

从 0 到 1 学习 elasticsearch ,这一篇就够了!(建议收藏)
本文已收录github:https://github.com/BigDataScholar/TheKingOfBigData,里面有我准备的大数据高频考点,Java一线大厂面试题资源,上百本免费电子书籍,作者亲绘大数据生态圈思维导图…持续更新,欢迎star!
前言
之前一直想花点时间写一篇 elasticsearch 的保姆级教程,于是,趁着年假的几天时间加上周末的一些时间,我产出了自认为算是非常详细的,基于目前最新版本的elasticsearch7.11教程。不管是新手上路,还是秋名山老司机,都建议收藏一下,希望看完对您有所帮助!如果可以,记得一键三连!

@[TOC]
ElasticSearch概述
Elaticsearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
据国际权威的数据库产品评测机构 DB Engines 的统计,在2016年1月,ElasticSearch已超过Solr等,成为排名第一的搜索引擎类应用。
为了增加学习的趣味性,我们来聊一聊 elasticsearch 的历史
历史
多年前,一个叫做Shay Banon的刚结婚不久的失业开发者,由于妻子要去伦敦学习厨师,他便跟着也去了。在他找工作的过程中,为了给妻子构建一个食谱的搜索引擎,他开始构建一个早期版本的Lucene。
直接基于Lucene工作会比较困难,所以Shay开始抽象Lucene代码以便Java程序员可以在应用中添加搜索功能。他发布了他的第一个开源项目,叫做“Compass”。
后来Shay找到一份工作,这份工作处在高性能和内存数据网格的分布式环境中,因此高性能的、实时的、分布式的搜索引擎也是理所当然需要的。然后他决定重写Compass库使其成为一个独立的服务叫做Elasticsearch。
第一个公开版本出现在2010年2月,在那之后Elasticsearch已经成为Github上最受欢迎的项目之一,代码贡献者超过300人。一家主营Elasticsearch的公司就此成立,他们一边提供商业支持一边开发新功能,不过 Elasticsearch 将永远开源且对所有人可用。
Shay的妻子依旧等待着她的食谱搜索……
ES 和 solr 的差别
学习 ES,我们免不了需要跟 solr 进行对比学习!下面我们分别来看看,它们之间具体的差别在哪里:
Elasticsearch 简介
Elasticsearch 是一个实时分布式搜索和分析引擎。它让你以前所未有的速度处理大数据成为可能。
它用于全文搜索、结构化搜索、分析以及将这三者混合使用:
维基百科使用Elasticsearch提供全文搜索并高亮关键字,以及输入 实时搜索(search-asyou-type)和 搜索纠错(did-you-mean)等搜索建议功能。
英国卫报使用Elasticsearch结合用户日志和社交网络数据提供给他们的编辑以实时的反馈,以便及时了解公众对新发表的文章的回应。
StackOverflow结合全文搜索与地理位置查询,以及more-like-this功能来找到相关的问题和答案。
Github使用Elasticsearch检索1300亿行的代码。
但是 Elasticsearch 不仅用于大型企业,它还让像DataDog 以及 Klout 这样的创业公司将最初的想法变成可扩展的解决方案。
Elasticsearch可以在你的笔记本上运行,也可以在数以百计的服务器上处理PB级别的数据 。
Elasticsearch 是一个基于 Apache Lucene(TM) 的开源搜索引擎。无论在开源还是专有领域,Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库
但是,Lucene只是一个库。想要使用它,你必须使用Java来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的
Elasticsearch也使用Java开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单
Solr 简介
Solr 是 Apache 下的一个顶级开源项目,采用Java开发,它是基于 Lucene 的全文搜索服务器。Solr提供了比 Lucene 更为丰富的查询语言,同时实现了可配置、可扩展,并对索引、搜索性能进行了优化。
Solr可以独立运行,运行在Jetty、Tomcat 等这些Servlet容器中,Solr 索引的实现方法很简单,用 POST 方法向 Solr 服务器发送一个描述 Field 及其内容的 XML 文档,Solr根据 xml 文档添加、删除、更新索引。Solr 搜索只需要发送 HTTP GET 请求,然后对 Solr 返回Xml、json等格式的查询结果进行解析,组织页面布局。Solr不提供构建UI的功能,Solr提供了一个管理界面,通过管理界面可以查询Solr的配置和运 行情况。
Solr是基于 lucene 开发企业级搜索服务器,实际上就是封装了lucene。
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于Web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的文件,生成索引;也可以通过提出查找请求,并得到返回结果。
Lucene简介
Lucene是apache软件基金会4 jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言)。
Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎。
Lucene是一套用于全文检索和搜寻的开源程式库,由Apache软件基金会支持和提供。Lucene提供了一个简单却强大的应用程式接口,能够做全文索引和搜寻。在Java开发环境里Lucene是一个成熟的免费开源工具。就其本身而言,Lucene是当前以及最近几年最受欢迎的免费Java信息检索程序库。人们经常提到信息检索程序库,虽然与搜索引擎有关,但不应该将信息检索程序库与搜索引擎相混淆。
Lucene是一个全文检索引擎的架构。那什么是全文搜索引擎?
全文搜索引擎是名副其实的搜索引擎,国外具代表性的有Google、Fast/AllTheWeb、AltaVista、Inktomi、Teoma、WiseNut等,国内著名的有百度(Baidu)。它们都是通过从互联网上提取的各个网站的信息(以网页文字为主)而建立的数据库中,检索与用户查询条件匹配的相关记录,然后按一定的排列顺序将结果返回给用户,因此他们是真正的搜索引擎。
从搜索结果来源的角度,全文搜索引擎又可细分为两种,一种是拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,并自建网页数据库,搜索结果直接从自身的数据库中调用,如上面提到的7家引擎;另一种则是租用其他引擎的数据库,并按自定的格式排列搜索结果,如 Lycos 引擎。
Elasticsearch和Solr比较




ElasticSearch vs Solr 总结
1、es基本是开箱即用,非常简单。Solr安装略微复杂一丢丢!
2、Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能。
3、Solr 支持更多格式的数据,比如JSON、XML、CSV,而 Elasticsearch 仅支持json文件格式
4、Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供,例如图形化界面需要kibana友好支撑
5、Solr 查询快,但更新索引时慢(即插入删除慢),用于电商等查询多的应用;
- ES建立索引快(即查询慢),即实时性查询快,用于facebook新浪等搜索。
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用。
6、Solr 比较成熟,有一个更大,更成熟的用户、开发和贡献者社区,而 Elasticsearch 相对开发维护者较少,更新太快,学习使用成本较高。
所以如果我们在做技术选型的时候,具体选择哪一项技术,还需要根据不同的场景来进行结合选择。
哈哈哈,好像跑题了,下面我们就正式进入到 elasticsearch 的学习中!
安装elasticsearch
我们首先来到 es 的官网,根据自己不同的操作系统,点击即可下载最新版本的产品,目前最新版本是Elasticsearch 7.11
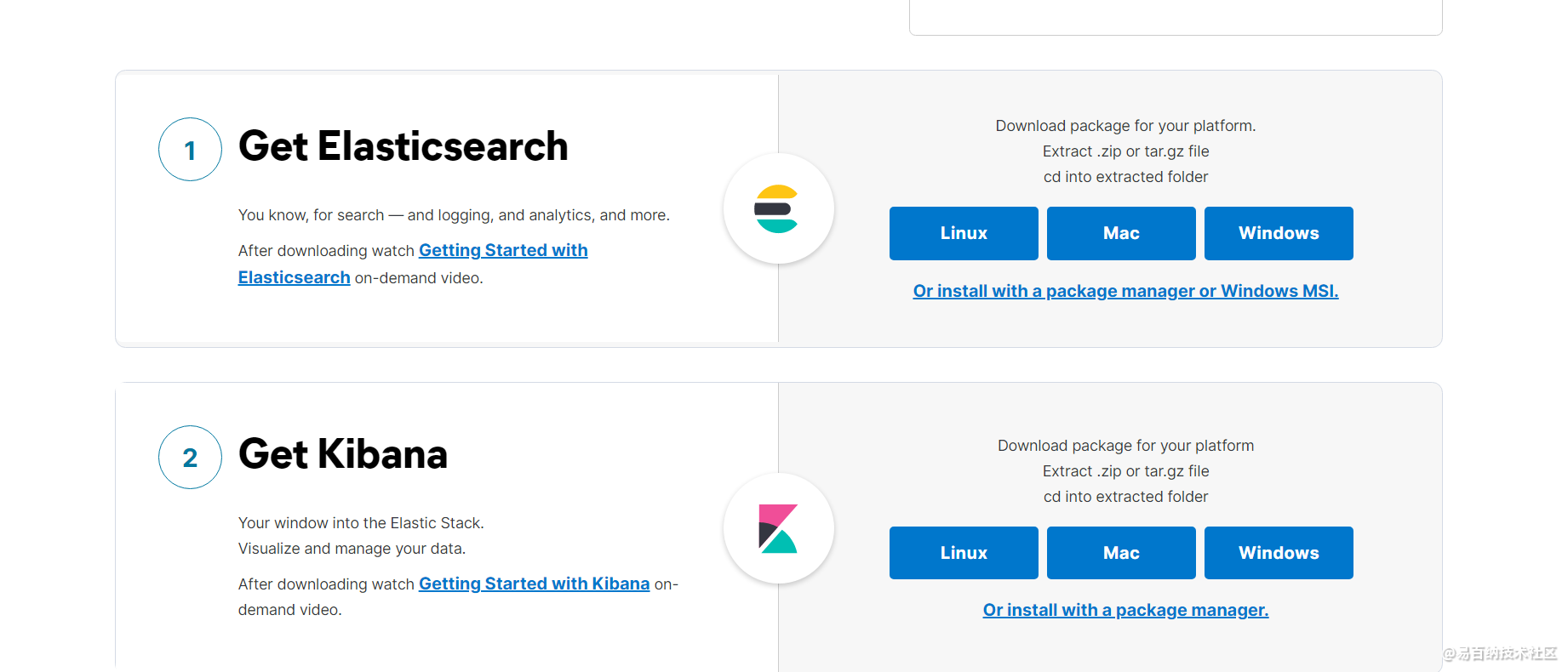 Kibana 是一个免费且开放的用户平台,能够让我们对 Elasticsearch 数据进行可视化,这里我们也一并将其下载到本地
Kibana 是一个免费且开放的用户平台,能够让我们对 Elasticsearch 数据进行可视化,这里我们也一并将其下载到本地

上传安装包到linux并解压
我的习惯是将所有的软件包放到/export/software目录下,解压后的目录是/export/servers
[root@node01 software]# tar -zxvf elasticsearch-7.11.0-linux-x86_64.tar.gz -C ../servers/目录结构
解压完毕之后,我们先来熟悉es的目录结构
[root@node01 elasticsearch-7.11.0]# ll /export/servers/elasticsearch-7.11.0
总用量 556
drwxr-xr-x. 2 esuser esuser 4096 2月 9 06:48 bin
drwxr-xr-x. 3 esuser esuser 199 2月 13 14:44 config
drwxr-xr-x. 3 esuser esuser 19 2月 13 14:15 data
drwxr-xr-x. 9 esuser esuser 107 2月 9 06:48 jdk
drwxr-xr-x. 3 esuser esuser 4096 2月 9 06:48 lib
-rw-r--r--. 1 esuser esuser 3860 2月 9 06:41 LICENSE.txt
drwxr-xr-x. 2 esuser esuser 6 2月 13 14:47 logs
drwxr-xr-x. 57 esuser esuser 4096 2月 9 06:49 modules
-rw-r--r--. 1 esuser esuser 544318 2月 9 06:46 NOTICE.txt
drwxr-xr-x. 2 esuser esuser 6 2月 9 06:45 plugins
-rw-r--r--. 1 esuser esuser 7263 2月 9 06:41 README.asciidoc其中我们常用的目录有:
- bin:可执行文件在里面,运行es的命令就在这个里面,包含了一些脚本文件等
- config:配置文件目录
- JDK:java环境
- lib:依赖的jar,类库
- logs:日志文件
- modules:es相关的模块
- plugins:可以自己开发的插件
- data:这个目录没有,自己新建一下,后面要用 -> mkdir data,这个作为索引目录
修改配置文件
熟悉完es的目录,在启动es前,我们还需要修改一些配置文件
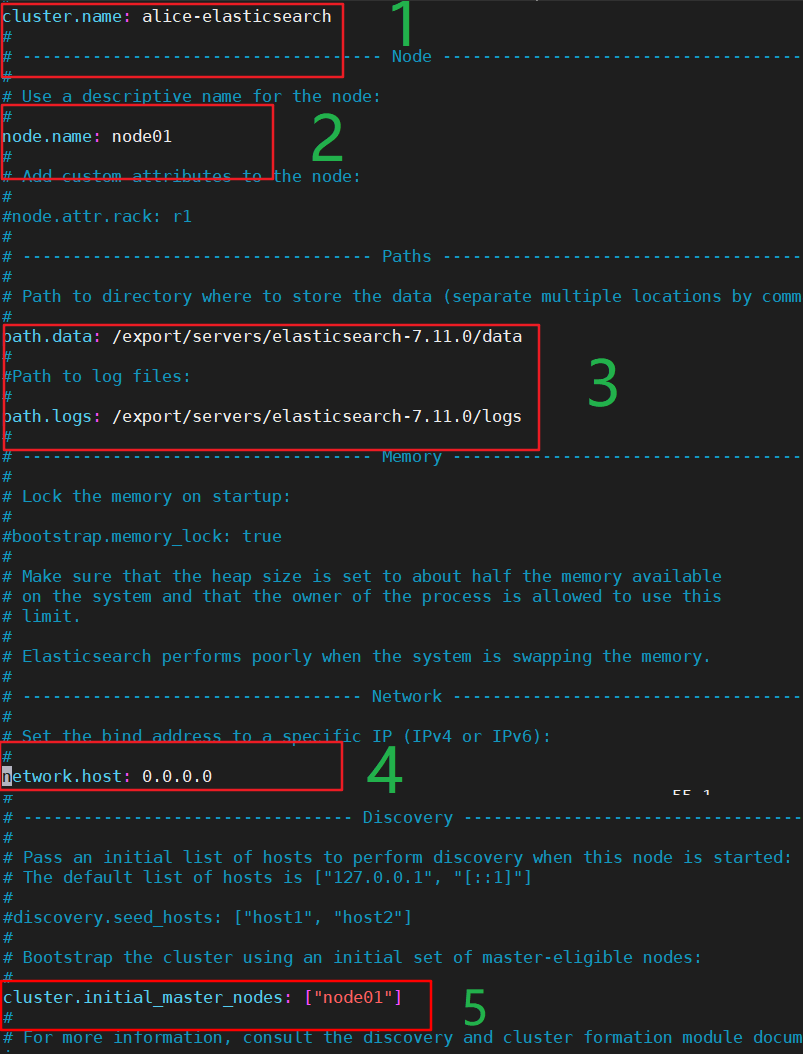
核心配置文件 elasticearch.yml
[root@node01 elasticsearch-7.11.0]# vim config/elasticsearch.yml- 修改集群名称
- 修改当前的 es 节点名称
- 修改data数据保存地址和日志数据保存地址
- 绑定 es 网络 ip
- 集群节点修改为之前的节点名称
具体位置如下图所示:
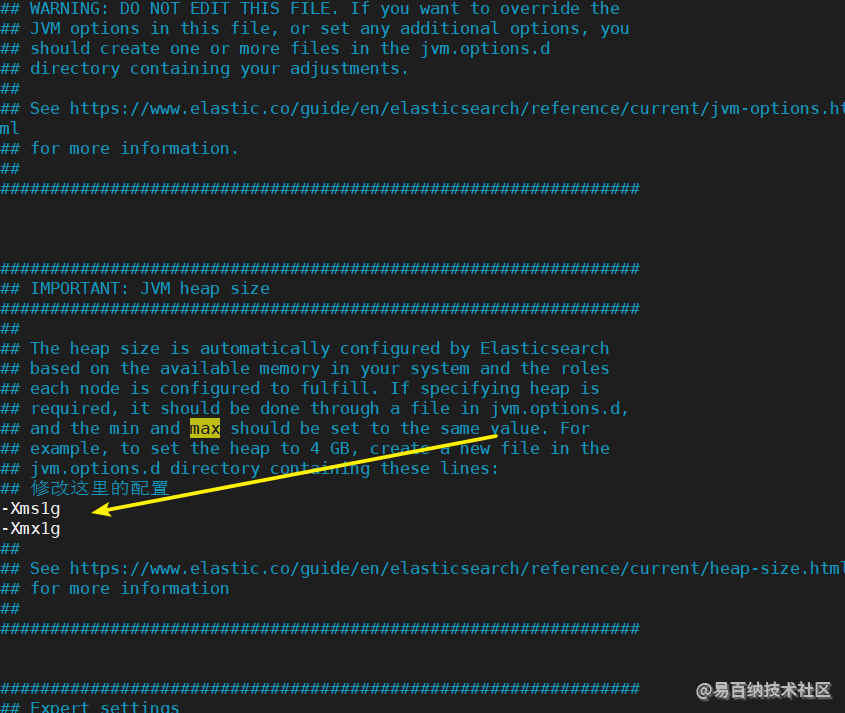
修改 jvm 参数
因为 Elasticsearch 是用 Java 语言开发的,所以我们在配置环节一定少不了修改 jvm 的参数
[root@node01 elasticsearch-7.11.0]# vim config/jvm.options 根据自己当前操作系统的不同配置,设置不同的大小即可
添加用户
比较有意思的一点是,es不允许使用 root 来操作 es,需要我们添加用户,具体的命令如下:
# 1. 创建elsearch用户组及elsearch用户:
groupadd elsearch
useradd elsearch -g elsearch
passwd elsearch# 接下来会输入两次密码
# new password
# retype passwd
# 2. 切换到elsearch用户再启动
su elsearch启动es
修改完上面2个配置文件,我们切换到bin目录下,通过./elasticsearch启动es
不出意外,应该会报如下错误:
ERROR: [3] bootstrap checks failed
[1]: max file descriptors [4096] for elasticsearch process is too low, increase to at least [65535]
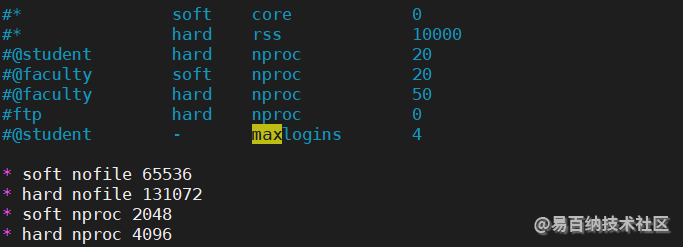
[2]: max number of threads [3795] for user [esuser] is too low, increase to at least [4096]我们只需要将最大的线程数设置大一些即可
我们切换回到root目录
- 修改
/etc/security/limits.conf文件
添加以下内容
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096 如下图所示:
- 修改 /etc/sysctl.conf 增加
vm.max_map_count=262145
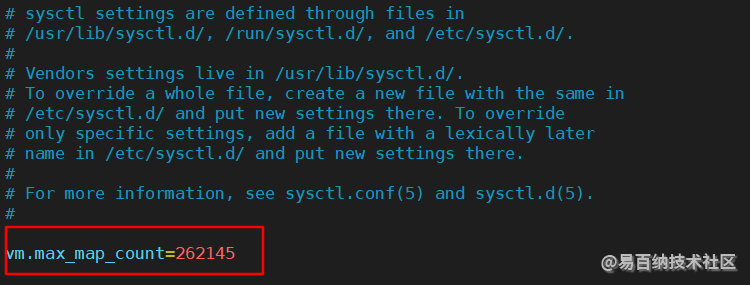 修改完成之后,使用
修改完成之后,使用sysctl -p命令刷新一下,再次切换到 esuser进行启动即可。
记得将防火墙关闭或者将9200端口打开,否则就会出现启动成功,页面无法访问的情况
启动与暂停
启动与暂停这里也分成2种形式
启动方式1
我们在bin目录下直接./elasticsearch,可以看到运行结果
 然后根据自己的
然后根据自己的 ip:9200进行访问,可以在界面上看到如下返回的结果
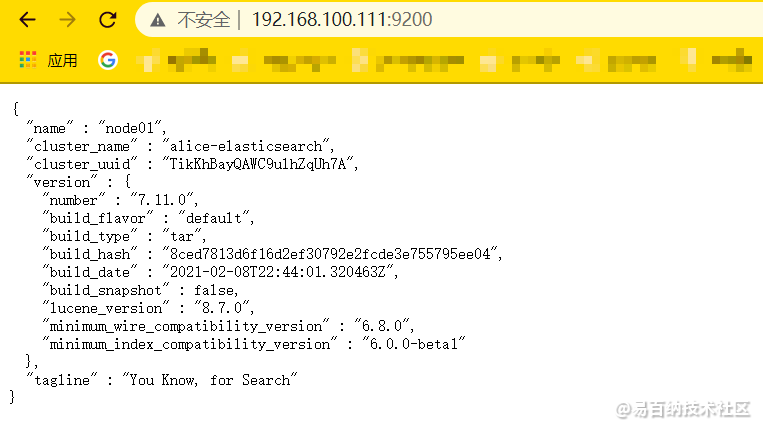 当前启动方式是前端启动。停止服务的话直接ctrl+c 就好了
当前启动方式是前端启动。停止服务的话直接ctrl+c 就好了
启动方式2
同时,我们也可以后端启动
[esuser@node01 bin]$ ./elasticsearch -d稍等片刻,再次访问地址,还是相同结果
此时,如果想关闭服务
[esuser@node01 bin]$ ps -ef|grep elasticsearch
esuser 2931 2178 0 15:58 pts/0 00:00:00 grep --color=auto elasticsearch然后将对应的进程id kill掉即可!
