

技术专栏
一步步实现人脸识别<1>

这篇(以及这个系列文章)都整理自恩培老师的课程.
首先, 人脸识别算是跟OCR一样的一个普遍的话题, 解决思路也有点类似, 首先, 找到画面中的人脸的区域.
第一步, 找到一个数据集, 这个数据集是爬虫从上网爬到的公众人物的图片, 用人名作为目录组织好了, 相当于做好了标签.
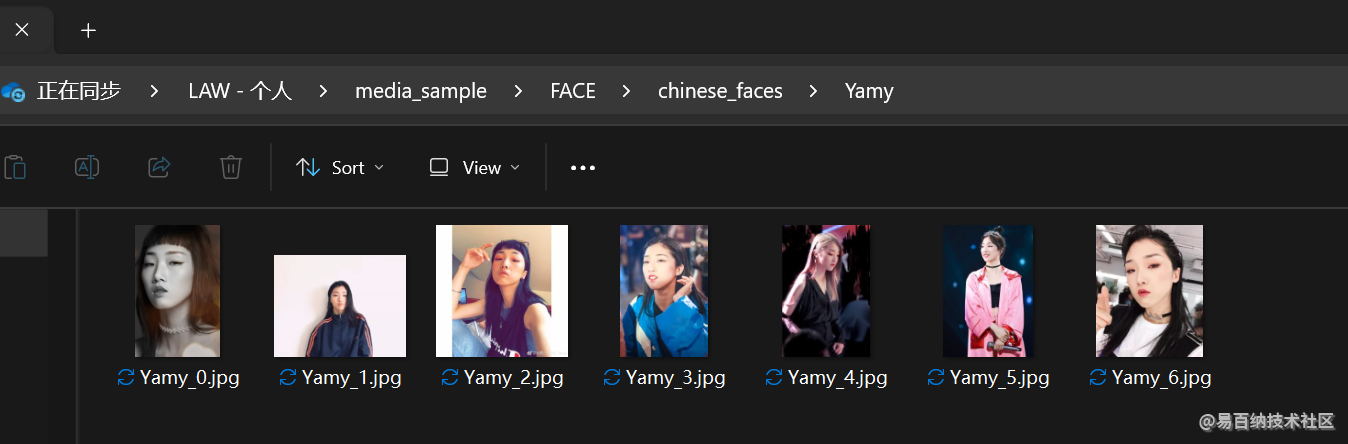
当然这个目录名可能是中文的.
然后使用opencv的dnn的模型res10_300x300_ssd_iter_140000, 对所有的图片做一个处理, 取出图片中,包含人脸的部分:
# 实例化dnn模型
face_detector = cv2.dnn.readNetFromCaffe('./weights/deploy.prototxt.txt','./weights/res10_300x300_ssd_iter_140000.caffemodel')
定义一个裁剪图片的函数:
def getCropedFace(img_file, conf_thresh=0.5 ):
"""
将图片进行人脸裁剪
@param:
img_file: str 文件名
conf_thresh: float 置信度预支
w_thresh,h_thresh: 人脸长度宽度阈值,小于它则丢弃
@return
croped_face: numpy img 裁剪后的人脸,如果没有符合条件的,则返回None
"""
# 读取图片
# img = cv2.imread(img_file)
# 解决中文路径问题
img=cv2.imdecode(np.fromfile(img_file,dtype=np.uint8),-1)
if img is None:
return None
# 画面原来高度和宽度
img_height,img_width = img.shape[:2]
# 缩放图片
img_resize = cv2.resize(img,(300,300))
# 图像转为blob
img_blob = cv2.dnn.blobFromImage(img_resize,1.0,(300,300),(104.0, 177.0, 123.0))
# 输入
face_detector.setInput(img_blob)
# 推理
detections = face_detector.forward()
# 查看检测人脸数量
num_of_detections = detections.shape[2]
# 遍历人脸
for index in range(num_of_detections):
# 置信度
detection_confidence = detections[0,0,index,2]
# 挑选置信度,找到一个人返回
if detection_confidence > conf_thresh:
# 位置
locations = detections[0,0,index,3:7] * np.array([img_width,img_height,img_width,img_height])
# 矩形坐标
l,t,r,b = locations.astype('int')
# 长度宽度判断
w = r - l
h = b - t
# print(w,h)
croped_face = img[t:b,l:r]
return croped_face
# 都不满足
return None
然后把数据集中的所有图片, 挨个的进行裁剪
import glob,tqdm,os
# 获取人名列表
person_list = glob.glob('C:\\Users\\zunly\\OneDrive\\media_sample\\chinese_faces\\*')
# 遍历人名
for person in tqdm.tqdm( person_list ,desc='处理中...'):
# 获取人名(这里需要根据自己系统来改一下,Windows用\\,Unix系系统用/))
person_class = person.split('\\')[-1]
