

你用什么方法调试深度神经网络?这里有四种简单的方式哦
当你花了几个星期构建一个数据集、编码一个神经网络并训练好了模型,然后发现结果并不理想,接下来你会怎么做?
深度学习通常被视为一个黑盒子,我并不反对这种观点——但是你能讲清楚学到的上万参数的意义吗?
但是黑盒子的观点为机器学习从业者指出了一个明显的问题:你如何调试模型?
在这篇文章中,我将会介绍一些我们在 Cardiogram 中调试 DeepHeart 时用到的技术,DeepHeart 是使用来自 Apple Watch、 Garmin、和 WearOS 的数据预测疾病的深度神经网络。
在 Cardiogram 中,我们认为构建 DNN 并不是炼金术,而是工程学。
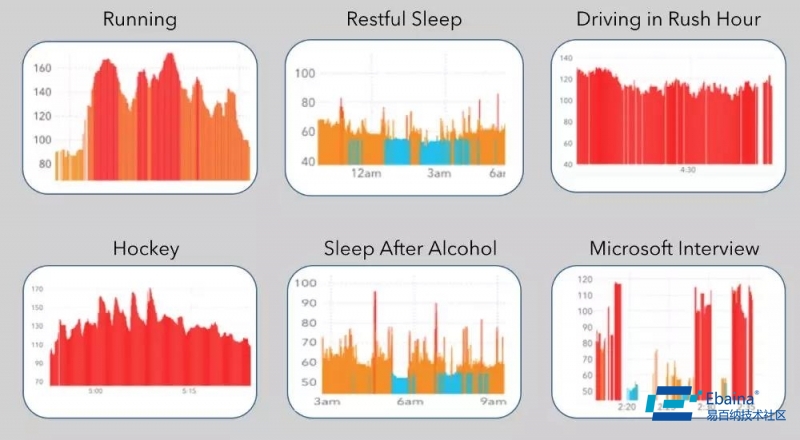
你的心脏暴露了很多你的信息。DeepHeart 使用来自 Apple Watch、 Garmin、和 WearOS 的心率数据来预测你患糖尿病、高血压以及睡眠窒息症(sleep apnea)的风险。
一、预测合成输出
通过预测根据输入数据构建的合成输出任务来测试模型能力。
我们在构建检测睡眠窒息症的模型时使用了这个技术。现有关于睡眠窒息症筛查的文献使用日间和夜间心率标准差的差异作为筛查机制。因此我们为每周的输入数据创建了合成输出任务:
标准差 (日间心率)—标准差 (夜间心率)
为了学习这个函数,模型要能够:
1、 区分白天和黑夜
2、 记住过去几天的数据
这两个都是预测睡眠窒息症的先决条件,所以我们使用新架构进行实验的第一步就是检查它是否能学习这个合成任务。
你也可以通过在合成任务上预训练网络,以半监督的形式来使用类似这样的合成任务。当标记数据很稀缺,而你手头有大量未标记数据时,这种方法很有用。
二、可视化激活值
理解一个训练好的模型的内部机制是很难的。你如何理解成千上万的矩阵乘法呢?
在这篇优秀的 Distill 文章《Four Experiments in Handwriting with a Neural Network》中,作者通过在热图中绘制单元激活值,分析了手写模型。我们发现这是一个「打开 DNN 引擎盖」的好方法。
我们检查了网络中几个层的激活值,希望能够发现一些语义属性,例如,当用户在睡觉、工作或者焦虑时,激活的单元是怎样的?