接下来我们需要安装ES的图形化界面插件,也就是elasticsearch-head,这里介绍2种方法,方法1比较麻烦,想省事的同学可以直接划到下方的方法2,利用谷歌插件进行安装,简单高效!
安装elasticsearch-head(方法1)
elasticsearch-head是一款开源软件,被托管在github上面,所以如果我们要使用它,必须先安装git,通过git获取elasticsearch-head
给大家看下这个项目,已经斩获 7.3K 的start,说明还是非常受大众欢迎
 我们很容易的通过 git 将其clone到本地,然后上传到 linux 服务器上,然后解压。
我们很容易的通过 git 将其clone到本地,然后上传到 linux 服务器上,然后解压。
需要注意的是, 运行elasticsearch-head会用到 grunt,而 grunt 需要 npm 包管理器,所以 nodejs 是必须要安装的
安装npm
当然如果你的环境里已经安装好了npm,那则可以跳过这一步。
(1) 安装gcc
yum install gcc gcc-c++(2) 下载node国内镜像(推荐)
wget https://npm.taobao.org/mirrors/node/v10.14.1/node-v10.14.1-linux-x64.tar.gz(3) 解压并重命名文件夹
解压
tar -xvf node-v10.14.1-linux-x64.tar.gz然后重命名文件夹
mv node-v10.14.1-linux-x64 node(4) 添加环境变量
vi /etc/profile在文件最后添加以下配置:
export NODE_HOME=/export/servers/node
export PATH=$NODE_HOME/bin:$PATH(5) 刷新配置
source /etc/profile(6) 验证结果
node -v
npm -v 能够正确显示版本号即说明 nodejs 环境安装成功

安装cnpm
我们上面谈到的 npm 命令是 node.js 的 npm 插件管理器,也就是下载插件安装插件的管理器。但我们在使用的时候,下载的都是国外服务器很慢会掉线,所以这一步,我们需要安装淘宝的 npm 镜像cnpm。
也非常简单,执行如下命令即可
npm install -g cnpm --registry=https://registry.npm.taobao.org排雷:如果遇到
this is a problem related to network connectivity, behind a proxy的异常,执行npm config set proxy null将代理设置为空即可再重试上面的命令即可。
cnpm 正常安装完成之后呢,效果图如下:

下载依赖
现在环境都准备好了,那我们该做些什么呢?其实 GitHub 上都已经写明白了
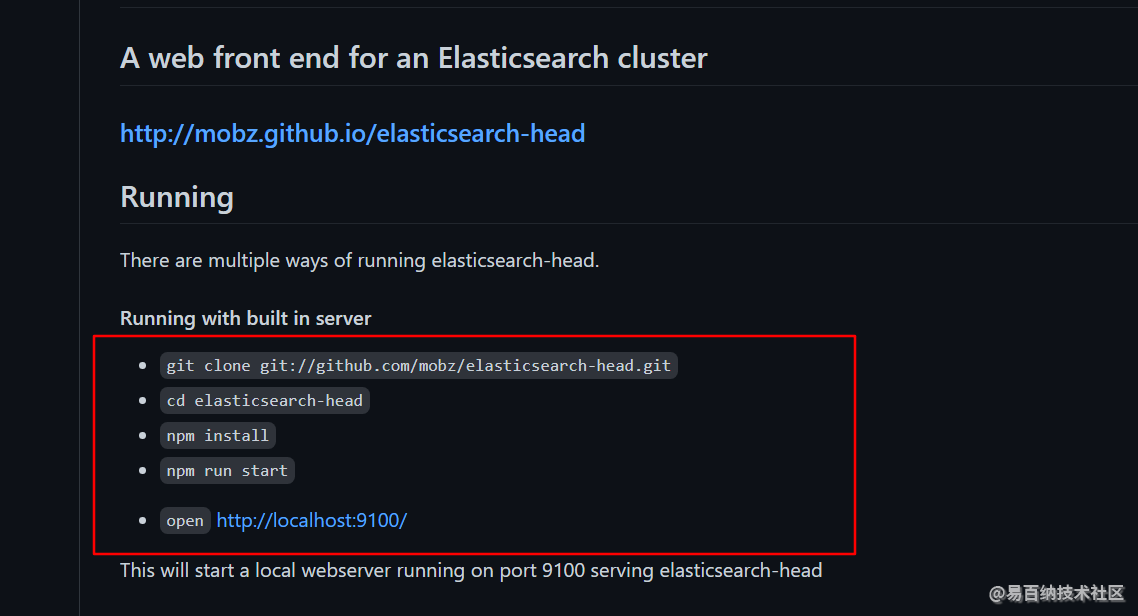 有多种方式运行 elasticsearch-head ,我们这里需要用的就是如上所示的内置服务器的方式。
有多种方式运行 elasticsearch-head ,我们这里需要用的就是如上所示的内置服务器的方式。
我们进入到elasticsearch-head的目录下,执行命令,下载相关的依赖
[root@node01 elasticsearch-head]# cnpm install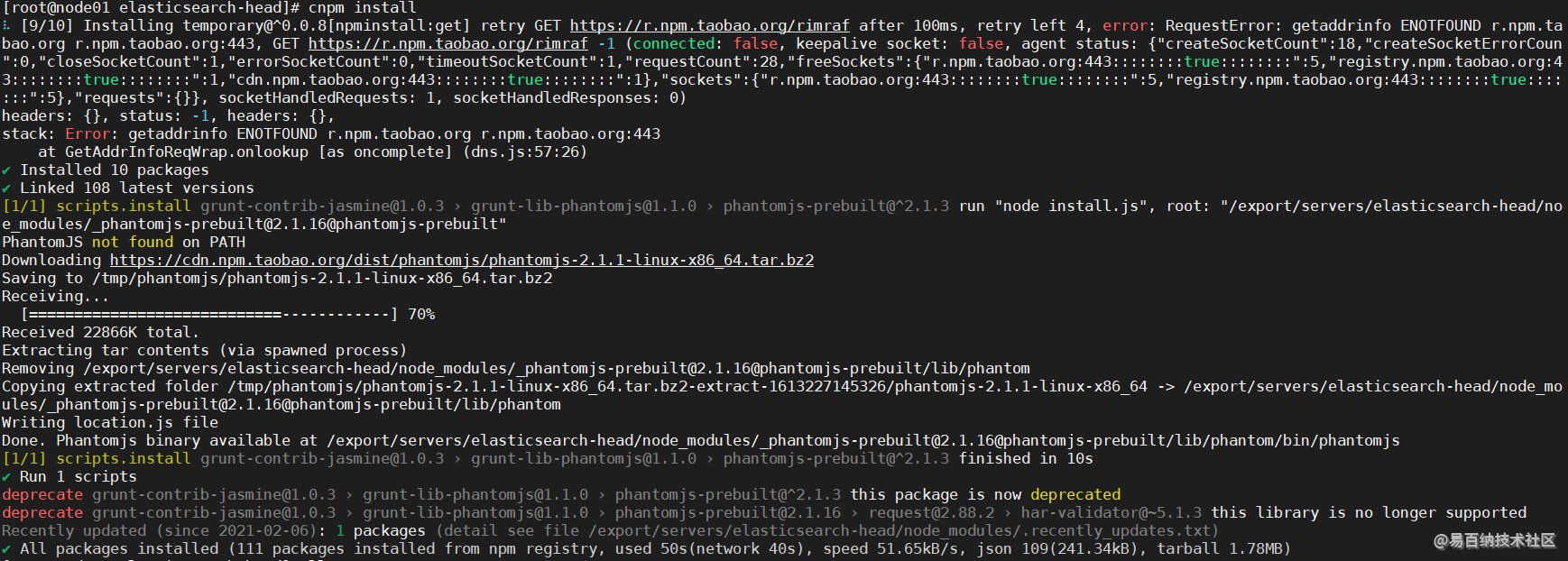 命令执行完毕之后,我们可以在目录下看到多出了
命令执行完毕之后,我们可以在目录下看到多出了node_modules目录,这就是我们下载好的依赖。
 然后在该目录下执行
然后在该目录下执行npm run start命令,启动 elasticsearch-head
[root@node01 elasticsearch-head]# npm run start
> elasticsearch-head@0.0.0 start /export/servers/elasticsearch-head
> grunt server
Running "connect:server" (connect) task
Waiting forever...
Started connect web server on http://localhost:9100 然后我们就可以在浏览器上通过 ip:9100 访问到如下页面,但是当我们点击连接,在控制台又会出现 Error 信息,这是为什么呢?
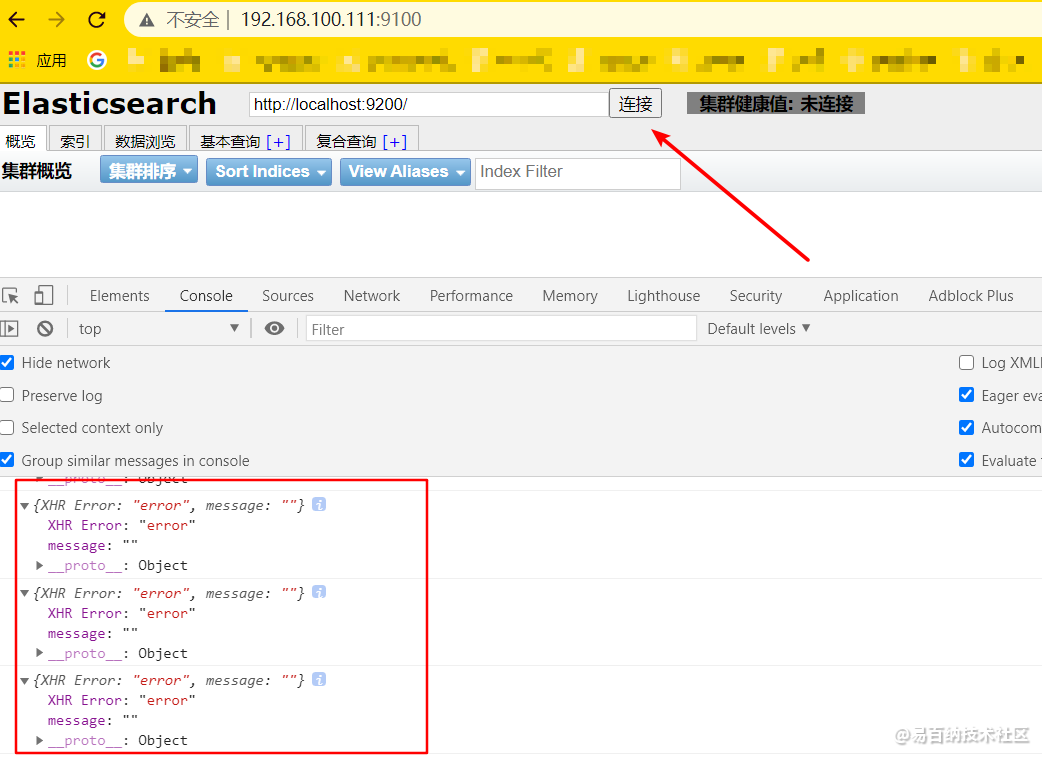 真相:由于ES进程和客户端进程端口号不同,存在跨域问题,所以我们要在ES的配置文件中添加如下配置下:
真相:由于ES进程和客户端进程端口号不同,存在跨域问题,所以我们要在ES的配置文件中添加如下配置下:
[root@node01 elasticsearch-7.11.0]# vim config/elasticsearch.yml
# 跨域配置
http.cors.enabled: true
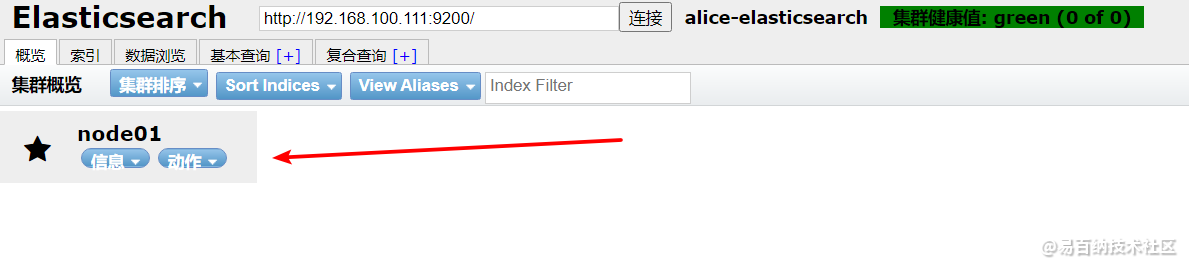
http.cors.allow-origin: "*"配置完毕,我们重启ES,重新连接,就能正常看到正常的页面了
安装elasticsearch-head(方法2)
不知道大家有没有对于操作到这一步,在想着有没有更简单的方式安装 elasticsearch-head 呢?
当然有,我们在 readme 文件中,发现也可以通过在谷歌浏览器上使用插件的形式来进行安装 elasticsearch-head
 我们在谷歌应用商店搜索“elasticsearch-head”插件,然后将其安装,自动添加至谷歌浏览器
我们在谷歌应用商店搜索“elasticsearch-head”插件,然后将其安装,自动添加至谷歌浏览器
 然后使用的时候,直接单击这个插件,就可以看见与我们按照上面那么繁杂的步骤所展示一致的界面。
然后使用的时候,直接单击这个插件,就可以看见与我们按照上面那么繁杂的步骤所展示一致的界面。
 嗯,果然还是这种方法香!
嗯,果然还是这种方法香!
如果是初学的小伙伴,就算成功看到这个页面可能还有点懵,因为现在这个网站上还没有什么东西
我们初学,就把 es 当做一个数据库,可以建立索引(库),文档(库中的数据!)
现在还没有索引,我这里就先创建了一个alice索引
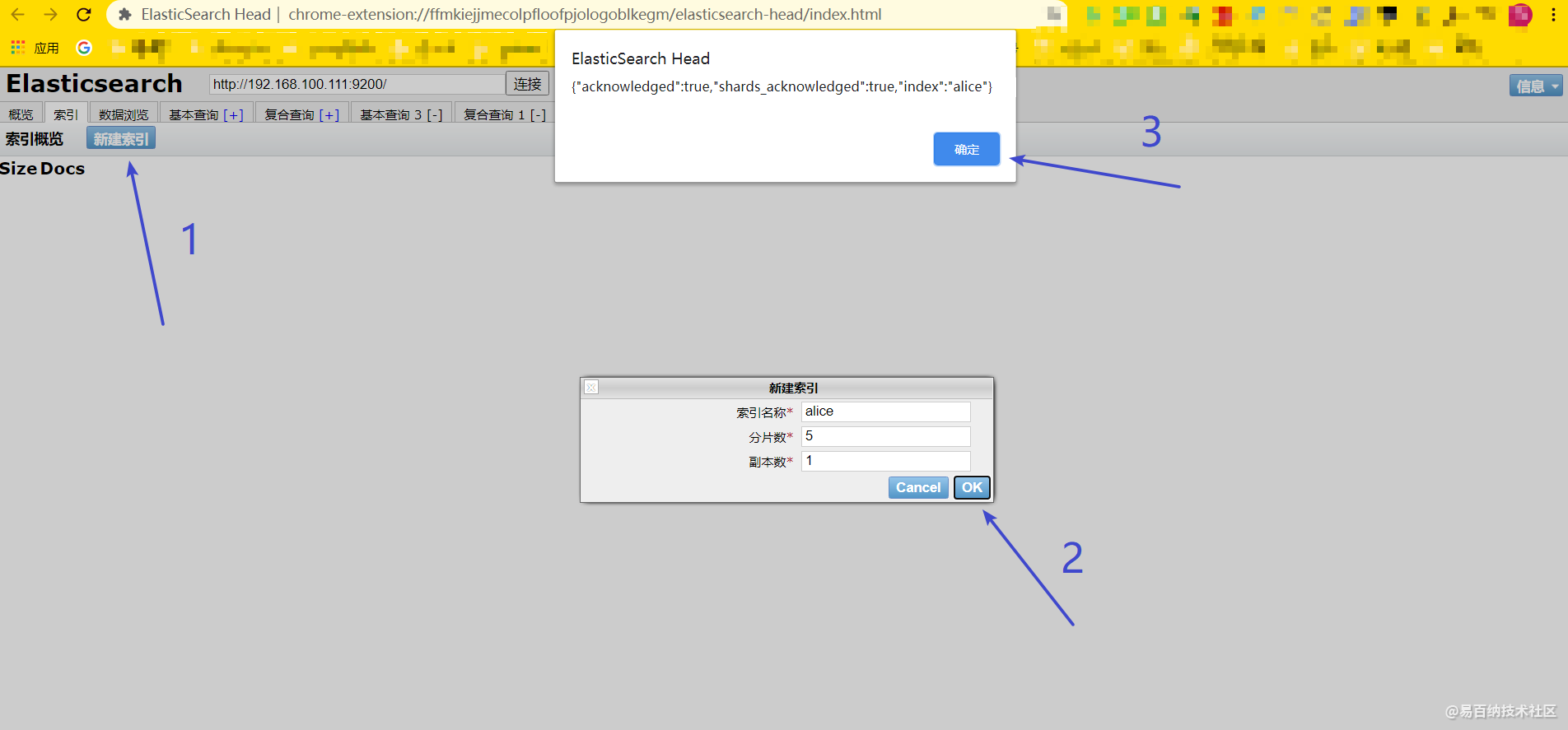 然后就可以在
然后就可以在概览栏看见分片信息,索引栏看见自己创建的索引,数据浏览栏看到索引里的所有数据!
