

【深度学习】眼底图像的视杯和视盘分割解析
【深度学习】眼底图像的视杯和视盘分割解析
文章目录
1 背景
2 概念
2.1 视盘
2.2 视杯
3 数据
4 医学图像分割-Attention Unet
5 注意力机制到底是什么-资源分配给更重要的特征(任务)
6 对比
7 代码1 背景
眼睛是人类视觉感知的重要qiguan,外界光线通过人眼神经细胞形成视觉信号并传输至大脑。眼球主要包括巩膜(眼白)、虹膜、角膜、晶状体、脉络膜、视网膜和视神经、瞳孔、等部分。眼底图像辅助诊断由于其操作简单、花费低、对人体伤害小等优点己经成为大规模视网膜疾病筛查方式的首选。眼底视网膜是形成视觉的重要部分,眼科医生常通过非创伤且便捷的眼底图像方式检查眼底视网膜进行眼部疾病的诊断。眼底图像主要由血管、视盘、黄斑等部分组成,其中可能存在多种病灶特征。在眼底图像辅助诊断中,眼底图像中杯盘比即视杯与视盘的垂直直径比或面积比、视杯与盘沿的相对位置关系等参数的测量对青光眼等眼底疾病的诊断有着重要的意义。此外,通过有关部门对遗传指数的测算,杯盘比的遗传因素为61%,环境因素为39%。这些数字说明杯盘面积比在医学遗传领域中也有研究的空间和价值。所以在对眼底图像进行视盘定位的基础上,采用有效的方法来对视杯盘进行分割已成为眼底图像处理中非常重要的一项工作。
迁移学习一直是计算机视觉的经典问题,利用一个或多个相关源域中的标记数据在目标域中执行任务。域适应是一种特殊的迁移学习,其设定在一个或多个源域中含有标签数据,目标域中数据标签数据稀少或不含标签信息。通过在不同阶段进行领域自适应可将现有的方法大致分为样本适应,特征层面适应和模型层面适应。生成式对抗网络(gan)是由goodfellow等于2014年首次提出,它是通过对抗网来估计生成模型的新框架。同时训练两个模型:生成模型g用来捕获数据样本分布,判别模型d用于判断样本是来自训练数据还是来自g生成的一种概率。该框架训练采用一种最大最小化博弈。xueyuan等提出了一种新的端到端的对抗生成网络segan,用于医学图像分割任务。该方法使用多尺度l1损失函数旨在最大限度地缩短像素之间的短距离空间,分割结果比最先进的u-net分割方法具有更好的性能。
目前,由于拍摄相机型号和角度的不同导致眼底图片存在差异,上述数据来源不同的眼底图片数据无法使用统一模型及参数对视杯视盘进行分割。
2 概念
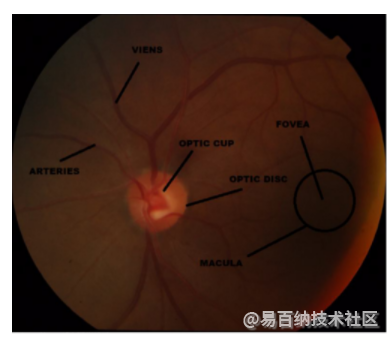
2.1 视盘
视盘是视网膜的中央黄色部分,是进入视网膜的输出血管的入口点。 它的形状或多或少是圆形的,因人而异。 视盘也称为盲点,因为它不包含颜色获取光感受器的视杆和视锥。 它由大量神经元组成。 典型的视盘外观呈橙色至粉红色,但苍白的视盘是一种有疾病的视盘。
2.2 视杯
视杯是视盘上存在的可变尺寸的明亮中央凹陷。 它是用于诊断青光眼的重要参数。 视杯的前进通过阻挡视盘导致青光眼的发生。 与视盘相比,视杯的尺寸更小,并且是正常患者视盘尺寸的三分之一。
3 数据
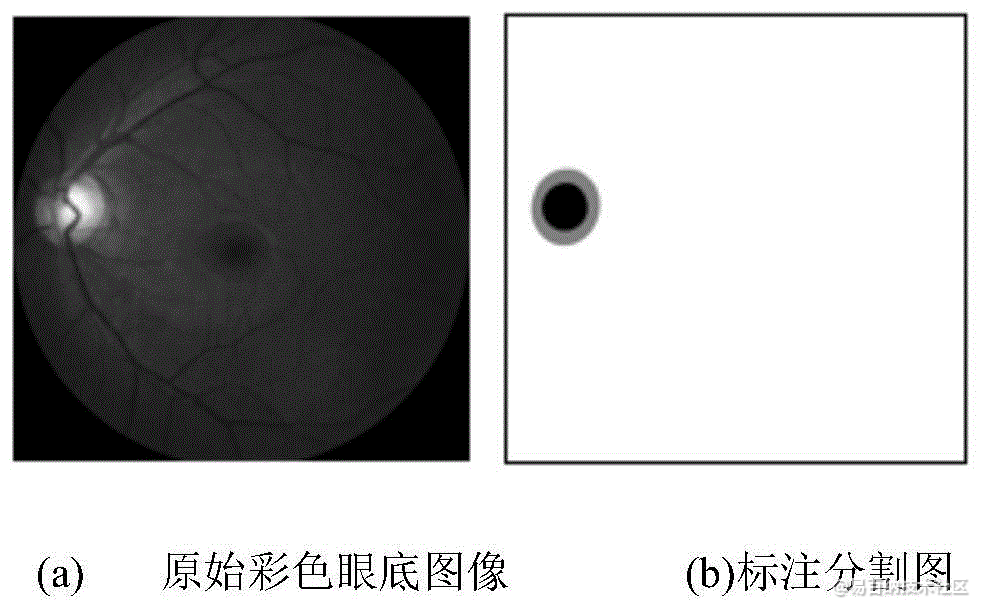
本发明涉及眼底图像处理领域,特别是涉及一种眼底图片视杯视盘分割方法。
The model is trained on DRION dataset. 90 images to train. 19 images to test.
4 医学图像分割-Attention Unet
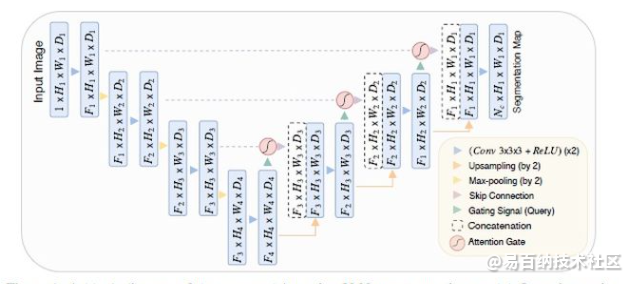