用 Keras 写的从模型中提取激活值的代码很简单。下面的代码片段创建了一个 Keras 函数 last_output_fn,该函数在给定一些输入数据的情况下,能够获得一层的输出(即它的激活值)。

我们可视化了网络好几层的激活值。在检查第二个卷积层(一个宽为 128 的时间卷积层)的激活值时,我们注意到了一些奇怪的事:
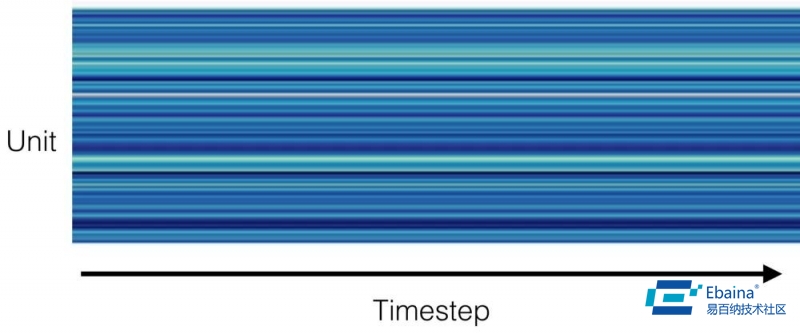
卷积层的每个单元在每个时间步长上的激活值。蓝色的阴影代表的是激活值。
激活值竟然不是随着时间变化的!它们不受输入值影响,被称为「死神经元」。
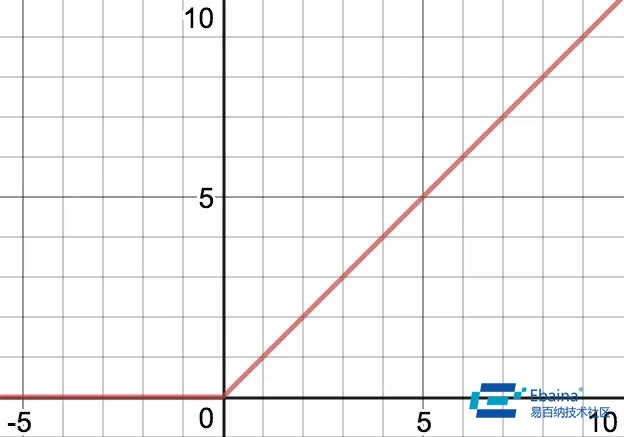
ReLU 激活函数,f(x) = max(0, x)
这个架构使用了 ReLU 激活函数,当输入是负数的时候它输出的是 0。尽管它是这个神经网络中比较浅的层,但是这确实是实际发生的事情。
在训练的某些时候,较大的梯度会把某一层的所有偏置项都变成负数,使得 ReLU 函数的输入是很小的负数。因此这层的输出就会全部为 0,因为对小于 0 的输入来说,ReLU 的梯度为零,这个问题无法通过梯度下降来解决。
当一个卷积层的输出全部为零时,后续层的单元就会输出其偏置项的值。这就是这个层每个单元输出一个不同值的原因——因为它们的偏置项不同。
我们通过用 Leaky ReLU 替换 ReLU 解决了这个问题,前者允许梯度传播,即使输入为负时。
我们没想到会在此次分析中发现「死神经元」,但最难找到的错误是你没打算找的。
三、梯度分析
梯度的作用当然不止是优化损失函数。在梯度下降中,我们计算与Δparameter 对应的Δloss。尽管通常意义上梯度计算的是改变一个变量对另一个变量的影响。由于梯度计算在梯度下降方法中是必需的,所以像 TensorFlow 这样的框架都提供了计算梯度的函数。
我们使用梯度分析来确定我们的深度神经网络能否捕捉数据中的长期依赖。DNN 的输入数据特别长:4096 个时间步长的心率或者计步数据。我们的模型架构能否捕捉数据中的长期依赖非常重要。例如,心率的恢复时间可以预测糖尿病。这就是锻炼后恢复至休息时的心率所耗的时间。为了计算它,深度神经网络必须能够计算出你休息时的心率,并记住你结束锻炼的时间。
衡量模型能否追踪长期依赖的一种简单方法是去检查输入数据的每个时间步长对输出预测的影响。如果后面的时间步长具有特别大的影响,则说明模型没有有效地利用早期数据。
对于所有时间步长 t,我们想要计算的梯度是与Δinput_t 对应的Δoutput。下面是用 Keras 和 TensorFlow 计算这个梯度的代码示例:
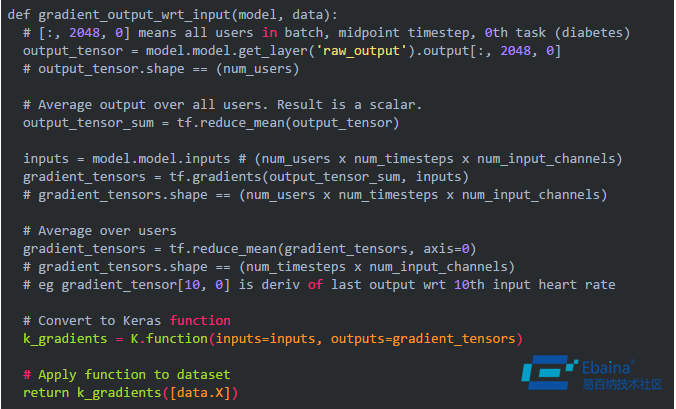
在上面的代码中,我们在平均池化之前,在中点时间步长 2048 处计算了输出。我们之所以使用中点而不是最后的时间步长的原因是,我们的 LSTM 单元是双向的,这意味着对一半的单元来说,4095 实际上是第一个时间步长。我们将得到的梯度进行了可视化:

Δoutput_2048 / Δinput_t