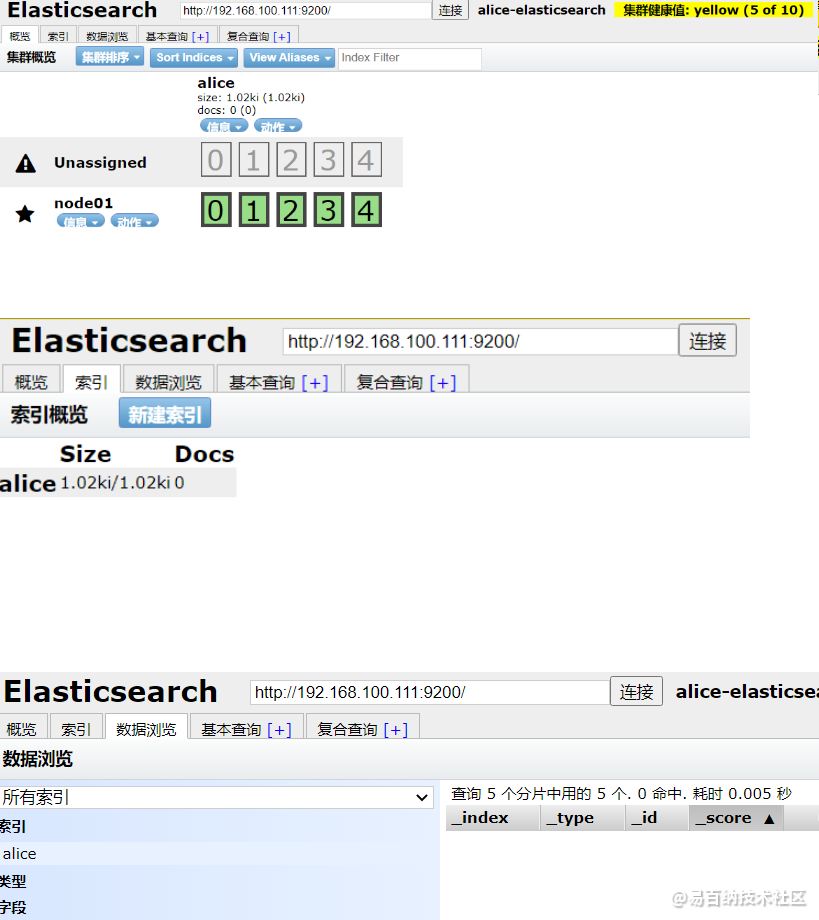 另外,
另外,elasticsearch-head上也提供了基本查询和复合查询的方式,其中复合查询是以 restful风格发起的请求,并且提交的参数都是格式化后的JSON类型。
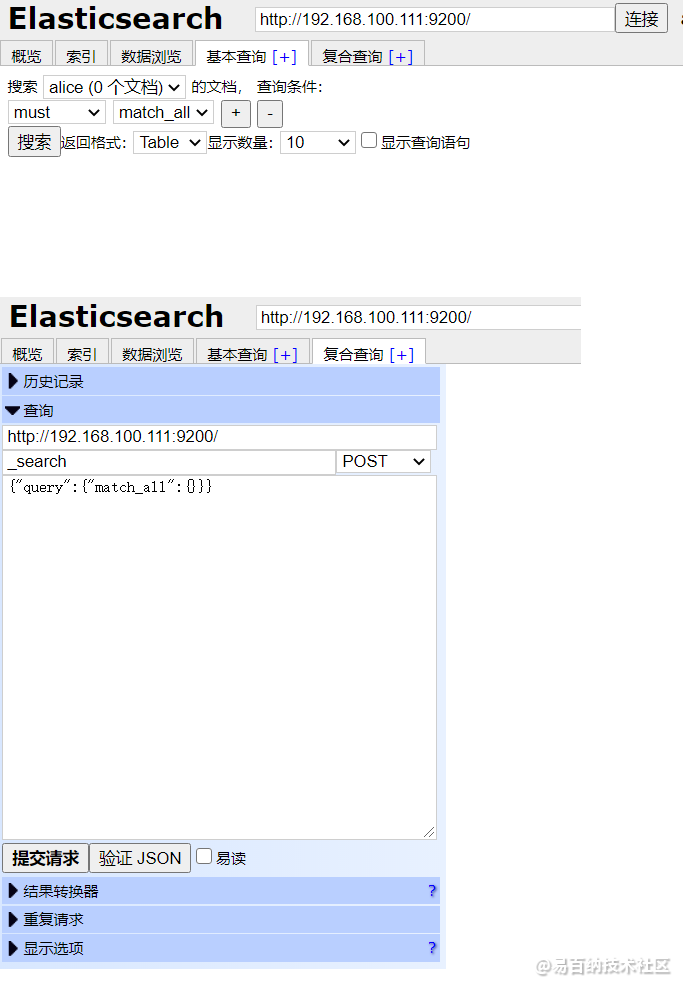 当然,大家也可能都看到了,这样的工具我们使用起来也不是很方便,这个 elasticsearch-head 我们一般就把它当做数据展示的工具,不建议利用它来进行数据的查询,我们所有的查询,基本都放在 Kibana 中完成
当然,大家也可能都看到了,这样的工具我们使用起来也不是很方便,这个 elasticsearch-head 我们一般就把它当做数据展示的工具,不建议利用它来进行数据的查询,我们所有的查询,基本都放在 Kibana 中完成
安装Kibana
了解ELK
ELK是
Elasticsearch、Logstash、Kibana三大开源框架首字母大写简称。市面上也被成为 ElasticStack 。其中 Elasticsearch 是一个基于 Lucene、分布式、通过 Restful 方式进行交互的近实时搜索平台框架。像类似百度、谷歌这种大数据全文搜索引擎的场景都可以使用 Elasticsearch 作为底层支持框架,可见 Elasticsearch 提供的搜索能力确实强大,市面上很多时候我们简称Elasticsearch为es。Logstash是 ELK 的中央数据流引擎,用于从不同目标(文件/数据存储/MQ)收集的不同格式数据,经过过滤后支持输出到不同目的地(文件/MQ/redis/elasticsearch/kafka等)。Kibana可以将 elasticsearch 的数据通过友好的页面展示出来,提供实时分析的功能。
看了上面的描述,我们大概心里就已经清楚,ELK 的流程大致就是 收集清理数据 -> 搜索,存储 -> Kibana,如下所示:
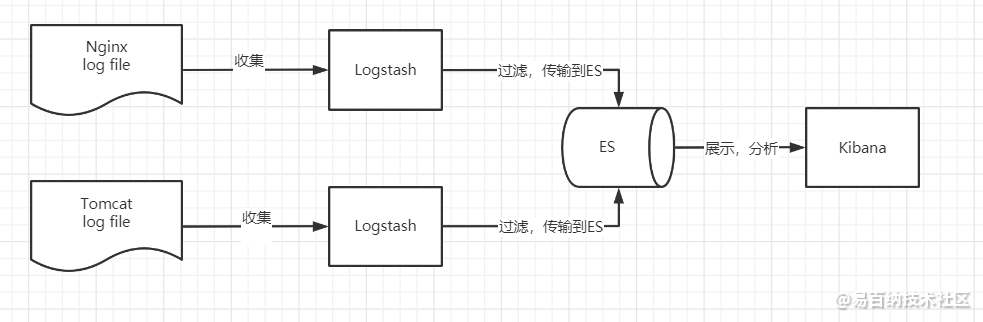
市面上很多开发只要提到 ELK 能够一致说出它是一个日志分析架构技术栈 总称,但实际上 ELK 不仅仅适用于日志分析,它还可以支持其它任何数据分析和收集的场景,日志分析和收集只是更具有代表性,并非唯一性。
Kibana的安装
Kibana是一个针对Elasticsearch的开源分析及可视化平台,用来搜索、查看交互存储在 Elasticsearch 索引中的数据。使用 Kibana ,可以通过各种图表进行高级数据分析及展示。Kibana 让海量数据更容易理解。它操作简单,基于浏览器的用户界面可以快速创建仪表板(dashboard)实时显示Elasticsearch 查询动态。设置Kibana非常简单。无需编码或者额外的基础架构,几分钟内就可以完成 Kibana 安装并启动 Elasticsearch 索引监测。
官网地址:https://www.elastic.co/cn/kibana
 然后选择对应操作系统的版本,默认安装的就是最新版本的 kibana。注意:kibana 版本 要和 es 的版本一致!
然后选择对应操作系统的版本,默认安装的就是最新版本的 kibana。注意:kibana 版本 要和 es 的版本一致!
 下载完毕后,同样上传到Linux服务器,解压
下载完毕后,同样上传到Linux服务器,解压
[root@node01 software]# tar -zxvf kibana-7.11.0-linux-x86_64.tar.gz -C ../servers/ 修改conf目录下的kibana.yml文件,添加上如下的几行配置
 然后切回到 bin 目录下,直接
然后切回到 bin 目录下,直接 ./kibana 启动即可,此时通过ip:5601 即可正常访问到页面
 英文不好的同学是不是感觉看着有些吃力。其实,kibana 有自带的中文包,就在kibana 的
英文不好的同学是不是感觉看着有些吃力。其实,kibana 有自带的中文包,就在kibana 的 x-pack/plugins/translations/translations 目录下的 zh-CN.json
 我们想要使用,直接打开conf目录下的
我们想要使用,直接打开conf目录下的kibana.yml文件
 我们可以看到 kibana 默认的语言是 英文,我们只需要添加使用中文插件即可
我们可以看到 kibana 默认的语言是 英文,我们只需要添加使用中文插件即可
i18n.locale: "zh-CN" 然后重新启动 kibana ,即可看到效果
踩坑
kibana 启动,可能会遇到这个 bug:
Error: Unable to write Kibana UUID file, please check the uuid.server configuration value in kibana.yml and ensure Kibana has sufficient permissions to read / write to this file. Error was: EACCES解决方案 就是:
# 在root下为 为kibana赋权
chown -R elsearch:elsearch /export/servers/kibana-7.6.1-linux-x86_64/
# 修改kibana所在文件夹的权限
chmod 770 /export/servers/kibana-7.6.1-linux-x86_64
# 切换回用户组 elsearch
su elsearch
# 启动
./kibanaES的核心概念
概述
在前面的学习中,我们已经掌握了 es 是什么,同时也把 es 的服务已经安装启动,那么 es 是如何去存储数据,数据结构是什么,又是如何实现搜索的呢?我们先来聊聊 ElasticSearch的相关概念 吧
集群,节点,索引,类型,文档,分片,映射是什么?
对比
ElasticSearch 是面向文档的非关系型数据库,下面让我们来看看它与关系型数据库的客观对比!
| Relational DB | Elasticsearch |
|---|---|
| 数据库(database) | 索引(indices) |
| 表(tables) | types |
| 行(rows) | documents |
| 字段(columns) | fields |
elasticsearch(集群)中可以包含多个索引(数据库),每个索引中可以包含多个类型(表),每个类型下又包含多个文档(行),每个文档中又包含多个字段(列)
物理设计:
elasticsearch 在后台把每个索引划分成多个分片,每份分片可以在集群中的不同服务器间迁移
逻辑设计:
一个索引类型中,包含多个文档,比如说文档1,文档2。 当我们索引一篇文档时,可以通过这样的一个顺序找到 它: 索引 ▷ 类型 ▷ 文档ID ,通过这个组合我们就能索引到某个具体的文档。 注意 : ID不必是整数,实际上它是个字符串。
文档
之前说 elasticsearch 是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch 中,文档有几个 重要属性 :
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含 key:value!
- 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的!其实就是个JSON对象
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在 elasticsearch 中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整形。因为 elasticsearch 会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型,这也是为什么在 elasticsearch 中,类型有时候也称为映射类型。
类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。 类型中对于字段的定义称为映射,比如 name 映 射为字符串类型。 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 elasticsearch 是怎么做的呢?elasticsearch会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch就开始猜,如果这个值是18,那么elasticsearch会认为它是整形。 但是elasticsearch也可能猜不对, 所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用。
索引
索引是映射类型的容器,elasticsearch 中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。 然后它们被存储到了各个分片上了。 我们来研究下分片是如何工作的。
物理设计 :节点和分片如何工作
一个集群至少有一个节点,而一个节点就是一个 elasricsearch 进程,节点可以有多个索引默认的,如果你创建索引,那么索引将会有个5个分片 ( primary shard ,又称主分片 ) 构成的,每一个主分片会有一个副本 ( replica shard ,又称复制分片 )
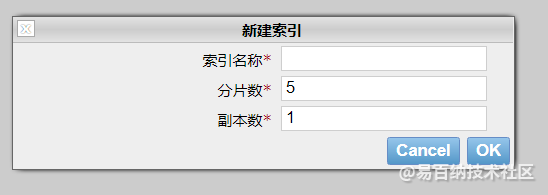 下图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉 了,数据也不至于丢失。
下图是一个有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉 了,数据也不至于丢失。
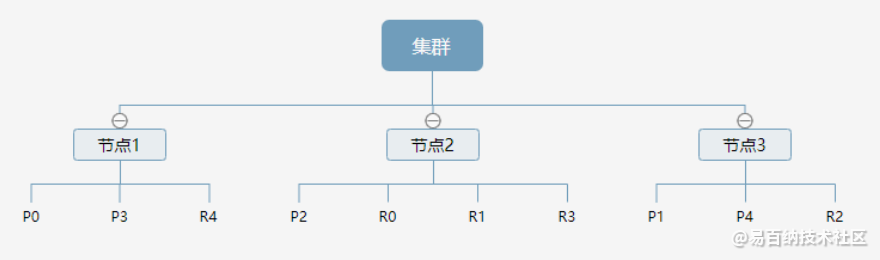 实际上,一个分片是一个
实际上,一个分片是一个 Lucene 索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字。 不过,等等,倒排索引是什么鬼?
倒排索引
elasticsearch 使用的是一种称为倒排索引的结构,采用Lucene倒排索引作为底层。这种结构适用于快速的全文搜索, 一个索引由文档中所有不重复的列表构成,对于每一个词,都有一个包含它的文档列表。 例如,现在有两个文档, 每个文档包含如下内容:
Study every day, good good up to forever # 文档1包含的内容
To forever, study every day, good good up # 文档2包含的内容 为了创建倒排索引,我们首先要将每个文档拆分成独立的词(或称为词条或者tokens),然后创建一个包含所有不重复的词条的排序列表,然后列出每个词条出现在哪个文档 :
 现在,我们试图搜索
现在,我们试图搜索 to forever,只需要查看包含每个词条的文档
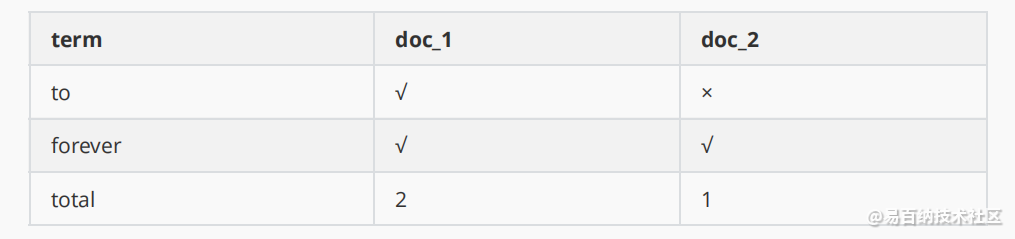 两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
两个文档都匹配,但是第一个文档比第二个匹配程度更高。如果没有别的条件,现在,这两个包含关键字的文档都将返回。
再来看一个示例,比如我们通过博客标签来搜索博客文章。那么倒排索引列表就是这样的一个结构 :
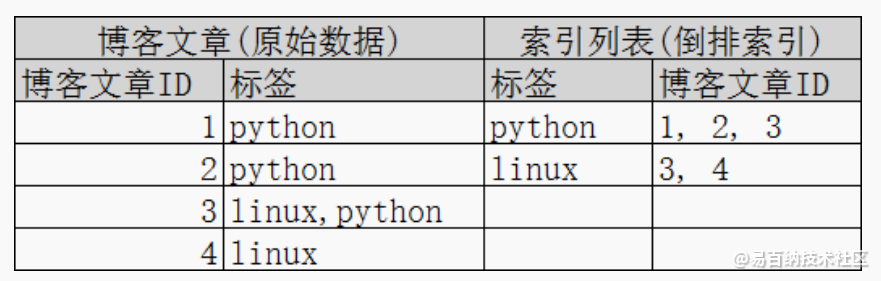 如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要 查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
如果要搜索含有 python 标签的文章,那相对于查找所有原始数据而言,查找倒排索引后的数据将会快的多。只需要 查看标签这一栏,然后获取相关的文章ID即可。完全过滤掉无关的所有数据,提高效率!
在 elasticsearch 中, 索引这个词被频繁使用,这就是术语的使用。在 elasticsearch 中,索引被分为多个分片,每份分片是一个 Lucene 的索引。所以 一个 elasticsearch 索引是由多个Lucene索引组成的。别问为什么,谁让elasticsearch使用Lucene作为底层呢! 如无特指,说起索引都是指elasticsearch的索引。
ES基础操作
IK 分词器
什么是IK分词器?
分词:即把一段中文或者别的内容划分成一个个的关键字,我们在搜索时候会把自己的信息进行分词,是因为数据库中或者索引库中的数据也会进行分词,然后进行一个匹配操作,默认的中文分词是将每个字看成一个词,比如 “我爱大数据” 会被分为"我","爱","大", "数","据",这显然是不符合要求的,所以我们需要安装中文分词器 ik 来解决这个问题。
提前说一嘴,IK提供了两个分词算法:ik_smart 和 ik_max_word ,其中 ik_smart 为最少切分,ik_max_word 为 最细粒度划分!这个我们后面会来进行测试。
安装步骤
1、下载ik分词器的包,Github地址:https://github.com/medcl/elasticsearch-analysis-ik/ (版本要对
应)。但目前我们es的版本是7.11,而现在发布的最新 ik 分词器的版本也才 7.10.2,那我们就先下载最新的版本
 2. 然后直接在软件包的存储目录下,直接执行命令:
2. 然后直接在软件包的存储目录下,直接执行命令:
[root@node01 software]# wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.10.2/elasticsearch-analysis-ik-7.10.2.zip3. 解压下载好的压缩包,注意,解压路径必须放在 es 的 plugins 目录下
[root@node01 software]# unzip elasticsearch-analysis-ik-7.10.2.zip -d ../servers/elasticsearch-7.11.0/plugins/ik4. 给文件夹权限
[root@node01 plugins]# chmod 777 ik 5. 正常情况下我们重启 Elasticsearch 即可看到插件加载的日志,但是很遗憾,终究因为版本不同的问题,导致 es 无法重启成功
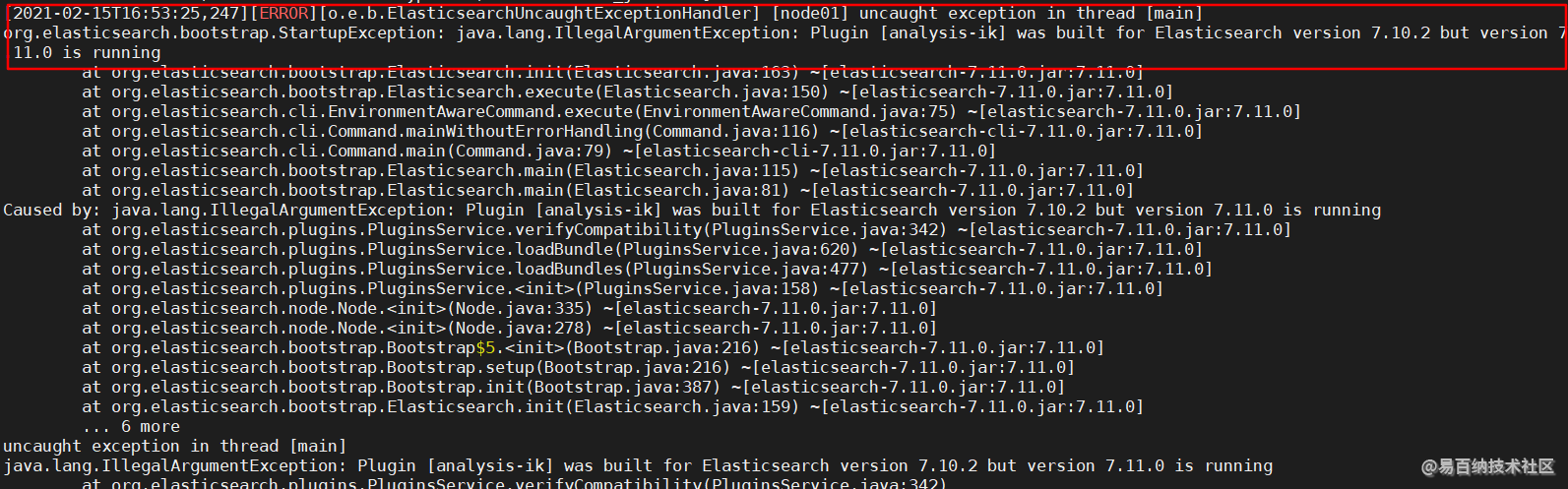 所以关于分词器的部分就先停更,等到 ik 分词器出到 7.11 版本,再做更新???这是不可能的,所以我先用其他服务器上的一个 6.5.4 版本的 es 来做测试。
所以关于分词器的部分就先停更,等到 ik 分词器出到 7.11 版本,再做更新???这是不可能的,所以我先用其他服务器上的一个 6.5.4 版本的 es 来做测试。
然后我们打开 6.5.4 版本的 kibana 界面,可以发现跟我们最新下载的7.11 版本的 kibana 界面还是区别还是挺大的!