# 创建需要保存的目录
save_dir = 'C:\\Users\\zunly\\OneDrive\\media_sample\\chinese_faces\\chinese_faces_cleaned\\' + person_class
if not os.path.exists(save_dir):
os.makedirs(save_dir)
# 获取该人名下的所有图片
file_name = person+'\\*.jpg'
img_list = glob.glob(file_name)
# 遍历图片
for img_file in img_list:
# 处理图片
croped_face = getCropedFace(img_file)
if croped_face is not None:
# 获取文件名(这里需要根据自己系统来改一下,Windows用\\,Unix系系统用/))
file_name = img_file.split('\\')[-1]
save_file_name = save_dir+'\\'+file_name
# 保存,同样要解决中文路径
# cv2.imwrite(save_file_name,croped_face)
cv2.imencode('.jpg', croped_face)[1].tofile(save_file_name)
最终得到一个文件夹中的数据, 都是已经裁剪好的人脸, 并同样在人名的目录下:
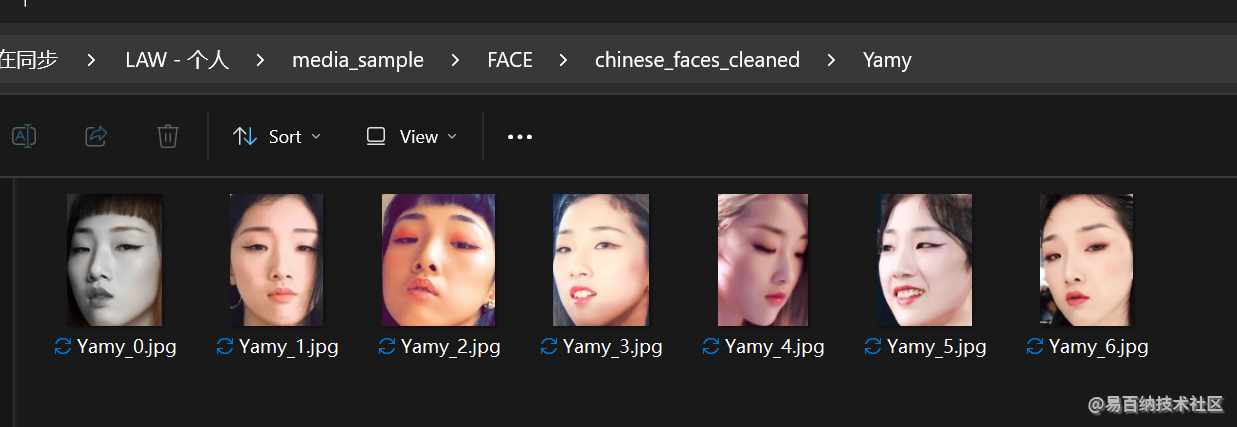
可以看到, 人脸的部分都被裁剪出来, 成了一个新的文件, 放在这个标签所在的目录.
声明:本文内容由易百纳平台入驻作者撰写,文章观点仅代表作者本人,不代表易百纳立场。如有内容侵权或者其他问题,请联系本站进行删除。
红包
4
1
评论
打赏
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
评论
0个
手气红包
 暂无数据
暂无数据相关专栏
-
浏览量:1469次2023-11-13 12:34:02
-
浏览量:1205次2023-07-26 09:40:01
-
浏览量:2000次2024-01-24 16:33:36
-
浏览量:2106次2024-02-04 10:08:58
-
浏览量:1312次2023-08-30 18:29:45
-
浏览量:1066次2023-08-18 08:57:27
-
浏览量:2315次2023-03-09 15:39:13
-
浏览量:2970次2018-04-21 14:25:30
-
浏览量:3134次2019-06-28 10:35:50
-
浏览量:2756次2024-01-22 17:02:06
-
浏览量:2671次2019-10-26 10:21:25
-
浏览量:2081次2023-03-09 09:38:33
-
浏览量:2254次2024-03-14 17:53:46
-
浏览量:1710次2024-03-05 16:31:54
-
浏览量:6579次2021-07-28 14:21:28
-
2021-06-22 16:27:28
-
浏览量:2533次2022-12-16 09:12:30
-
浏览量:3624次2019-05-31 09:43:21
-
浏览量:3572次2024-02-26 14:47:49






置顶时间设置
结束时间
删除原因
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
打赏作者

Marc
您的支持将鼓励我继续创作!
打赏金额:
¥1
¥5
¥10
¥50
¥100
支付方式:
 微信支付
微信支付
举报反馈
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
发布时间设置
发布时间:
请选择发布时间设置
是否关联周任务-专栏模块
审核失败
失败原因
请选择失败原因
备注
请输入备注



关注公众号
联系我们
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
回顶部