请注意我们的 y 轴是 log 尺度的。在时间步长 2048 处,与输入对应的输出梯度是 0.001。但是在时间步长 2500 处,对应的梯度小了一百万倍!通过梯度分析,我们发现这个架构无法捕捉长期依赖。
四、分析模型预测
你可能已经通过观察像 AUROC 和平均绝对误差这样的指标分析了模型预测。你还可以用更多的分析来理解模型的行为。
例如,我们好奇 DNN 是否真的用心率输入来生成预测,或者说它的学习是不是严重依赖于所提供的元数据——我们用性别、年龄这样的用户元数据来初始化 LSTM 的状态。为了理解这个,我们将模型与在元数据上训练的 logistic 回归模型做了对比。
DNN 模型接收了一周的用户数据,所以在下面的散点图中,每个点代表的是一个用户周。
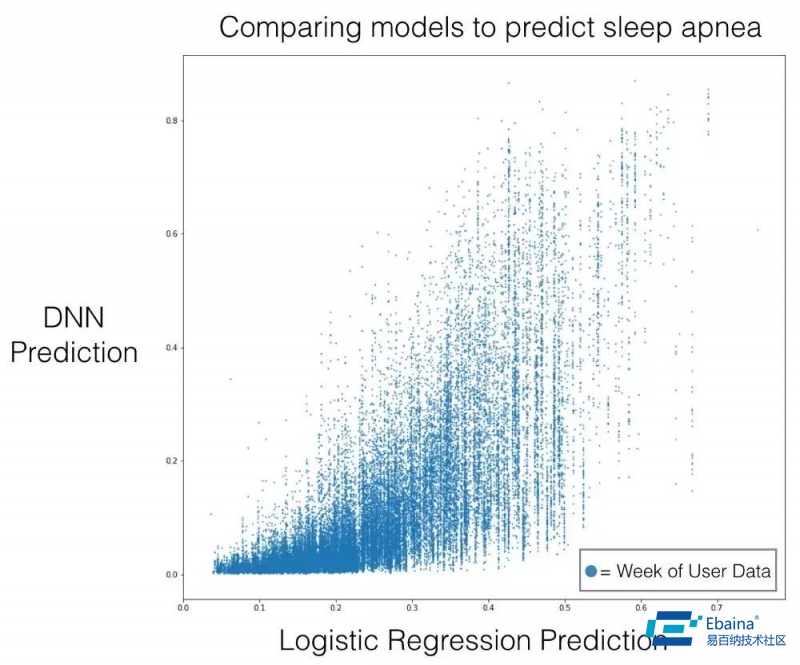
这幅图验证了我们的猜想,因为预测结果并不是高度相关的。
除了进行汇总分析,查看最好和最坏的样本也是很有启发性的。对一个二分类任务而言,你需要查看最令人震惊的假阳性和假阴性(也就是预测距离标签最远的情况)。尝试鉴别损失模式,然后过滤掉在你的真阳性和真阴性中出现的这种模式。
一旦你对损失模式有了假设,就通过分层分析进行测试。例如,如果最高损失全部来自第一代 Apple Watch,我们可以用第一代 Apple Watch 计算我们的调优集中用户集的准确率指标,并将这些指标与在剩余调优集上计算的指标进行比较。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3005次2020-10-29 17:55:50
-
浏览量:1927次2023-03-07 09:26:18
-
浏览量:1473次2024-02-01 14:20:47
-
浏览量:1183次2023-09-04 11:16:00
-
浏览量:4562次2018-02-14 10:30:11
-
浏览量:1106次2023-09-05 10:02:44
-
浏览量:1047次2023-09-28 11:44:09
-
浏览量:2717次2024-02-06 11:41:16
-
浏览量:5419次2021-04-23 14:09:37
-
浏览量:7282次2021-05-31 17:02:05
-
浏览量:5157次2021-04-20 15:50:27
-
浏览量:6235次2021-05-28 16:59:25
-
浏览量:9310次2021-05-28 16:59:43
-
浏览量:5765次2021-08-13 15:39:02
-
浏览量:1324次2023-12-08 17:29:20
-
浏览量:1100次2023-08-28 09:56:42
-
浏览量:4766次2021-04-19 14:54:23
-
浏览量:18978次2021-06-07 17:47:54
-
浏览量:11093次2021-06-15 10:30:15
dbtkm301
暂无个性签名~
-
1篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
dbtkm301

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