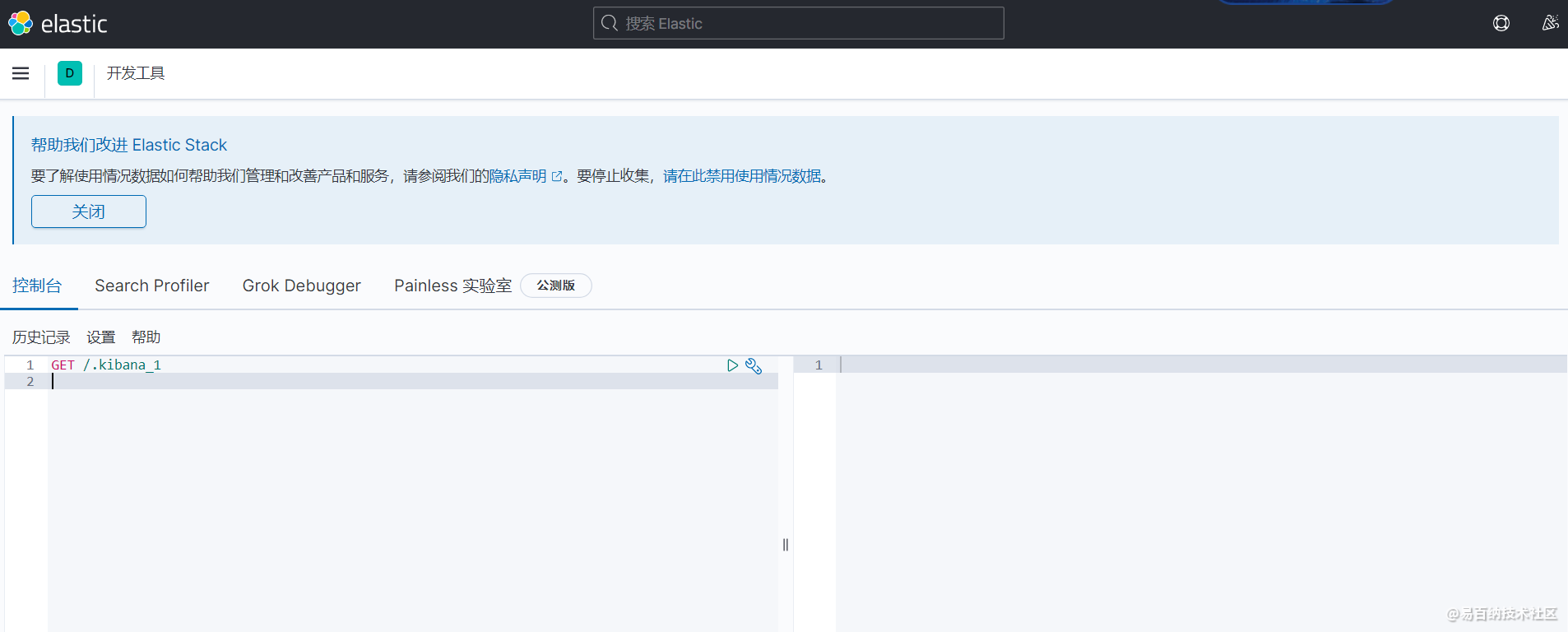
 但这并不影响我们接下来的操作,进入
但这并不影响我们接下来的操作,进入Dev Tools工具栏界面,先尝试用过 ik_smart 最少切分,发起一个 GET 请求
GET _analyze
{
"analyzer":"ik_smart",
"text": "梦想家"
} 返回的结果如下:
 那我们再用相同的文字测试一次
那我们再用相同的文字测试一次ik_max_word 最细粒度划分:
GET _analyze
{
"analyzer":"ik_max_word",
"text": "梦想家"
} 此时返回的结果:
 此时,相信已经有聪明的小伙伴能得出下面的结论:
此时,相信已经有聪明的小伙伴能得出下面的结论:
ik_max_word是细粒度分词,会穷尽一个语句中所有分词可能ik_smart是粗粒度分词,优先匹配最长词,不会有重复的数据
那大家有没有想过细粒度分词穷尽词库的可能,那词库是哪里的?一定是存在有类似"字典"这样的东西,不相信的话, 我们再用细粒度分词ik_max_word来做个测试
GET _analyze
{
"analyzer":"ik_smart",
"text": "超级喜欢狂神说"
} 此时返回的结果:
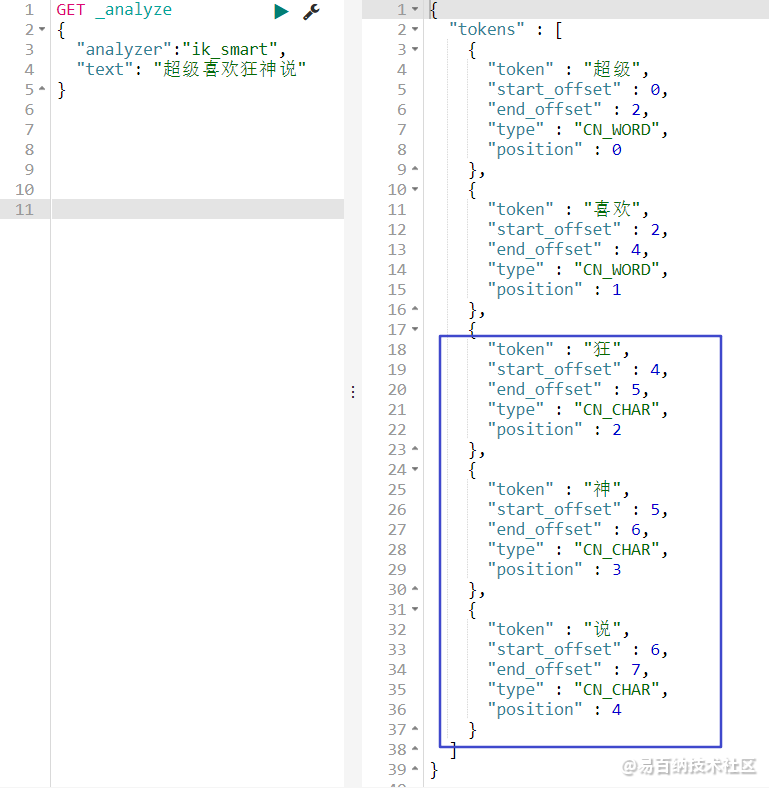
可以发现此时狂神说几个字被拆开了,那如果我们想让系统识别“狂神说”是一个词,就需要我们编辑自定义词库。
步骤同样非常简单:
(1) 进入elasticsearch/plugins/ik/config目录
(2) 新建一个my.dic文件,编辑内容:
狂神说(3) 修改IKAnalyzer.cfg.xml(在 ik/config 目录下)
<properties>
<comment>IK Analyzer 扩展配置</comment> <!-- 用户可以在这里配置自己的扩展字典 -->
<entry key="ext_dict">my.dic</entry> <!-- 用户可以在这里配置自己的扩展停止词字典 -->
<entry key="ext_stopwords"></entry>
</properties> 修改完配置重新启动 elasticsearch,再次测试!
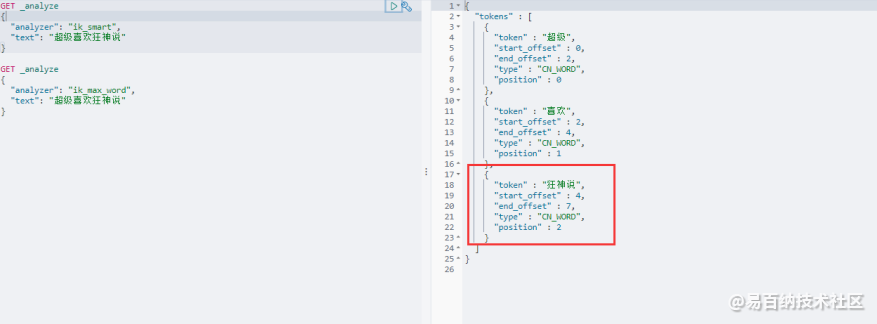 此时可以发现,狂神说已经变成了一个词了~
此时可以发现,狂神说已经变成了一个词了~
到了这里,我们就明白了分词器的基本规则和使用了!实际上搜索引擎做的最重要的一件事,就是分词!它需要将我们搜索的内容进行关键字的拆分,然后展示对应的信息。那这些被拆分出来的词是如何划分权重的呢?不用担心,马上我们就来开始学习 es 基本的增删改查!
Rest风格说明
什么是 Rest 风格呢?
一种软件架构风格,而不是标准,只是提供了一组设计原则和约束条件。它主要用于客户端和服务器交互类的软件。基于这个风格设计的软件可以更简洁,更有层次,更易于实现缓存等机制。
其中 基本 的 Rest 命令说明:
| method | url地址 | 描述 |
|---|---|---|
| PUT | localhost:9200/索引名称/类型名称/文档id | 创建文档(指定文档 id ) |
| POST | localhost:9200/索引名称/类型名称 | 创建文档(随机文档 id ) |
| POST | localhost:9200/索引名称/类型名称/文档id/_update | 修改文档 |
| DELETE | localhost:9200/索引名称/类型名称/文档id | 删除文档 |
| GET | localhost:9200/索引名称/类型名称/文档id | 通过文档id查询文档 |
| POST | localhost:9200/索引名称/类型名称/_search | 查询所有数据 |
那接下来我们就用之前已经安装好的 kibana 进行一个基础测试
关于索引的基本操作
基础测试
- 创建一个索引
PUT /索引名/类型名/文档id {请求id}
根据网址:ip:5601打开我们的 kibana 的页面,进入到开发工具栏,在 Console 中输入 :
// 命令解释
// PUT 创建命令 test1 索引 type1 类型 1 id
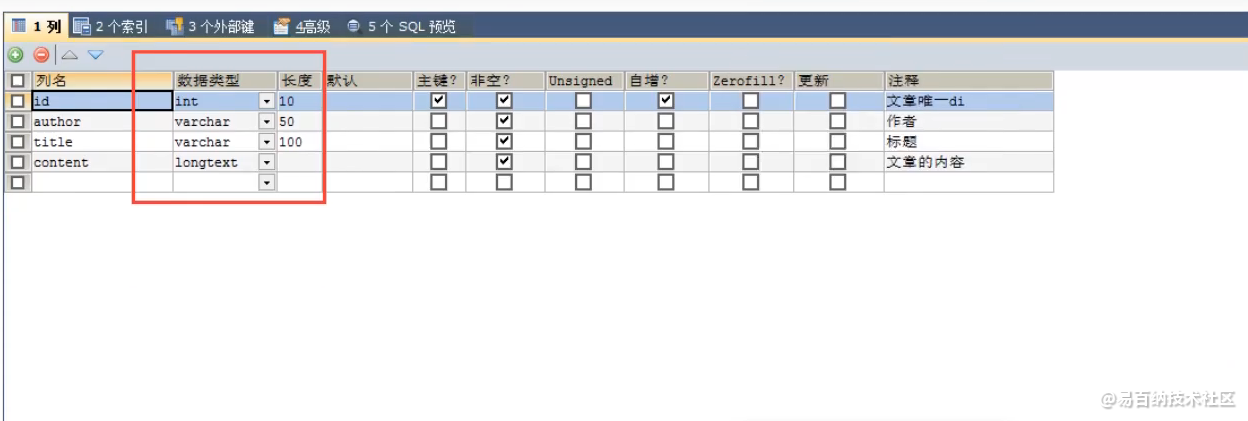
PUT /test1/type1/1
{
"name":"大数据梦想家",
"age":21
} 如下图所示:
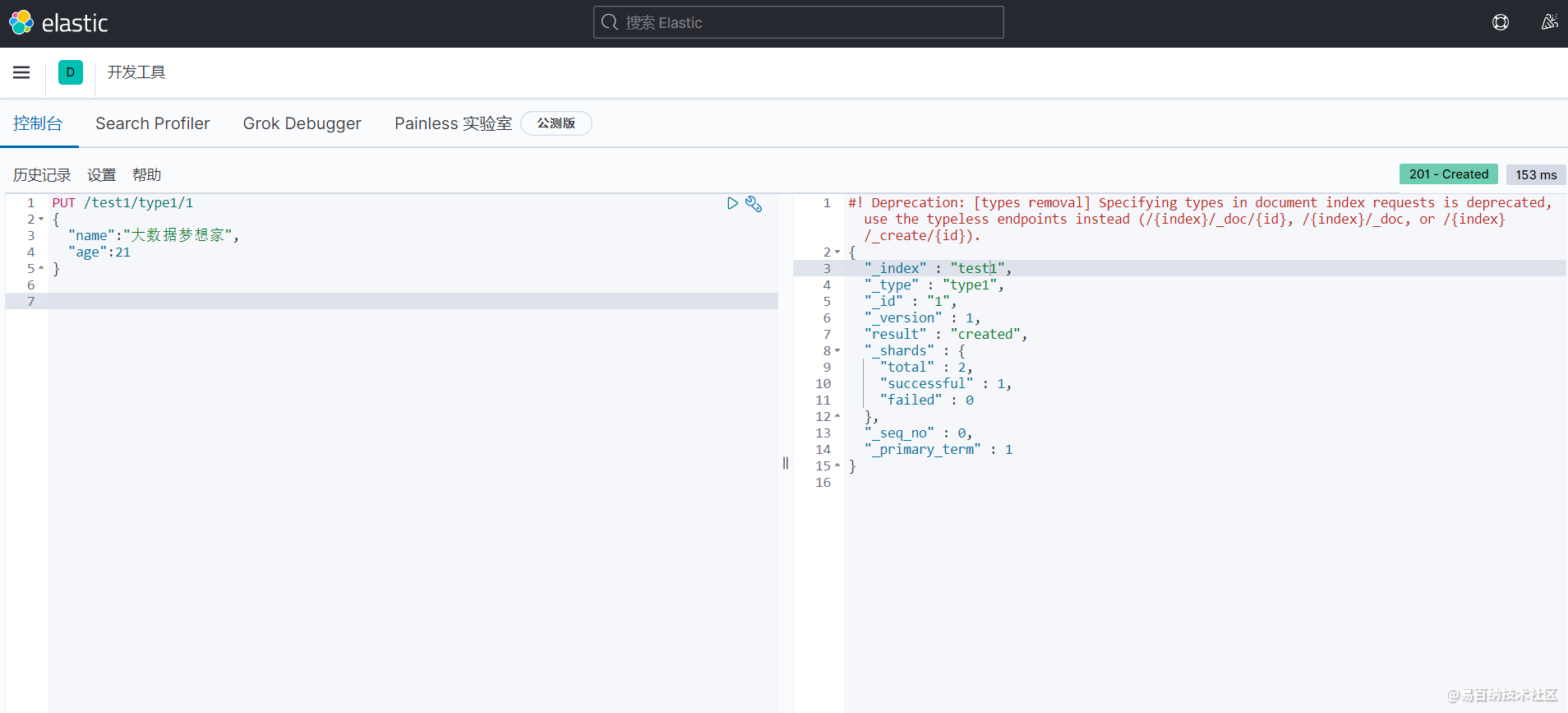 返回结果 (是以REST ful 风格返回的 ):
返回结果 (是以REST ful 风格返回的 ):
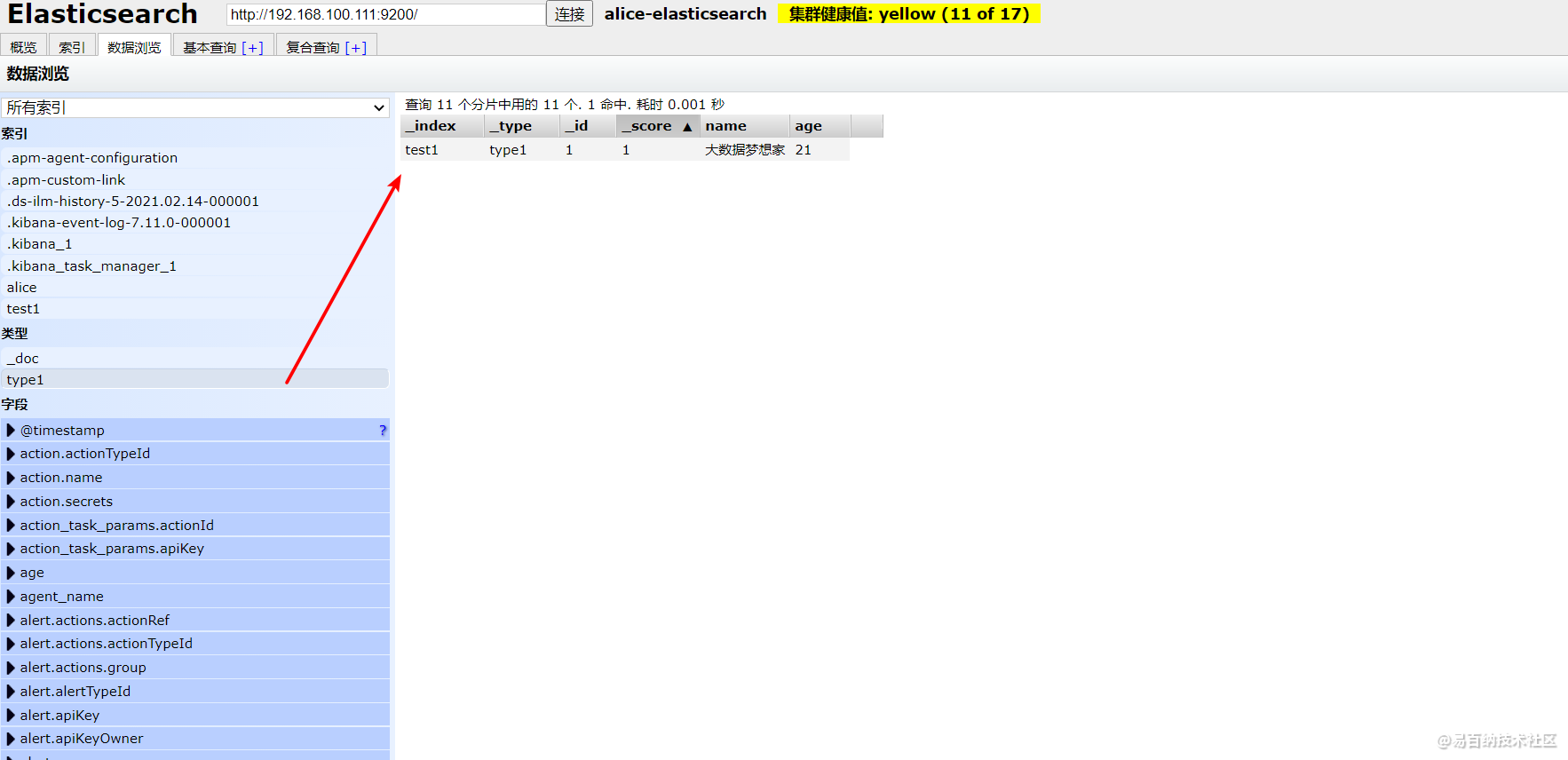
 然后我们在
然后我们在elasticsearch-head中的数据浏览模块,就可以看见我们完成了自动创建索引,数据也成功添加进来了,所以建议初学时,可以将 es 当做是一个数据库来学习。
 那么 name 这个字段用不用指定类型呢。毕竟我们关系型数据库 是需要指定类型的啊
那么 name 这个字段用不用指定类型呢。毕竟我们关系型数据库 是需要指定类型的啊
字段类型
elasticsearch 常见的字段类型如下:
- 字符串类型
- 数值类型
long, integer, short, byte, double, float, half_float, scaled_float
- 日期类型
- 布尔值类型
- 二进制类型
- 等等
PUT新增
现在我们在kibana面板上新建一个索引并指定字段类型
PUT /test2
{
"mappings": {
"properties": {
"name":{
"type":"text"
},
"age":{
"type":"long"
},
"birthday":{
"type":"date"
}
}
}
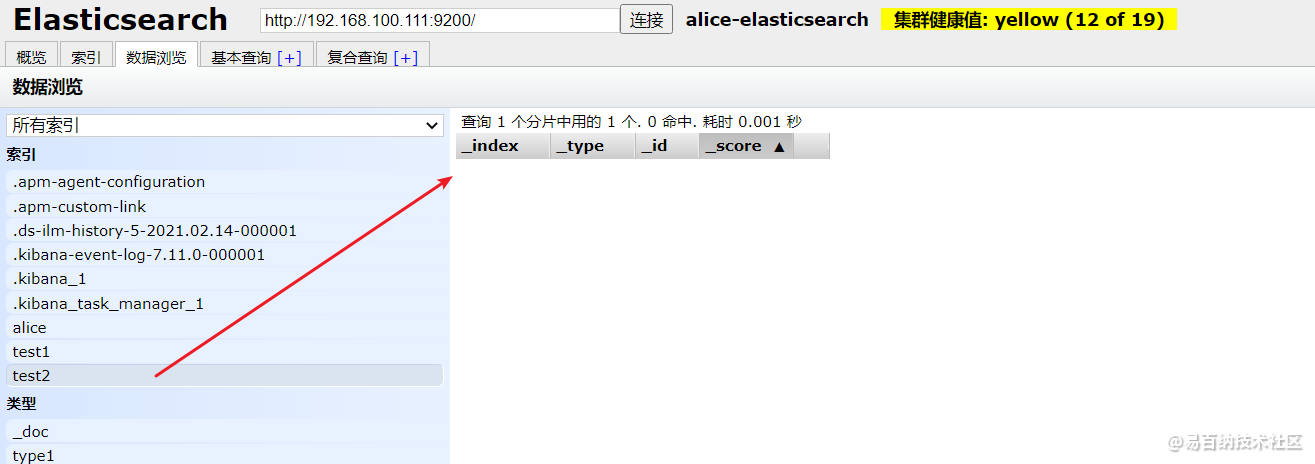
}输出如下,说明创建成功了
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test2"
} 在elasticsearch-head上可以查看到我们目前还未添加任何数据
GET 查看
现在我们来尝试使用一下 GET 命令,请求具体的信息!