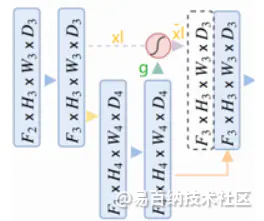
相对于原始版本的Unet,作者提出了一种Attention Gate结构,AG接在每个跳跃连接的末端,对提取的feature实现attention机制。整体结构如下图:
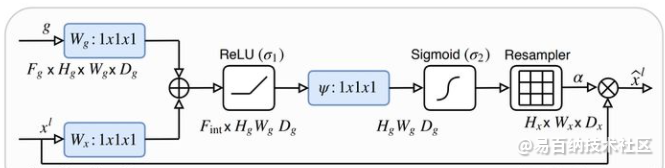
Attention Gate的具体结构如下:

def _concatenation(self, x, g):
input_size = x.size()
batch_size = input_size[0]
assert batch_size == g.size(0)
# theta => (b, c, t, h, w) -> (b, i_c, t, h, w) -> (b, i_c, thw)
# phi => (b, g_d) -> (b, i_c)
theta_x = self.theta(x)
theta_x_size = theta_x.size()
# g (b, c, t', h', w') -> phi_g (b, i_c, t', h', w')
# Relu(theta_x + phi_g + bias) -> f = (b, i_c, thw) -> (b, i_c, t/s1, h/s2, w/s3)
phi_g = F.upsample(self.phi(g), size=theta_x_size[2:], mode=self.upsample_mode)
f = F.relu(theta_x + phi_g, inplace=True)
# psi^T * f -> (b, psi_i_c, t/s1, h/s2, w/s3)
sigm_psi_f = F.sigmoid(self.psi(f))
# upsample the attentions and multiply
sigm_psi_f = F.upsample(sigm_psi_f, size=input_size[2:], mode=self.upsample_mode)
y = sigm_psi_f.expand_as(x) * x
W_y = self.W(y)
return W_y, sigm_psi_ftheta 为kernel_size=2,strides=2的卷积(不添加bias) --> 对上一层进行下采样同时降低通道数使其能与下层的门控信号相加
phi 为kernel_size=1,strides=1的卷积(添加bias) --> 使下一层的feature map得通道数减少
psi 为kernelsize=1,strides=1的卷积(添加bias) --> 生成激活后的attention系数(通道数=1)
其中theta_x的尺寸是phi_g的两倍,降采样后大小是一样的,不太清楚为什么还要使用upsample。
在基础的UNet的基础上增加了attention 的机制,通过自动学习参数来调整激活值,attention的可视化效果还是主要部分,不像non-local的方式每一个像素点都要和其他像素点进行关联,可以视作一种隐式的注意力机制。
5 注意力机制到底是什么-资源分配给更重要的特征(任务)
