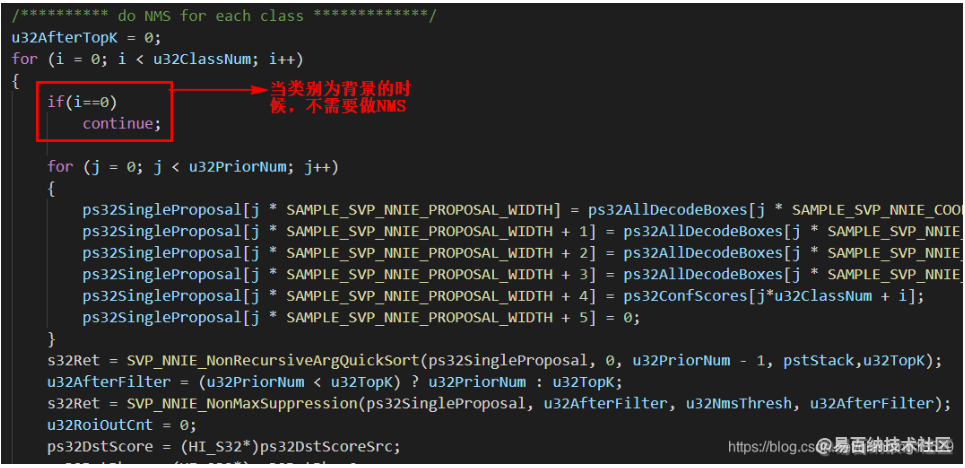
优化后的时间:

我们可以看到优化后Loop2的时间大大降低,在CPU上运行的时间基本上降低为原来的一半了。
Softmax的优化
上面分析了GetResult函数主要耗时在两个函数中:SoftmaxForward和DetectionOutForward。上面对DetectionOutForward进行了优化,那么SoftmaxForward是否可以优化呢?
分析了SoftmaxForward函数,发现计算所有anchor的置信度的时候,45120个anchor也需要调用90240次exp(),需要耗时21ms。
我们知道softmax概率的计算公式如下:
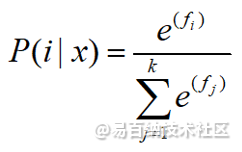
在对softmax进行优化的时候,我做了一个实验,直接使用fi表示softmax置信度,然后在多个模型中做了测试:
数据集A:
数据集B: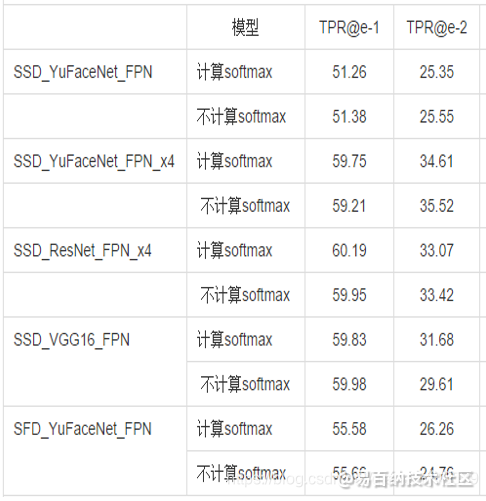
我发现一个很奇怪的现象:直接使用fi代替softmax概率,大部分模型精度基本上没有损失。同时也观察了一系列模型的结果,发现softmax概率大的目标往往fi值也大。 目前还不知道具体原因。有知道其中原因的朋友欢迎留言讨论。
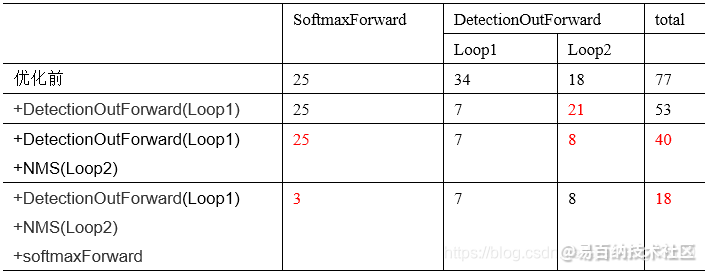
由于去掉了softmax的计算,所以时间会大大减少,上表中可以看到去掉了softmax计算后,从原来的77ms直接降低到了18ms,速度提高了4倍多。但是由于目前对这种现象的原因还不明确,所以暂时是没有使用的。
结束语
通过本次优化,深刻体会到了算法性能的重要性,PC上很快的一个操作,在其他平台很可能就是性能的瓶颈。同时也体会到了深入理解算法的重要性以及将速度做到极 致的那种成就感。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2716次2024-06-06 09:47:33
-
浏览量:2853次2024-01-08 16:49:01
-
浏览量:2756次2024-01-22 17:02:06
-
浏览量:2451次2024-01-13 18:14:30
-
浏览量:5529次2020-09-30 18:01:11
-
浏览量:6488次2023-03-20 13:32:44
-
浏览量:5090次2022-10-13 17:29:06
-
浏览量:3863次2023-07-12 15:22:31
-
浏览量:2978次2023-06-12 14:34:37
-
浏览量:9647次2022-06-01 10:01:04
-
浏览量:3931次2022-10-14 10:34:46
-
浏览量:2396次2023-06-20 16:09:54
-
浏览量:6525次2023-10-13 17:55:36
-
浏览量:4021次2023-06-28 15:57:28
-
浏览量:6401次2020-11-02 17:07:53
-
浏览量:3080次2023-06-12 14:18:20
-
浏览量:3061次2023-11-06 11:04:59
-
浏览量:16585次2020-12-18 17:44:33
-
浏览量:8582次2020-09-17 16:12:59




-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
郭金**

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