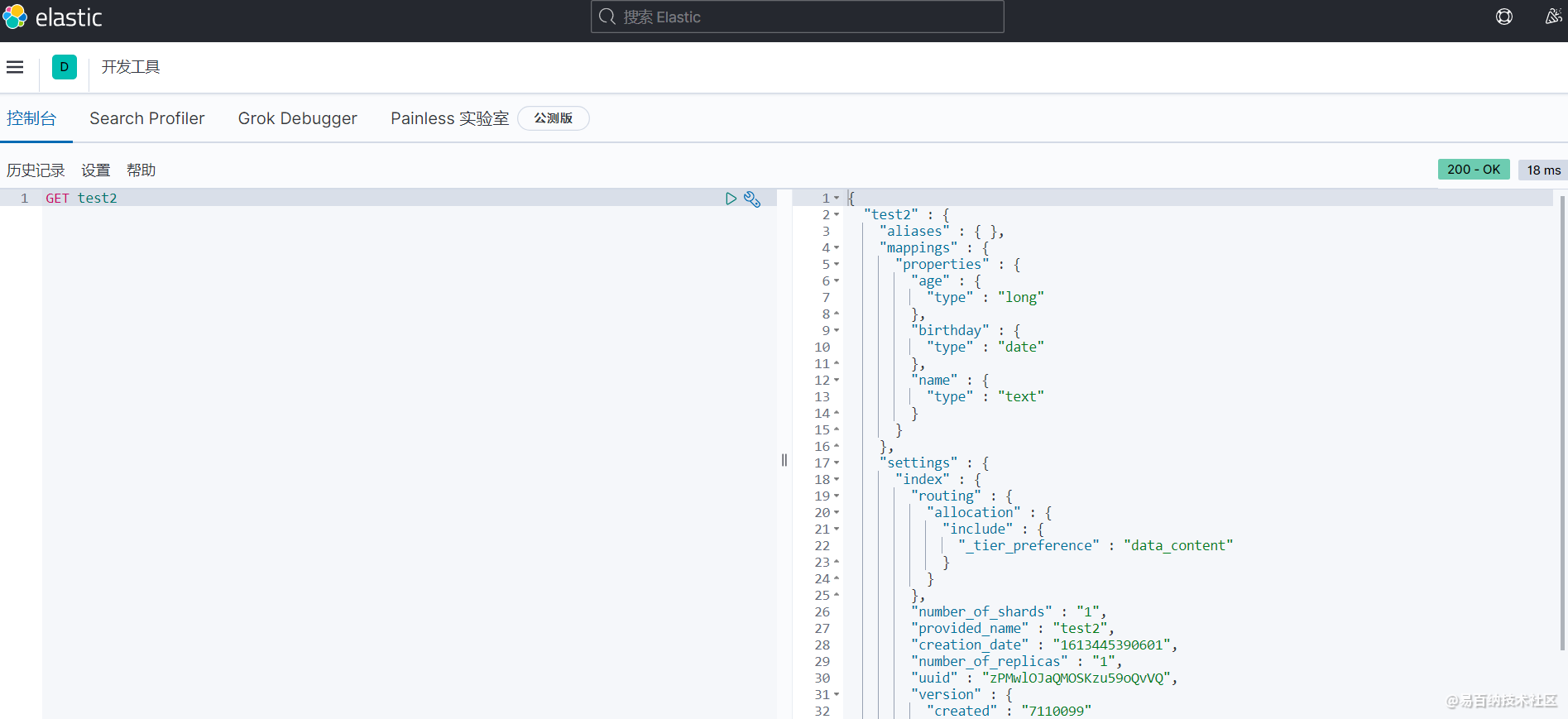 可以发现通过
可以发现通过GET请求,我们能够详细获取到该索引下具体的信息,其中包含字段类型。那上面示例中字段类型是我自己定义的,那么我们不定义类型会是什么情况呢?
我们首先发起一个PUT请求,创建一个新的索引 test3,并添加一条数据
PUT /test3/_doc/1
{
"name":"大数据梦想家",
"age":21,
"birthday":"2000-02-06"
} 然后通过GET请求,可以发现非常的智能。但是如果我们的文档字段类型没有指定,那么es就会给我们默认配置的字段类型!

UPDATE修改
那如果我们想要修改文档里的字段信息呢?我们可以选择 UPDATE 也可以 选择 PUT进行覆盖
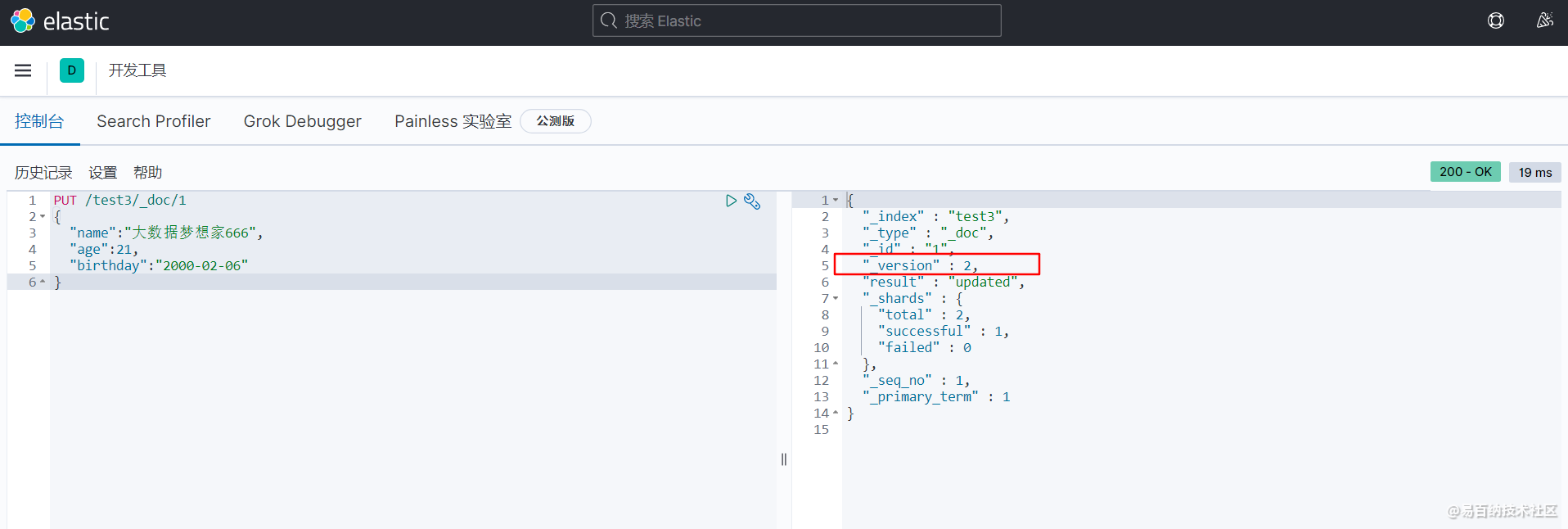
例如我可以像下图中的例子,将之前test3索引中的1号文档中的 name 字段修改后,重复提交,发现更新成功,但是注意 version 版本号已经变成了2
 但是注意这种方法有弊端,如果我们在
但是注意这种方法有弊端,如果我们在PUT的过程中,遗漏了字段,那么数据就会被新数据覆盖!所以,修改数据不建议使用PUT覆盖的方式!
我们使用 POST 命令,在 id 后面跟 _update ,要修改的内容放到 doc 文档(属性)中即可。
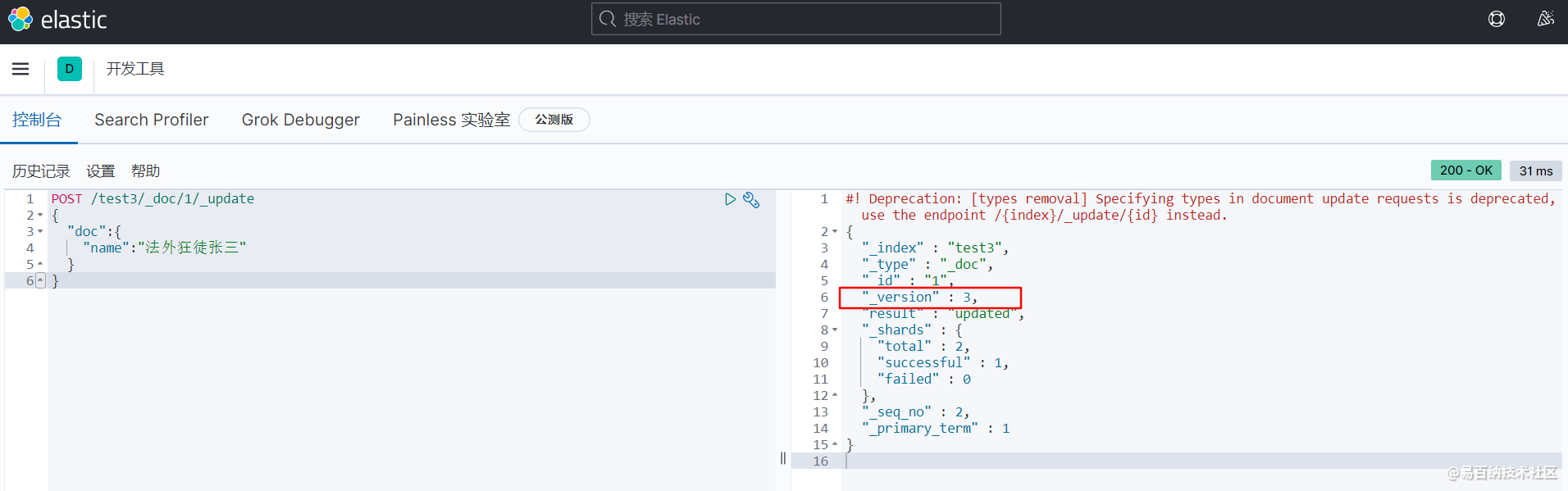 可以发现此时更新之后的
可以发现此时更新之后的version变成了3。所以,一旦索引被创建了之后,所有的修改都可以通过版本号看到变化。
DELETE删除
那么怎么删除一条索引呢(库)呢?我们需要使用到DELETE命令
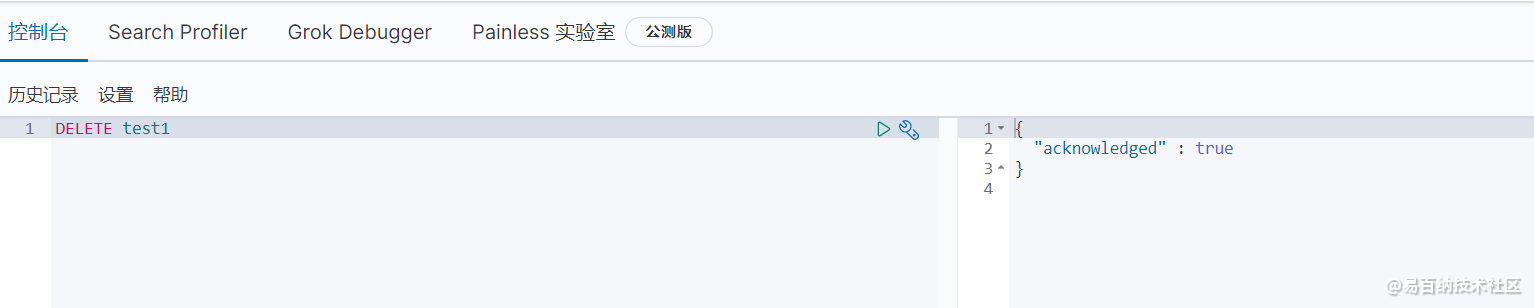 执行完成之后,到
执行完成之后,到elasticsearch-head中查看索引,可以发现已经被删除了
 结论: 通过 DELETE 命令实现删除,根据请求判断是删除索引还是删除文档记录!因此,使用 RESTFUL 风格是我们学习ES值得推荐使用的
结论: 通过 DELETE 命令实现删除,根据请求判断是删除索引还是删除文档记录!因此,使用 RESTFUL 风格是我们学习ES值得推荐使用的
其他命令
我们可以通过GET _cat/health来获取集群的一个健康状态
 同时观察
同时观察elasticsearch-head,可以得出该界面实际上是在不断的像 elasticsearch 发起 GET 请求,然后将结果可视化展示在页面上!
 除了看集群的健康信息,我们还可以看什么呢?
除了看集群的健康信息,我们还可以看什么呢?
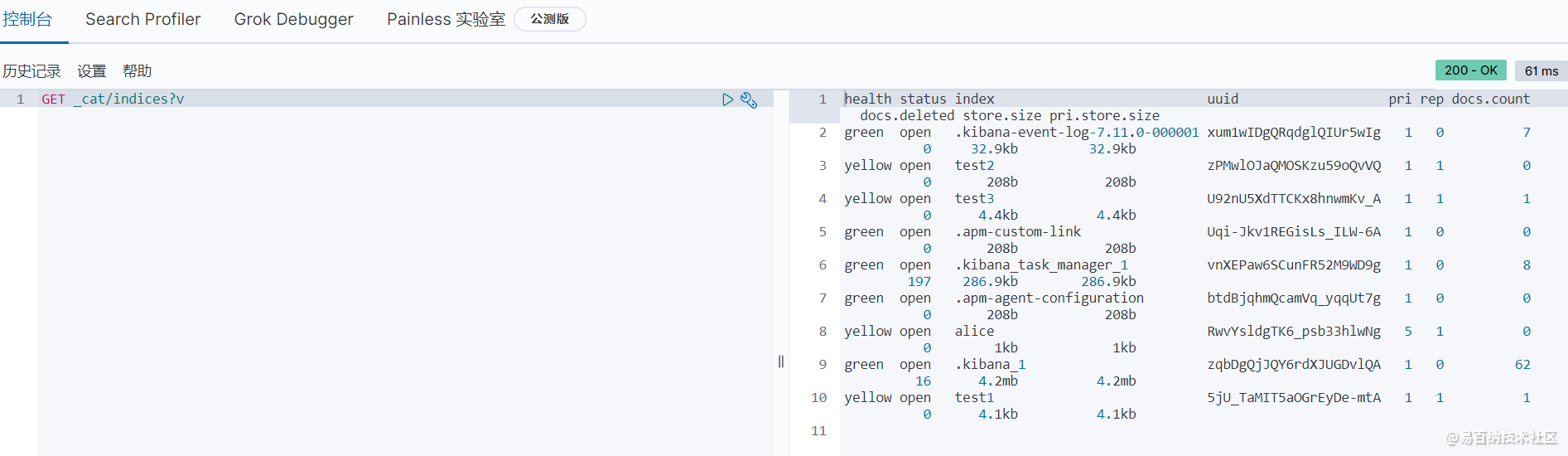
通过命令GET _cat/indices?v,我们可以获取到当前索引的很多信息,返回值包括所有索引的状态健康情况,分片,数据储存大小等等
关于文档的基本操作
接下来我们学习关于文档的基本操作,首先先重新创建一个新的索引,并添加一些数据
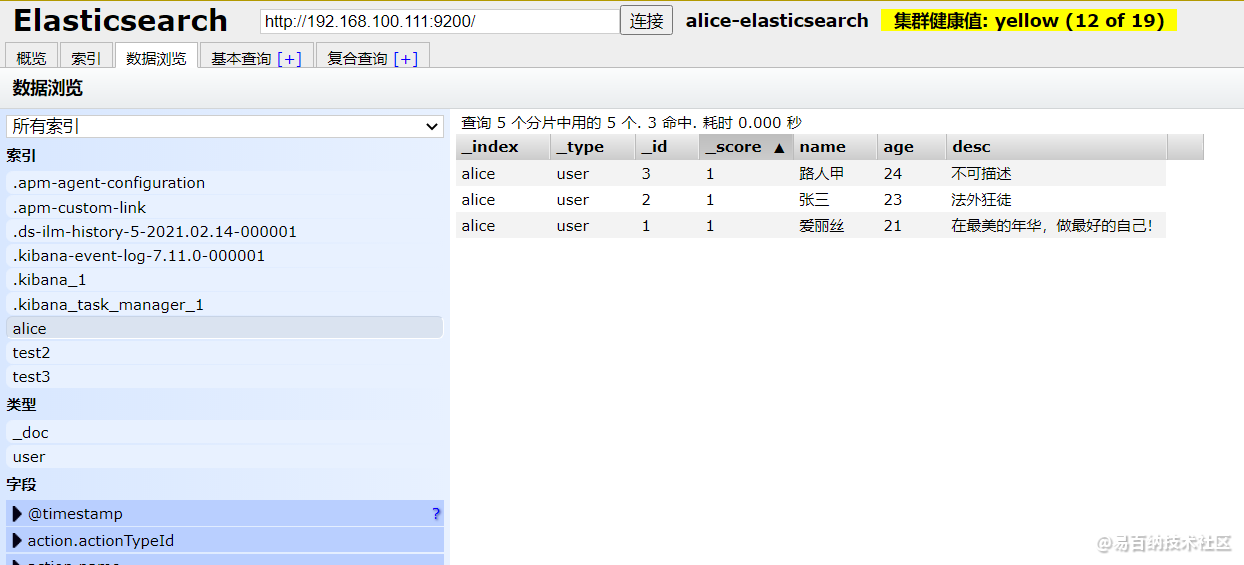
PUT /alice/user/1
{
"name":"爱丽丝",
"age":21,
"desc":"在最美的年华,做最好的自己!",
"tags":["技术宅","温暖","思维活跃"]
}
PUT /alice/user/2
{
"name":"张三",
"age":23,
"desc":"法外狂徒",
"tags":["渣男","交友"]
}
PUT /alice/user/3
{
"name":"路人甲",
"age":24,
"desc":"不可描述",
"tags":["靓仔","网游"]
} 打开elasticsearch-head界面,确保我们的数据成功添加到了 es
 接下来就可以进行文档的基本操作了!
接下来就可以进行文档的基本操作了!