注意力机制(Attention Mechanism)源于对人类视觉的研究。在认知科学中,由于信息处理的瓶颈,人类会选择性地关注所有信息的一部分,同时忽略其他可见的信息。上述机制通常被称为注意力机制。人类视网膜不同的部位具有不同程度的信息处理能力,即敏锐度(Acuity),只有视网膜中央凹部位具有最强的敏锐度。为了合理利用有限的视觉信息处理资源,人类需要选择视觉区域中的特定部分,然后集中关注它。例如,人们在阅读时,通常只有少量要被读取的词会被关注和处理。综上,注意力机制主要有两个方面:决定需要关注输入的哪部分;分配有限的信息处理资源给重要的部分。
注意力机制是上世纪九十年代,一些科学家在研究人类视觉时,发现的一种信号处理机制。人工智能领域的从业者把这种机制引入到一些模型里,并取得了成功。目前,注意力机制已经成为深度学习领域,尤其是自然语言处理领域,应用最广泛的“组件”之一。这两年曝光度极高的BERT、GPT、Transformer等等模型或结构,都采用了注意力机制。
假设我和wife在超市里买菜。我需要时不时地从人海里找到买了跳刀的wife。我的眼睛真厉害,可以看到这么多东西,视线范围内所有事物的形状、颜色、纹路等等全都接收进来——大脑表示压力很大,实在处理不过来,于是选择忽略一部分信号,重点看每一个人的发型、衣服颜色、站姿等,而且重点分析靠近视线范围中心的区域。我转动脑袋,帮助眼睛扫描更大的范围,从而帮助大脑分析更多的人,终于找到了目标。

注意力机制的一种非正式的说法是,神经注意力机制可以使得神经网络具备专注于其输入(或特征)子集的能力:选择特定的输入。注意力可以应用于任何类型的输入而不管其形状如何。在计算能力有限情况下,注意力机制(attention mechanism)是解决信息超载问题的主要手段的一种资源分配方案,将计算资源分配给更重要的任务
图像描述生成是输入一幅图像,输出这幅图像对应的描述。图像描述生成也是采用“编码-解码”的方式进行。编码器为一个卷积网络,提取图像的高层特征,表示为一个编码向量;解码器为一个循环神经网络语言模型,初始输入为编码向量,生成图像的描述文本。在图像描述生成的任务中,同样存在编码容量瓶颈以及长距离依赖这两个问题,因此也可以利用注意力机制来有效地选择信息。在生成描述的每一个单词时,循环神经网络的输入除了前一个词的信息,还有利用注意力机制来选择一些来自于图像的相关信息。
6 对比
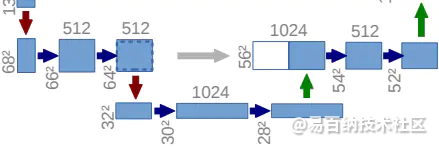
总结:
利用下采样层的结构化信息和当前层纹理信息的融合,利用sigmoid归一化,得到关联性强的区域,和当前层做乘积,从而强调本层的显著性区域的特征。
7 代码
Post-Process Methods
When directly use unet model, we often get some error predictions. So I use a post-process algorithm:
predicted area can't be to small.
minimum bounding rectangle's height/width or width/height should be in 0.45~2.5
lefted area is the final output. The problem of this algorithm is that the parameters not self-adjusting, so you have to change them if input image is larger or smaller than before.