简单查询
通过 GET 命令,我们可以搜索到指定 id 的文档信息
GET alice/user/1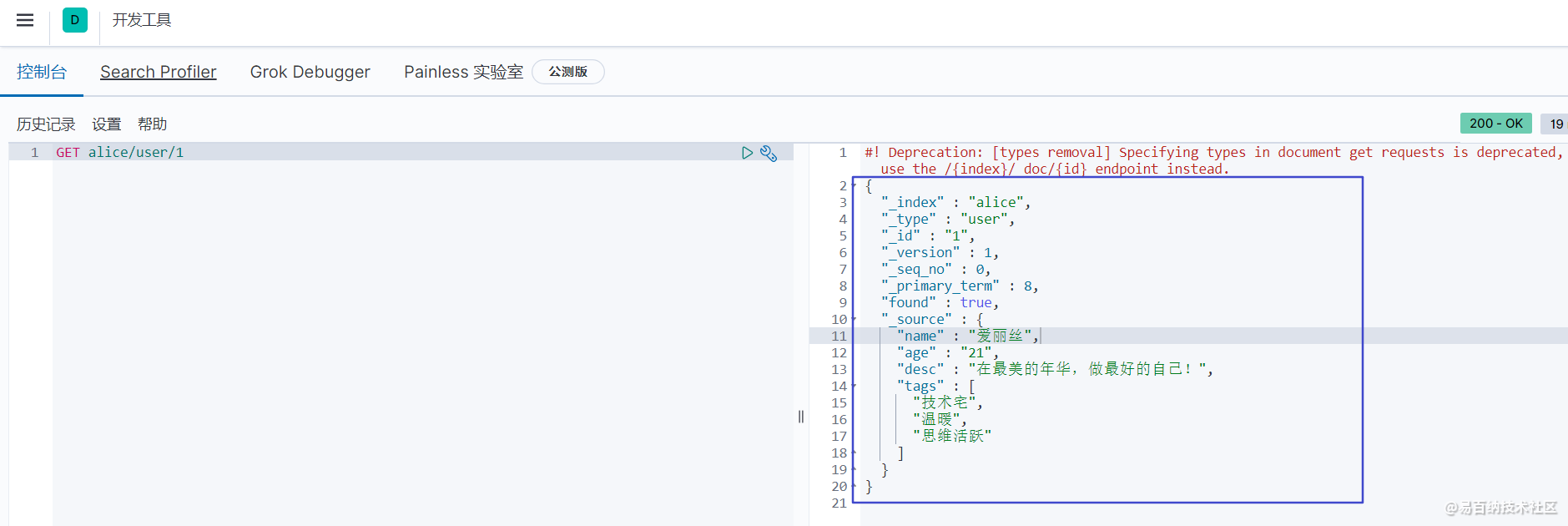 当然这是简单的搜索,下面我们来看一下 es 如何做条件查询
当然这是简单的搜索,下面我们来看一下 es 如何做条件查询
条件查询_search?q=我们可以通过如下命令,来进行条件查询
GET alice/user/_search?q=name:张三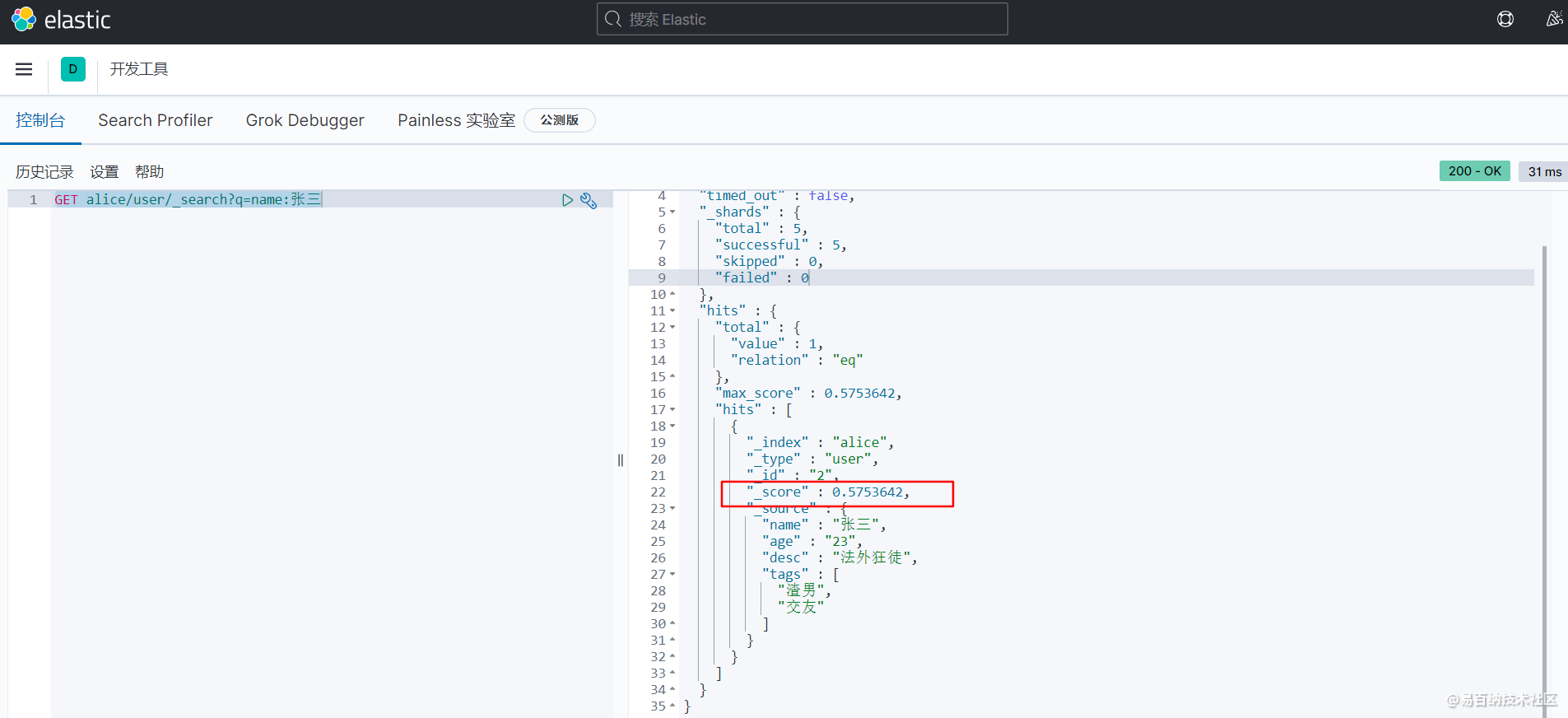
我们看一下结果 返回并不是 数据本身,是给我们了一个 hits ,还有 _score得分,就是根据算法算出和查询条件匹配度高的分就越高。
我们在以某度为例的搜索引擎上进行搜索也是一样的道理,权重越高网站的位置就越靠前!
但我们一般使用不会直接加条件去查询,更多的会用到下面要介绍到的复杂操作搜索。
复杂操作搜索 select( 排序,分页,高亮,模糊查询,精准查询!)
为了方便测试,我又执行下面的命令,往Alice索引下添加了2个文档
PUT /alice/user/4
{
"name":"爱丽丝学Java",
"age":25,
"desc":"技术成就自我!",
"tags":["思维敏捷","喜欢学习"]
}
PUT /alice/user/5
{
"name":"爱丽丝学Python",
"age":26,
"desc":"人生苦短,我用Python!",
"tags":["好学","勤奋刻苦"]
} 刷新,查看到现在已经有了5条数据:
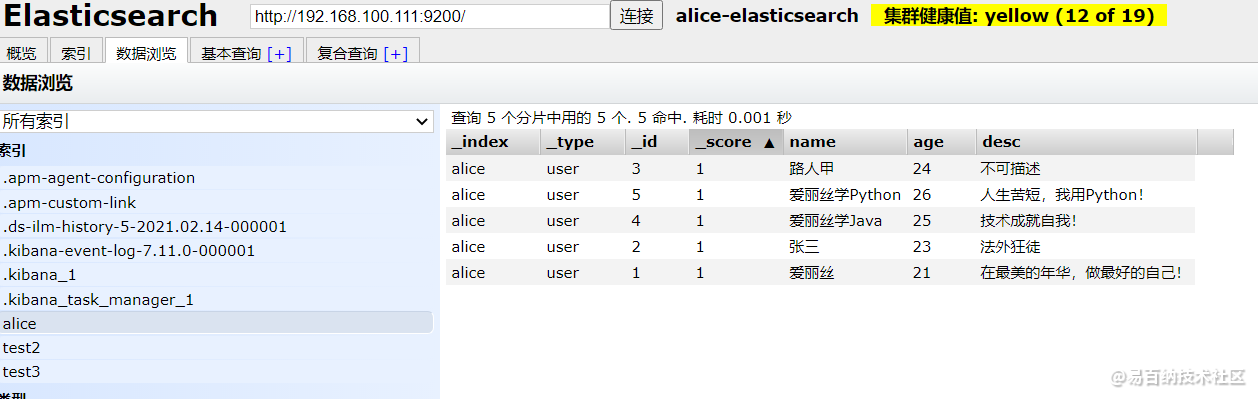 现在我们来构建一个查询:
现在我们来构建一个查询:
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
}
}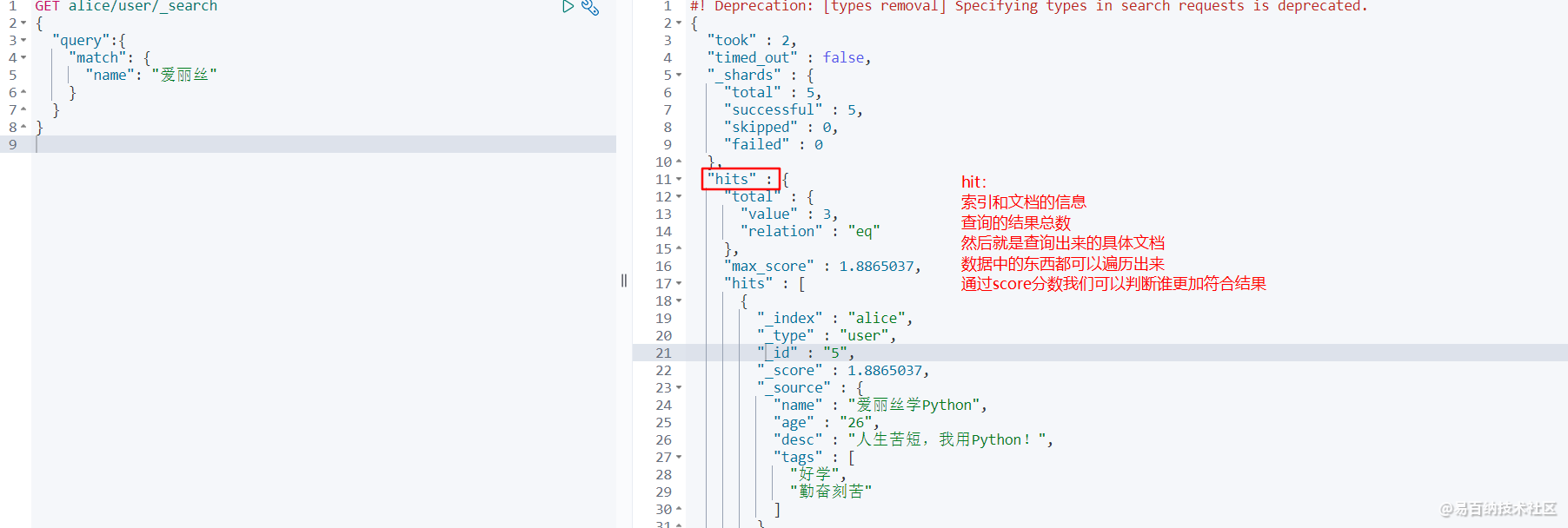 默认的话,es会查询出文档的所有字段,如果我们只想要部分的字段,就可以像下面所展示的demo进行查询:
默认的话,es会查询出文档的所有字段,如果我们只想要部分的字段,就可以像下面所展示的demo进行查询:
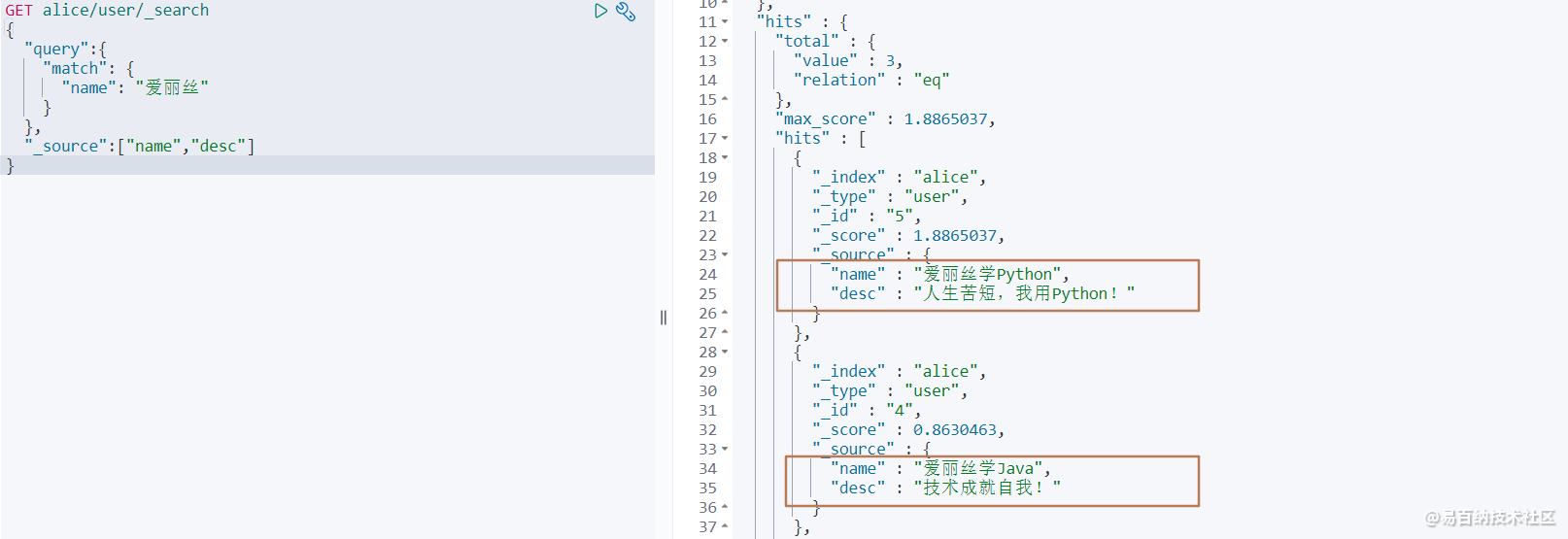
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
},
"_source":["name","desc"]
} 如上例所示,在查询中,通过 _source 来控制仅返回 name 和 desc 属性。页面返回的查询结果如下:
 一般的,我们推荐使用构建查询,以后在与程序交互时的查询等也是使用构建查询方式处理查询条件,因为该方式可以构建更加复杂的查询条件,也更加一目了然。
一般的,我们推荐使用构建查询,以后在与程序交互时的查询等也是使用构建查询方式处理查询条件,因为该方式可以构建更加复杂的查询条件,也更加一目了然。
排序查询
我们说到排序,有人就会想到:正序或倒序。那么我们先来根据age字段倒序查询:
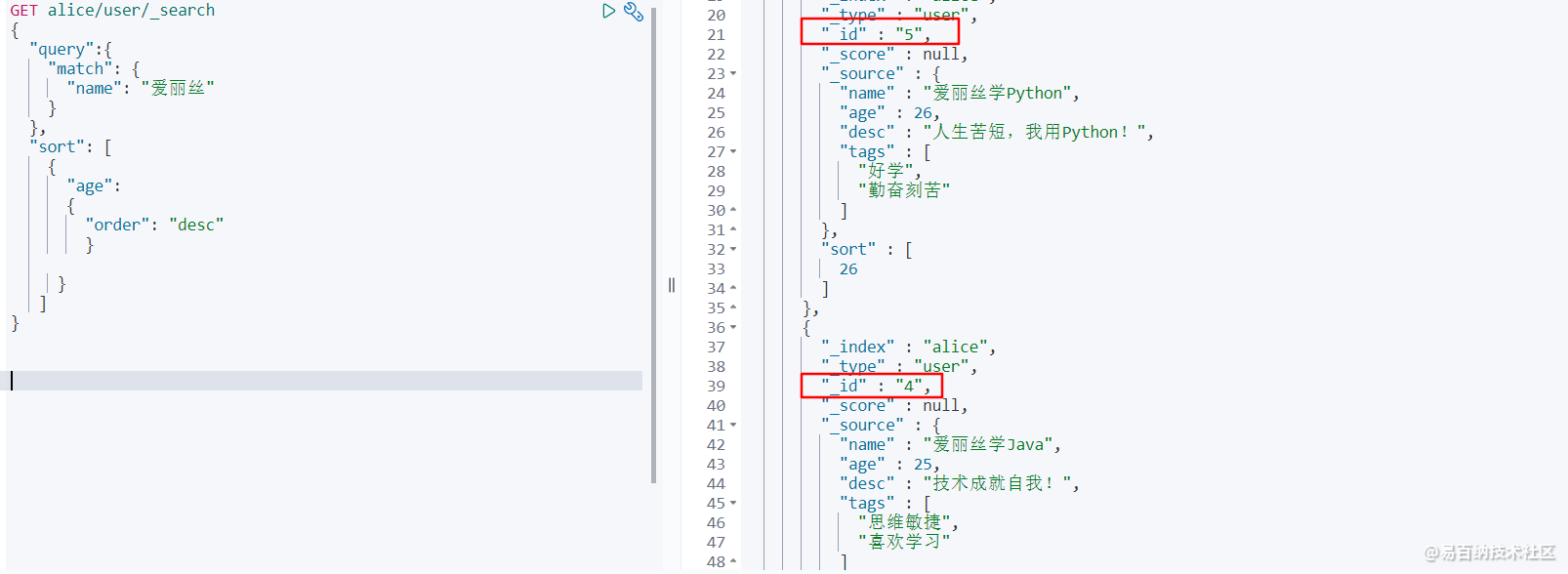
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
},
"sort": [
{
"age":
{
"order": "desc"
}
}
]
} 查询返回的结果如下:
 同理,如果我们想要正序查询,只需要将
同理,如果我们想要正序查询,只需要将desc换成了asc即可。
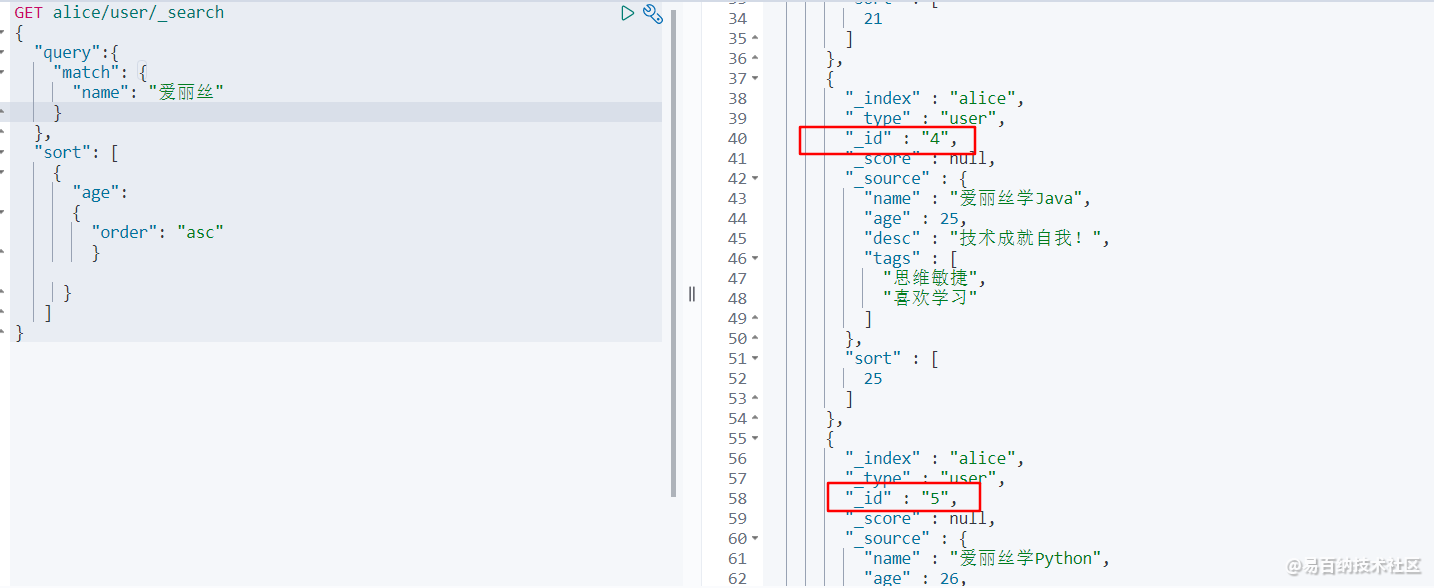
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
},
"sort": [
{
"age":
{
"order": "asc"
}
}
],
"from":0,
"size":1
} 查询结果如下:
注意:在排序的过程中,只能使用可排序的属性进行排序。那么可以排序的属性有哪些呢?
- 数字
- 日期
- ID
其他都不行!
分页查询
学到这里,我们也可以看到,我们的查询条件越来越多,开始仅是简单查询,慢慢增加条件查询,增加排序,对返回结果进行限制。所以,我们可以说,对 于 elasticsearch 来说,所有的查询条件都是可插拔的。比如说,我们在查询中,仅对返回结果进行限制:
GET alice/user/_search
{
"query":
{"match_all": {}
},
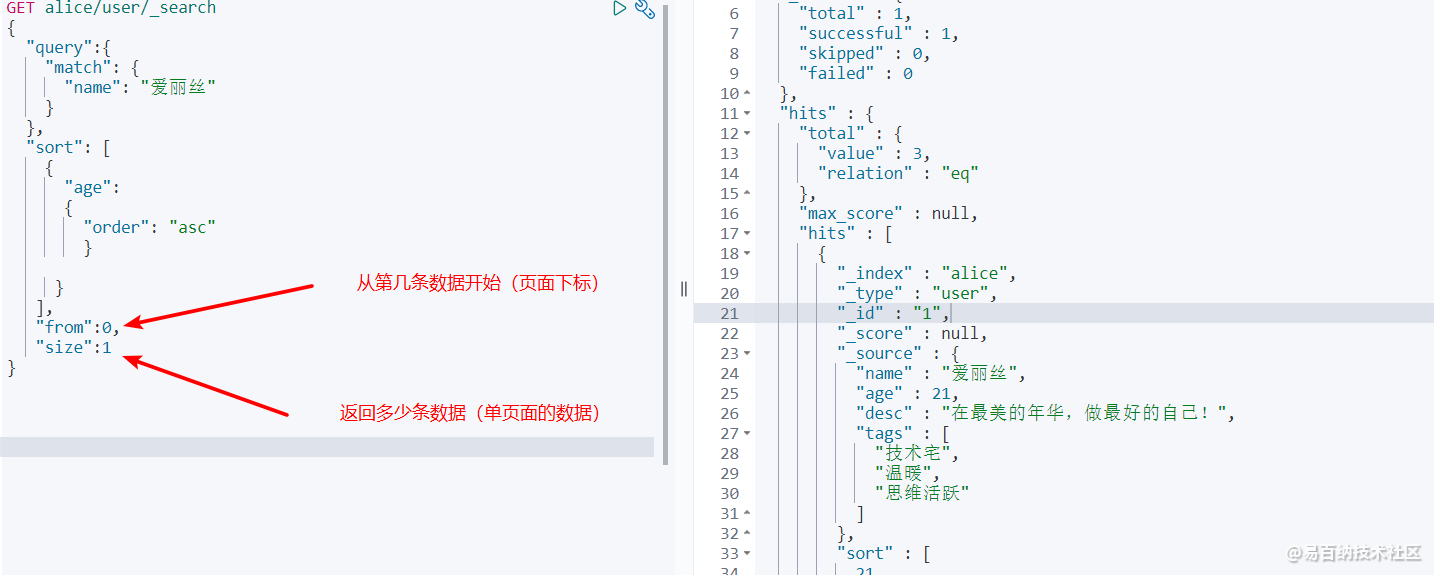
"from":0, # 从第n条开始
"size":4 # 返回n条数据
} 分页查询类似于我们SQL中的 limit 语句。在 es 中我们想要实现这样的效果只需要用 from 指定 从第几条数据开始,size指定返回多少条数据即可。
布尔查询
must (and)
我们上面已经讲过了通过构建查询的方法去做模糊查询,那我们如果想多条件查询,例如查询name为alice,并且age是25岁,那该如何查询呢?
我们通过在 bool属性内使用 must 来作为查询条件!看结果,是不是 有点像and的感觉,里面的条件需要都满足!
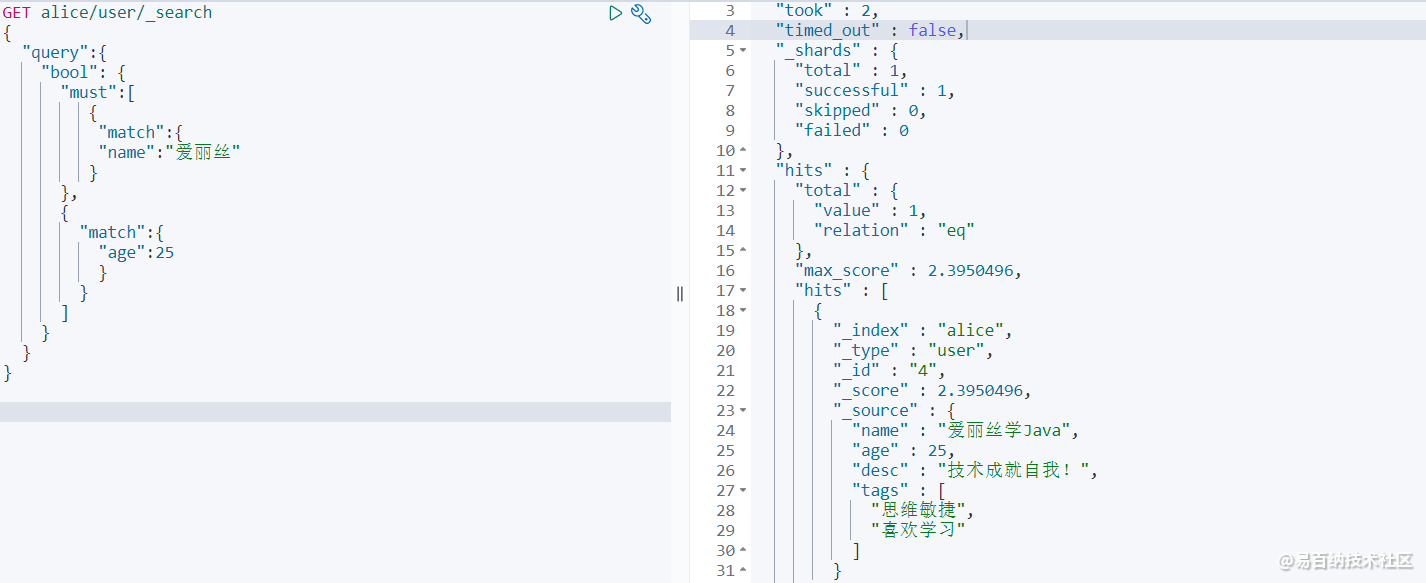
GET alice/user/_search
{
"query":{
"bool": {
"must":[
{
"match":{
"name":"爱丽丝"
}
},
{
"match":{
"age":25
}
}
]
}
}
} 查询结果如下
 should (or)
should (or)
那么我要查询name为爱丽丝或 age 为 25 的呢?
我们只需要将boolean属性内的must值换成should 即可,这就有点相当于 or 的感觉
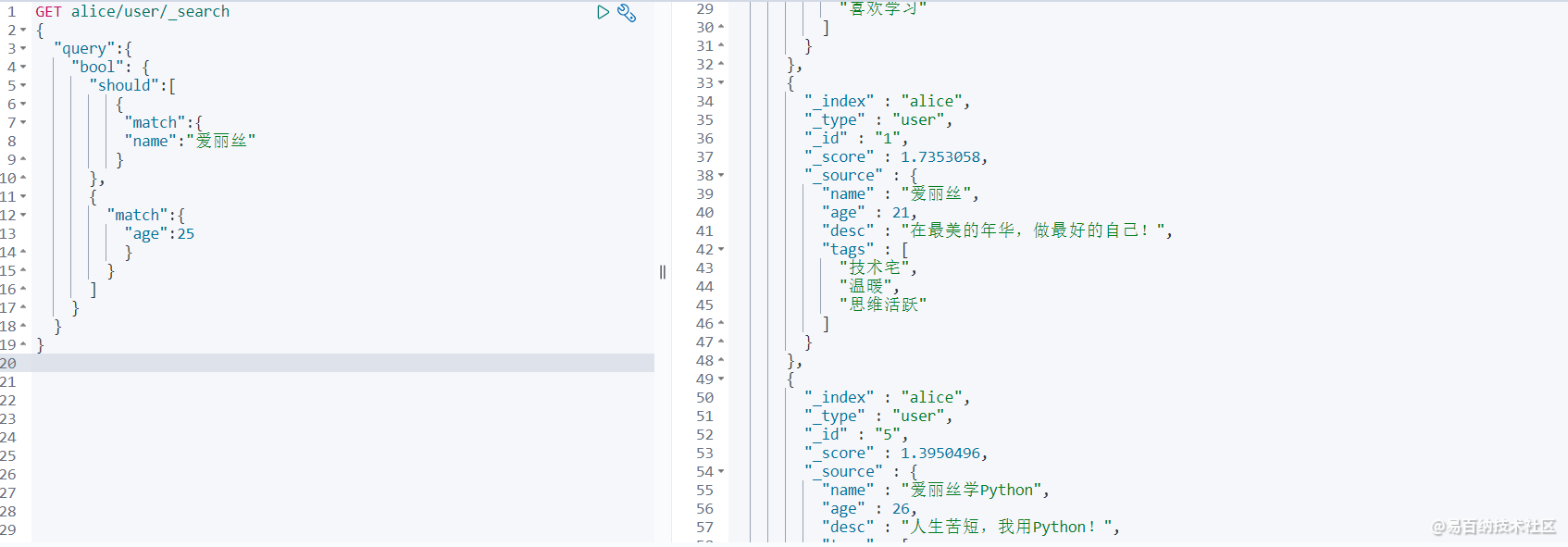
GET alice/user/_search
{
"query":{
"bool": {
"should":[
{
"match":{
"name":"爱丽丝"
}
},
{
"match":{
"age":25
}
}
]
}
}
}查询结果如下
 must_not (not)
must_not (not)
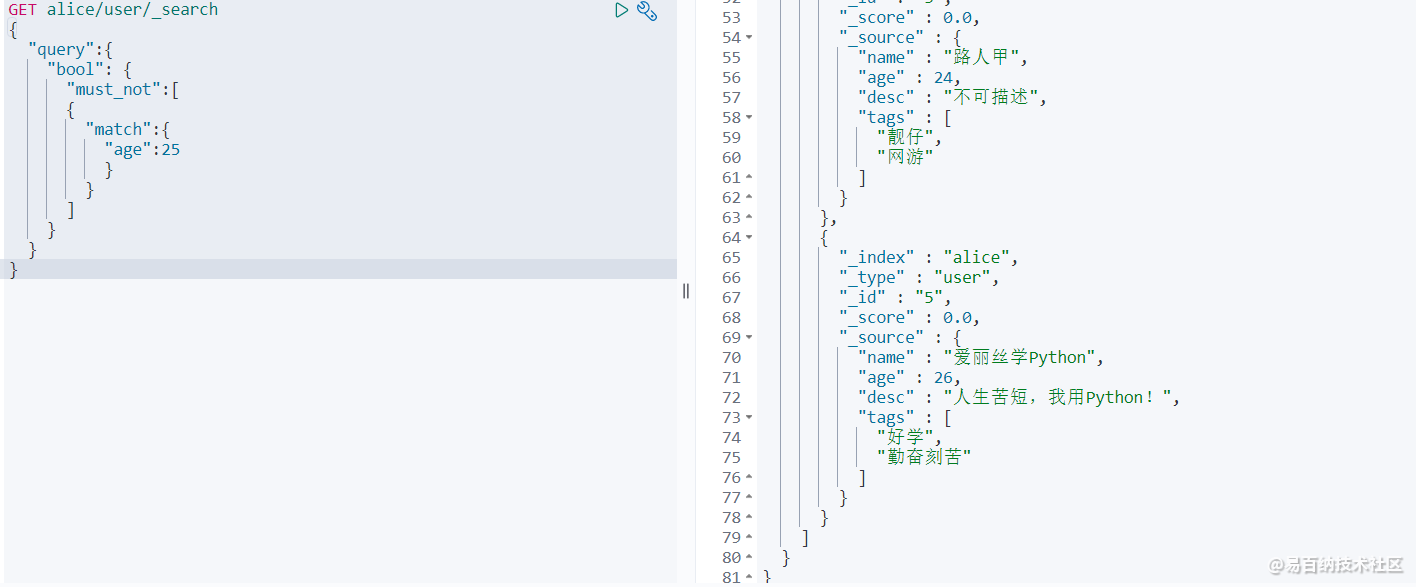
那现在我想要查询年龄不是 25 的 数据,只需要将boolean的属性值换成must_not即可
GET alice/user/_search
{
"query":{
"bool": {
"must_not":[
{
"match":{
"age":25
}
}
]
}
}
} 查询结果如下:
 Fitter
Fitter
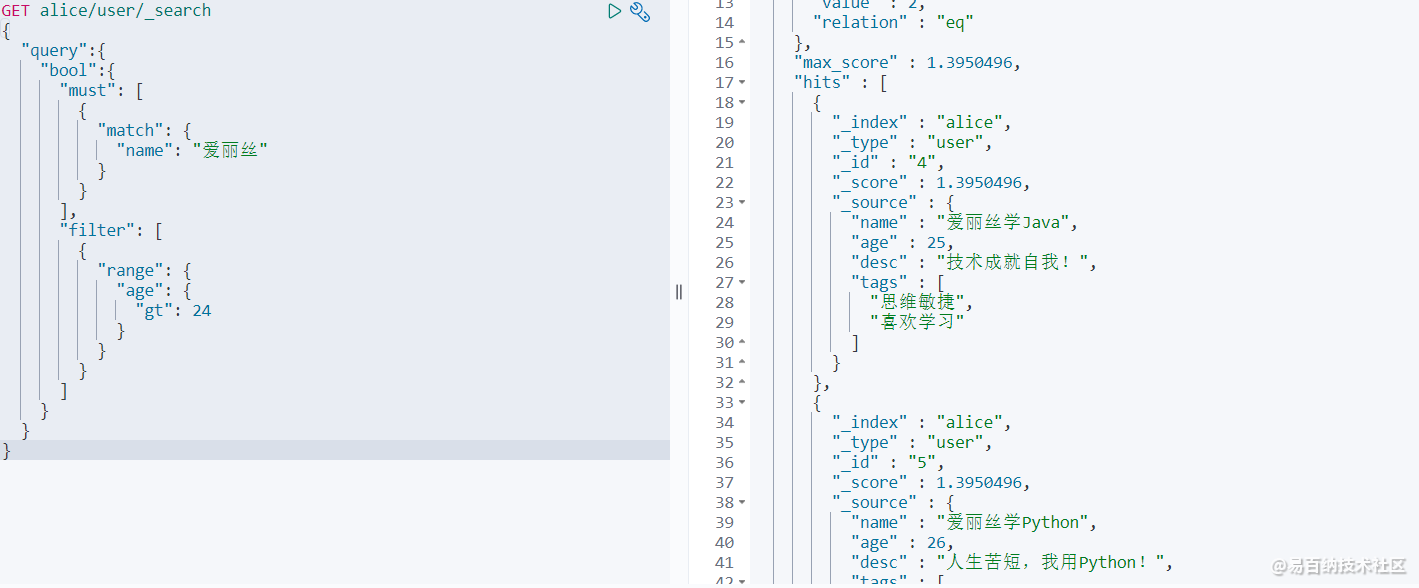
那如果查询 name 为爱丽丝,age 大于 24 的数据,需要使用到filter进行过滤。
GET alice/user/_search
{
"query":{
"bool":{
"must": [
{
"match": {
"name": "爱丽丝"
}
}
],
"filter": [
{
"range": {
"age": {
"gt": 24
}
}
}
]
}
}
} 查询结果如下,可以发现只有age为25 和 26的两条数据
 这里就用到了 filter 条件过滤查询,过滤条件的范围用 range 表示,其余操作如下 :
这里就用到了 filter 条件过滤查询,过滤条件的范围用 range 表示,其余操作如下 :
- gt 表示大于
- gte 表示大于等于
- lt 表示小于
- lte 表示小于等于
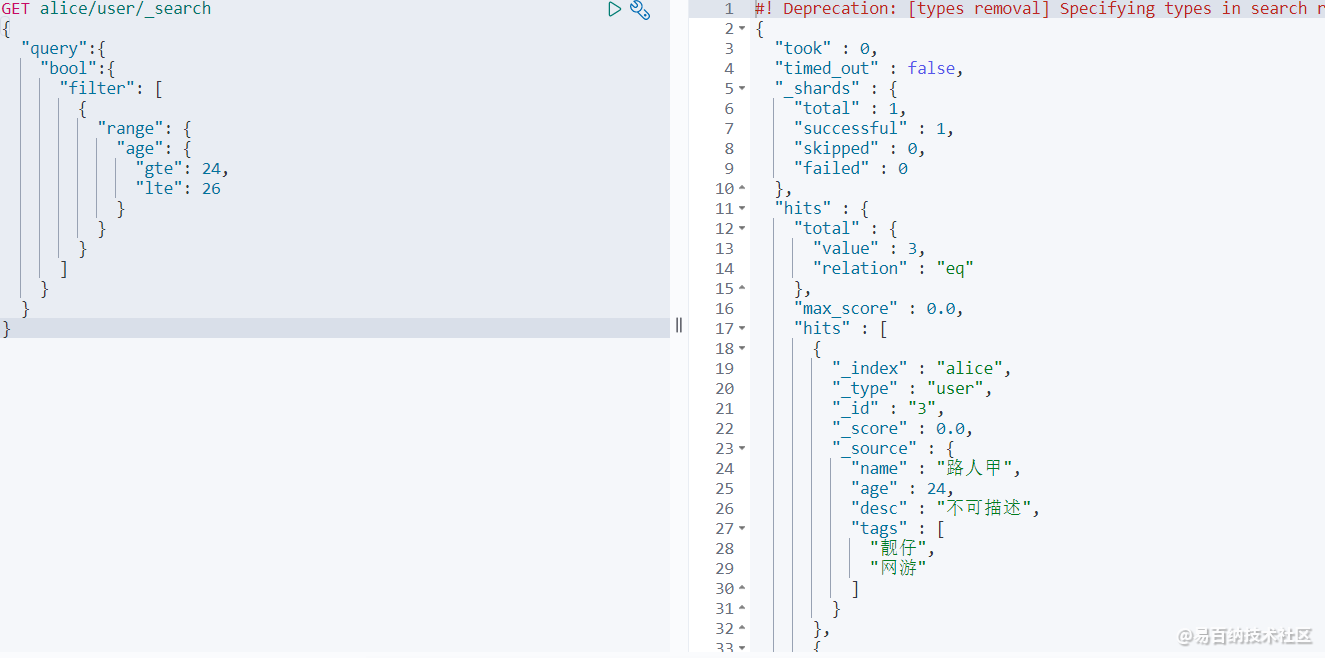
那现在要查询,例如 age 在24到26之间的数据该如何查询?
GET alice/user/_search
{
"query":{
"bool":{
"filter": [
{
"range": {
"age": {
"gte": 24,
"lte": 26
}
}
}
]
}
}
} 查询结果:
短语检索
为了方便测试,我们再加入几条文档数据:
PUT /alice/user/6
{
"name":"大数据老K",
"age":25,
"desc":"技术成就自我!",
"tags":["男","学习","技术"]
}
PUT /alice/user/7
{
"name":"Python女侠",
"age":26,
"desc":"人生苦短,我用Python!",
"tags":["靓女","勤奋学习","善于交际"]
} 例如现在需要查询tags中包含“男”的数据
GET alice/user/_search
{
"query":{
"match":{
"tags":"男"
}
}
}查询结果如下:
 匹配多个标签
匹配多个标签
既然按照标签检索,那么,能不能写多个标签呢?
GET alice/user/_search
{
"query":{
"match":{
"tags":"男 学习"
}
}
}此时我们可以观察返回的结果,可以发现只要满足一个标签就能返回这个数据了

精确查询
term查询是直接通过倒排索引指定的词条进程精确查找的!
关于分词:
- term ,不经过分词,直接查询精确的值
- match,会使用分词器解析!(先分析文档,然后再通过分析的文档进行查询!)
说到分词器解析,就不得不提到两种数据类型:text和keyword。下面我们就来做个测试:
// 创建一个索引,并指定类型
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type":"keyword"
}
}
}
}
// 插入数据
PUT testdb/_doc/1
{
"name":"爱丽丝学大数据name",
"desc":"爱丽丝学大数据desc"
}
PUT testdb/_doc/2
{
"name":"爱丽丝学大数据name2",
"desc":"爱丽丝学大数据desc2"
} 上述中testdb索引中,字段name在被查询时会被分析器进行分析后匹配查询。而属于keyword类型不会被分析器处理。
我们来验证一下:
GET _analyze
{
"analyzer": "keyword",
"text": "爱丽丝学大数据 name"
} 查询结果:
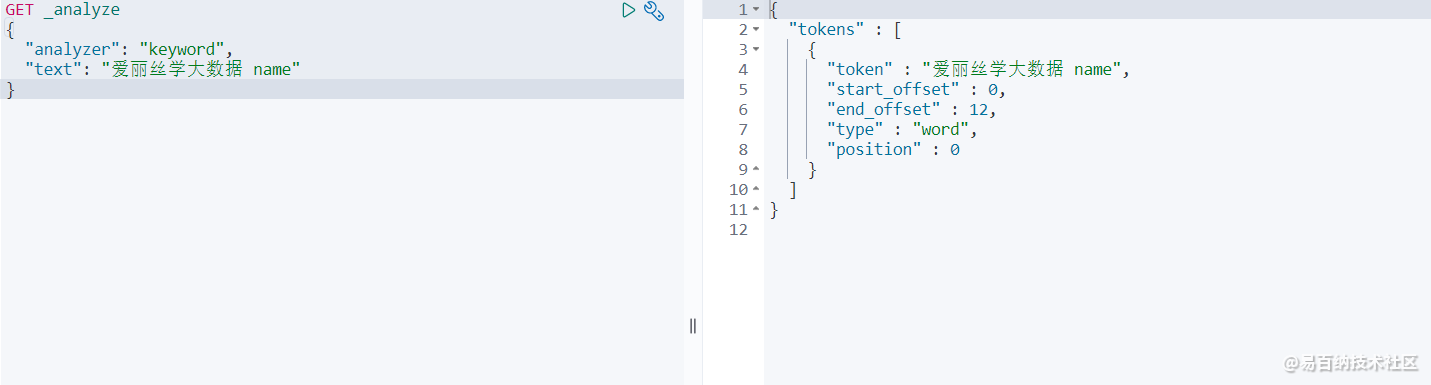 是不是没有被分析~就是简单的一个字符串啊。再测试一下:
是不是没有被分析~就是简单的一个字符串啊。再测试一下:
GET _analyze
{
"analyzer": "standard",
"text": "爱丽丝学大数据 name"
} 查询结果:
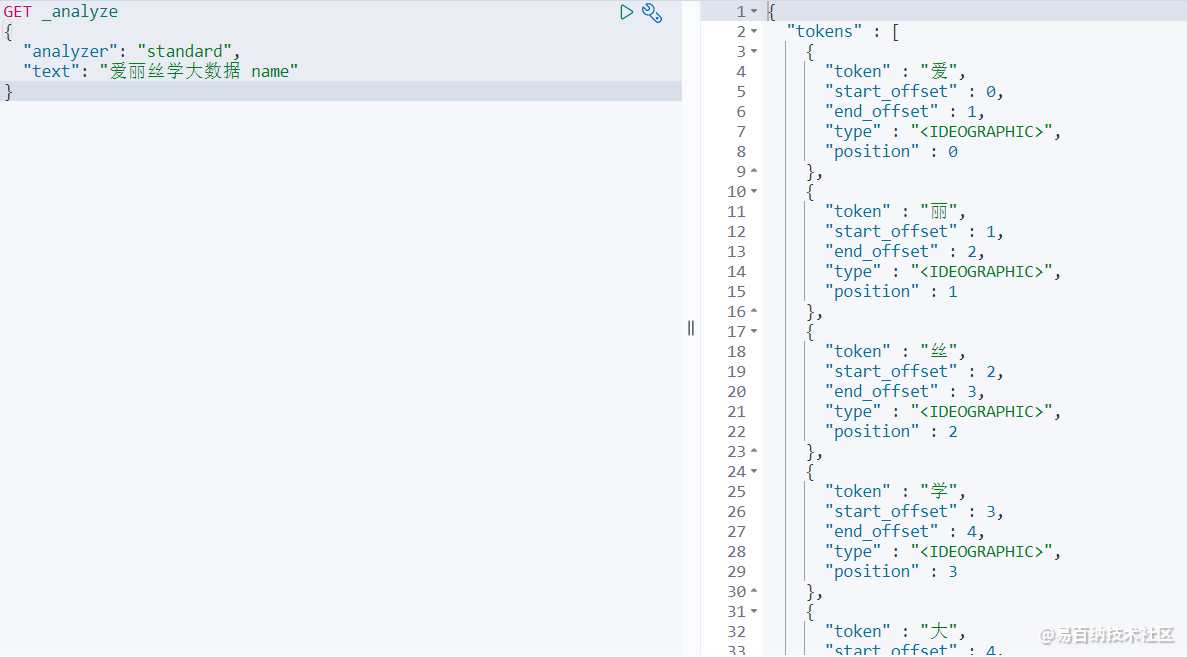 然后我们可以得出结论:keyword 字段类型不会被分析器分析!