Project Structure
The structure is based on my own DL_Segmention_Template. Difference between this project and the template is that we have metric module in dir: perception/metric/. To get more Information about the structure please see readme in DL_Segmention_Template.
You can find model parameter in configs/segmention_config.json.
First to run
please run main_trainer.py first time, then you will get data_route in experiment dir. Put your data in there, now you can run main_trainer.py again to train a model.
where to put Pretrained Model
The model is trained with DRION dataset on my own desktop (intel i7-7700hq, 24g, gtx1050 2g) within 30 minutes. Dataset
Test your own image
If u want to test your own image, put your image to (OpticDisc)/test/origin,and change the img_type of predict settings in configs/segmention_config.json, run main_test.py to get your result. The result is in (OpticDisc)/test/result
class AttU_Net(nn.Module):
def __init__(self,img_ch=3,output_ch=1):
super(AttU_Net,self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2,stride=2)
self.Conv1 = conv_block(ch_in=img_ch,ch_out=64)
self.Conv2 = conv_block(ch_in=64,ch_out=128)
self.Conv3 = conv_block(ch_in=128,ch_out=256)
self.Conv4 = conv_block(ch_in=256,ch_out=512)
self.Conv5 = conv_block(ch_in=512,ch_out=1024)
self.Up5 = up_conv(ch_in=1024,ch_out=512)
self.Att5 = Attention_block(F_g=512,F_l=512,F_int=256)
self.Up_conv5 = conv_block(ch_in=1024, ch_out=512)
self.Up4 = up_conv(ch_in=512,ch_out=256)
self.Att4 = Attention_block(F_g=256,F_l=256,F_int=128)
self.Up_conv4 = conv_block(ch_in=512, ch_out=256)
self.Up3 = up_conv(ch_in=256,ch_out=128)
self.Att3 = Attention_block(F_g=128,F_l=128,F_int=64)
self.Up_conv3 = conv_block(ch_in=256, ch_out=128)
self.Up2 = up_conv(ch_in=128,ch_out=64)
self.Att2 = Attention_block(F_g=64,F_l=64,F_int=32)
self.Up_conv2 = conv_block(ch_in=128, ch_out=64)
self.Conv_1x1 = nn.Conv2d(64,output_ch,kernel_size=1,stride=1,padding=0)
def forward(self,x):
# encoding path
x1 = self.Conv1(x)
x2 = self.Maxpool(x1)
x2 = self.Conv2(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv3(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv4(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv5(x5)
# decoding + concat path
d5 = self.Up5(x5)
x4 = self.Att5(g=d5,x=x4)
d5 = torch.cat((x4,d5),dim=1)
d5 = self.Up_conv5(d5)
d4 = self.Up4(d5)
x3 = self.Att4(g=d4,x=x3)
d4 = torch.cat((x3,d4),dim=1)
d4 = self.Up_conv4(d4)
d3 = self.Up3(d4)
x2 = self.Att3(g=d3,x=x2)
d3 = torch.cat((x2,d3),dim=1)
d3 = self.Up_conv3(d3)
d2 = self.Up2(d3)
x1 = self.Att2(g=d2,x=x1)
d2 = torch.cat((x1,d2),dim=1)
d2 = self.Up_conv2(d2)
d1 = self.Conv_1x1(d2)
return d1
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:7670次2021-05-04 20:17:10
-
浏览量:17744次2021-07-29 10:22:10
-
浏览量:10149次2021-06-21 11:49:58
-
浏览量:13963次2021-05-11 15:08:10
-
浏览量:8380次2021-07-19 17:08:40
-
浏览量:17894次2021-05-31 17:01:00
-
浏览量:7313次2021-06-07 09:26:53
-
浏览量:15388次2021-07-05 09:47:30
-
浏览量:8285次2021-07-19 17:10:27
-
浏览量:10063次2021-07-19 17:09:44
-
浏览量:7073次2021-05-17 16:48:29
-
浏览量:8094次2021-06-15 10:28:29
-
浏览量:157次2023-08-30 15:28:02
-
浏览量:5596次2021-04-21 17:06:33
-
浏览量:2125次2023-02-14 14:48:11
-
浏览量:17289次2021-04-28 16:21:52
-
浏览量:7867次2021-04-29 12:46:50
-
浏览量:12062次2021-06-25 15:00:55
-
浏览量:6244次2021-08-02 09:34:03

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
246篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