然后我们可以得出结论:keyword 字段类型不会被分析器分析!
下面我们用前面添加的2条数据做过测试:
先精准查询text类型的字段
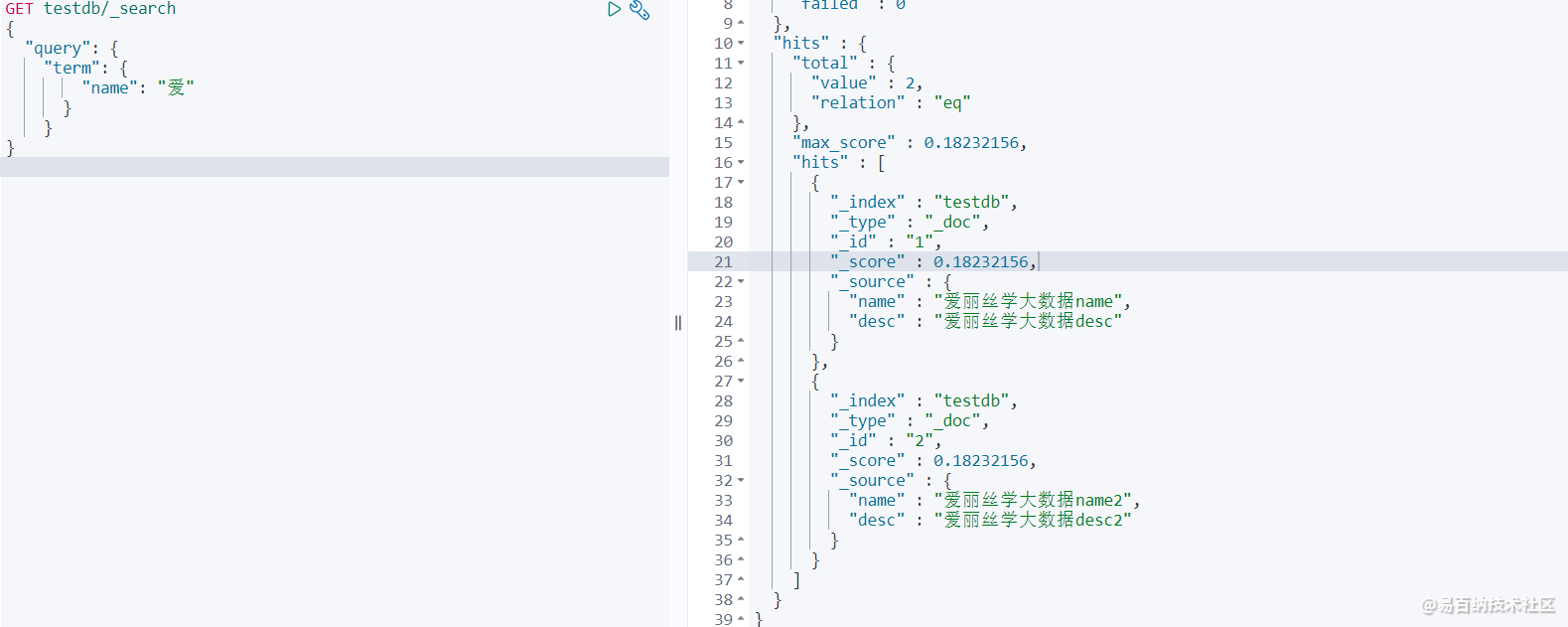
GET testdb/_search // text 会被分析器分析 查询
{
"query": {
"term": {
"name": "爱"
}
}
} 查询结果,2条数据都能匹配到
 然后用
然后用standard类型做精准测试
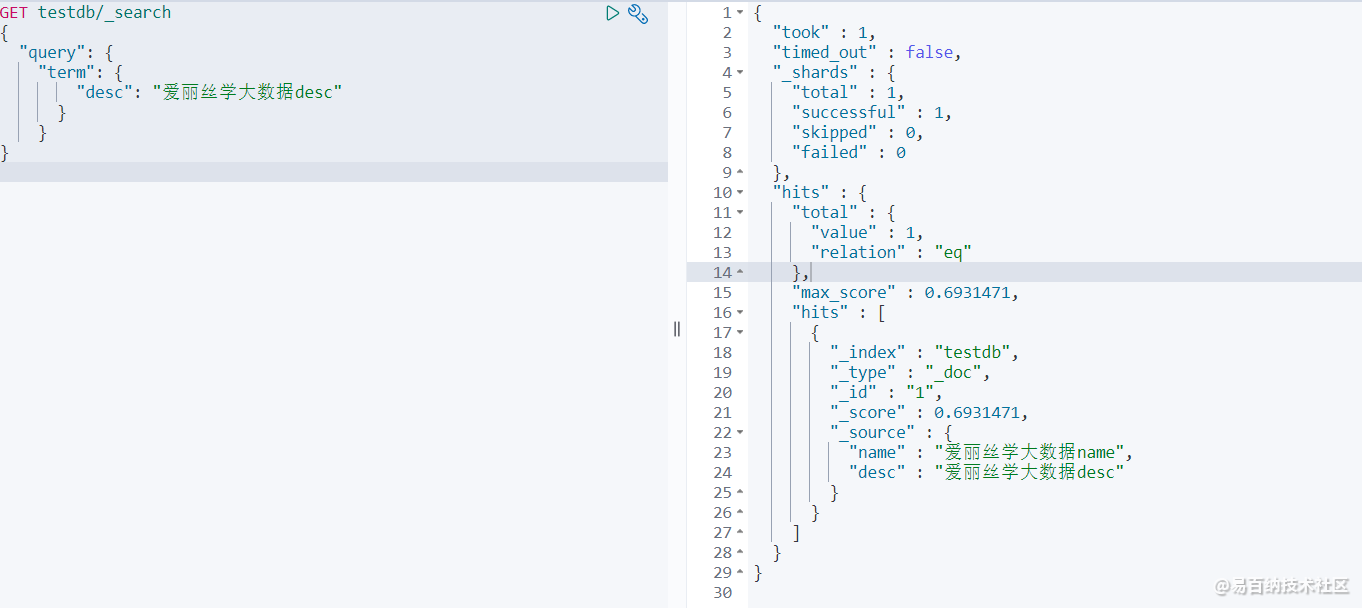
GET testdb/_search // keyword 不会被分析所以直接查询
{
"query": {
"term": {
"desc": "爱丽丝学大数据desc"
}
}
}
查询结果,只有1条数据能匹配到
查找多个精确值
为了方便测试,我们再添加如下数据:
PUT testdb/_doc/3
{
"t1":"22",
"t2":"2021-03-01"
}
PUT testdb/_doc/4
{
"t1":"33",
"t2":"2021-03-01"
}然后进行查询
GET testdb/_search
{
"query": {
"bool":{
"should": [
{
"term": {
"t1":"22"
}
},
{
"term": {
"t1":"33"
}
}
]
}
}
} 查询结果:
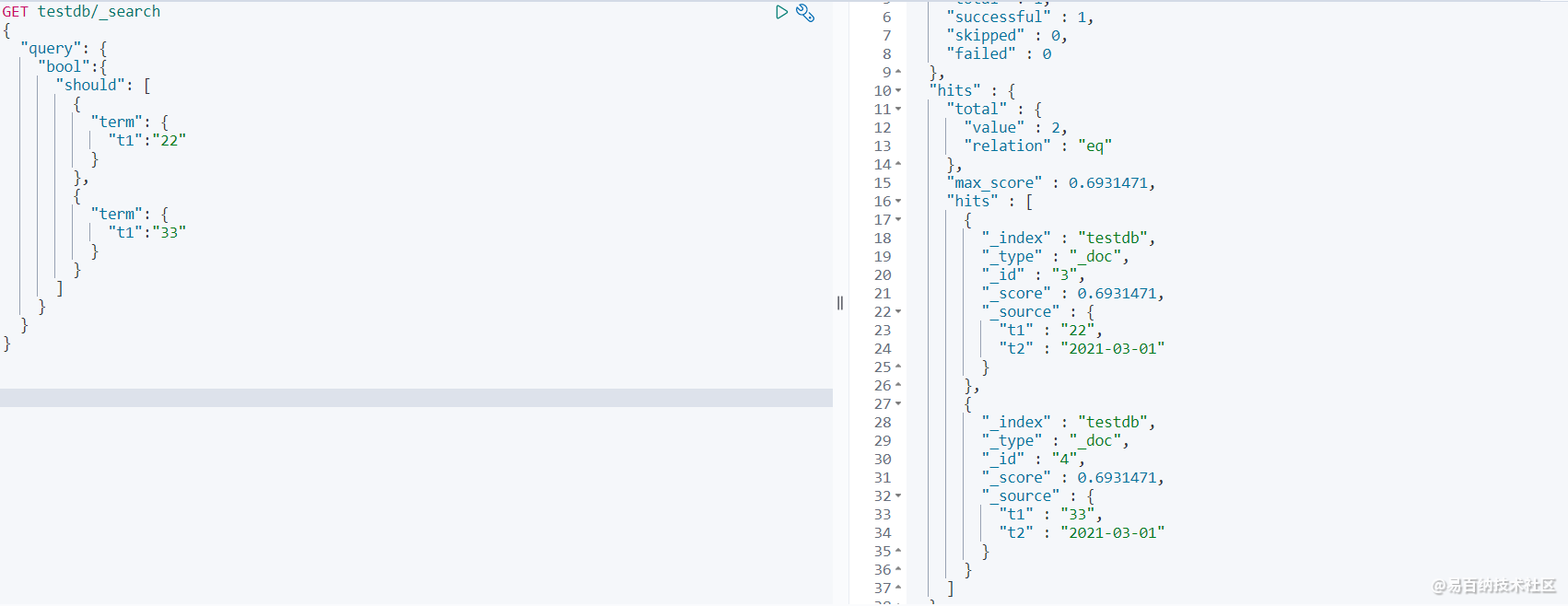 可以发现2条数据也都能查到,证明就算是
可以发现2条数据也都能查到,证明就算是term精确查询,也能够查询多个值。
当然,除了 bool 查询之外,下面这种方式也同样是可以的。
GET testdb/_doc/_search
{
"query":{
"terms":{
"t1":["22","33"]
}
}
}下面要介绍的功能,就是经常被搜索引擎用到的“高亮显示”!
高亮显示
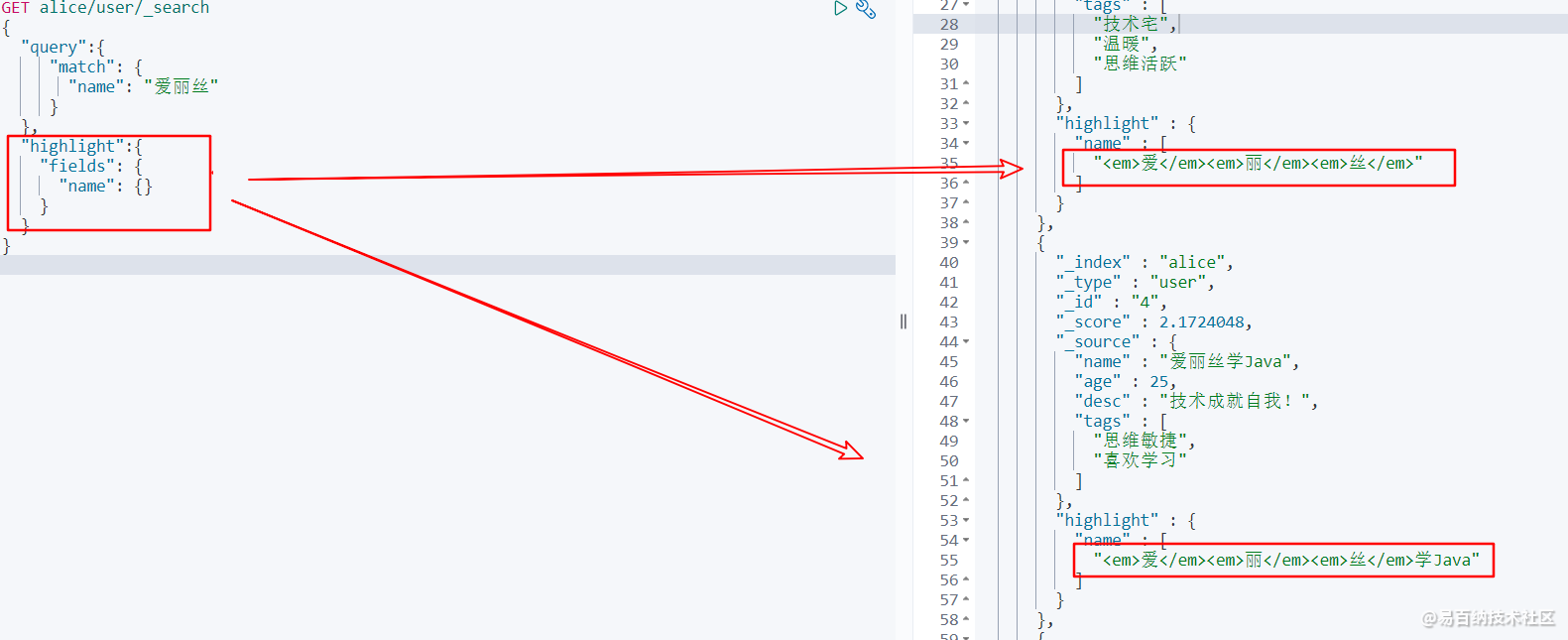
我们可以通过highlight属性,来对我们查询的结果的指定字段做高亮显示!
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
},
"highlight":{
"fields": {
"name": {}
}
}
} 观察返回的结果,我们可以发现搜索相关的结果,被加上了高亮标签<em>
 现在效果看到了,那我们有没有办法自定义样式呢?
现在效果看到了,那我们有没有办法自定义样式呢?
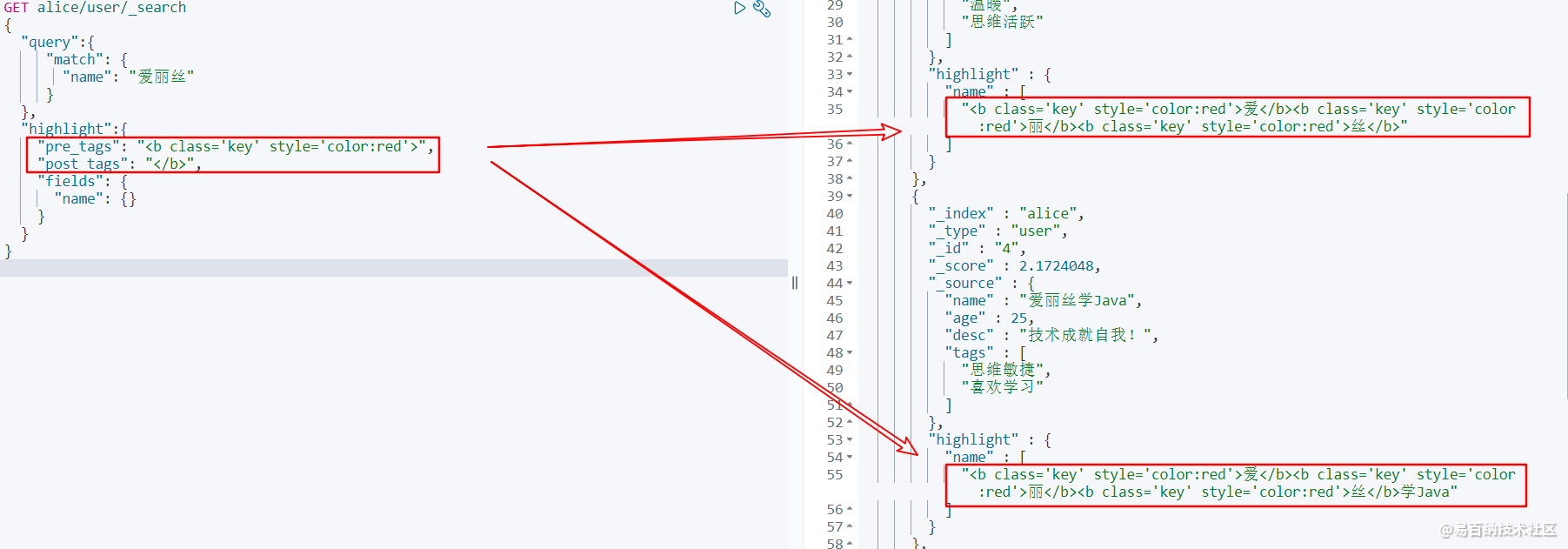
答案当然是可以的,我们需要在pre_tags中定义标签的前缀,post_tags中定义后缀!
GET alice/user/_search
{
"query":{
"match": {
"name": "爱丽丝"
}
},
"highlight":{
"pre_tags": "<b class='key' style='color:red'>",
"post_tags": "</b>",
"fields": {
"name": {}
}
}
} 查询结果:
 好了,学到这里,关于elasticsearch 文档的基本操作基本就演示完了。我们来回顾下:
好了,学到这里,关于elasticsearch 文档的基本操作基本就演示完了。我们来回顾下:
- 简单匹配
- 条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
值得一提的是,这些MySQL也都能做,只是效率较低!
小结
看到这里,写了好几天的 elasticsearch 的入门级教程也算是先告一段落了。对于初学者来说,认真阅读并理解,看完之后,elasticsearch 入个门是没问题的,但是如果能在实际的应用场景中,将其运用起来,相信大家能有更好的理解!因为我是大数据方向的,后续我可能会出关于 elasticsearch 的实战教程 ,敬请期待!喜欢的话记得一键三连,持续关注哟~
巨人的肩膀

- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:5202次2019-10-11 09:26:12
-
浏览量:5707次2020-08-29 19:35:34
-
浏览量:3896次2021-03-31 17:16:31
-
浏览量:4480次2020-08-18 19:54:58
-
浏览量:4710次2022-04-27 19:32:29
-
浏览量:9182次2020-12-08 10:17:40
-
浏览量:2601次2019-11-06 17:56:26
-
浏览量:2517次2018-10-15 21:38:57
-
浏览量:9837次2020-12-06 23:24:07
-
浏览量:12040次2020-12-06 23:22:02
-
浏览量:3386次2020-12-02 09:32:36
-
浏览量:3129次2022-10-25 18:01:01
-
浏览量:1576次2023-05-25 17:13:13
-
浏览量:2355次2019-02-19 10:28:51
-
浏览量:2548次2021-04-15 14:18:42
-
浏览量:1578次2023-09-08 10:47:07
-
浏览量:12049次2020-09-06 23:18:26
-
浏览量:2816次2020-08-29 21:27:46
-
浏览量:4711次2020-08-30 10:14:12
大数据梦想家
一枚有趣的程序员,更多精彩内容请移步公众号@大数据梦想家

-
8篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
大数据梦想家

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
