摘要
本文首先介绍了机器学习中的计算图概念,然后从概念上区分动态图与静态图,最后使用经典的手写数字识别的实例对这两个概念做一个区分。
计算图介绍
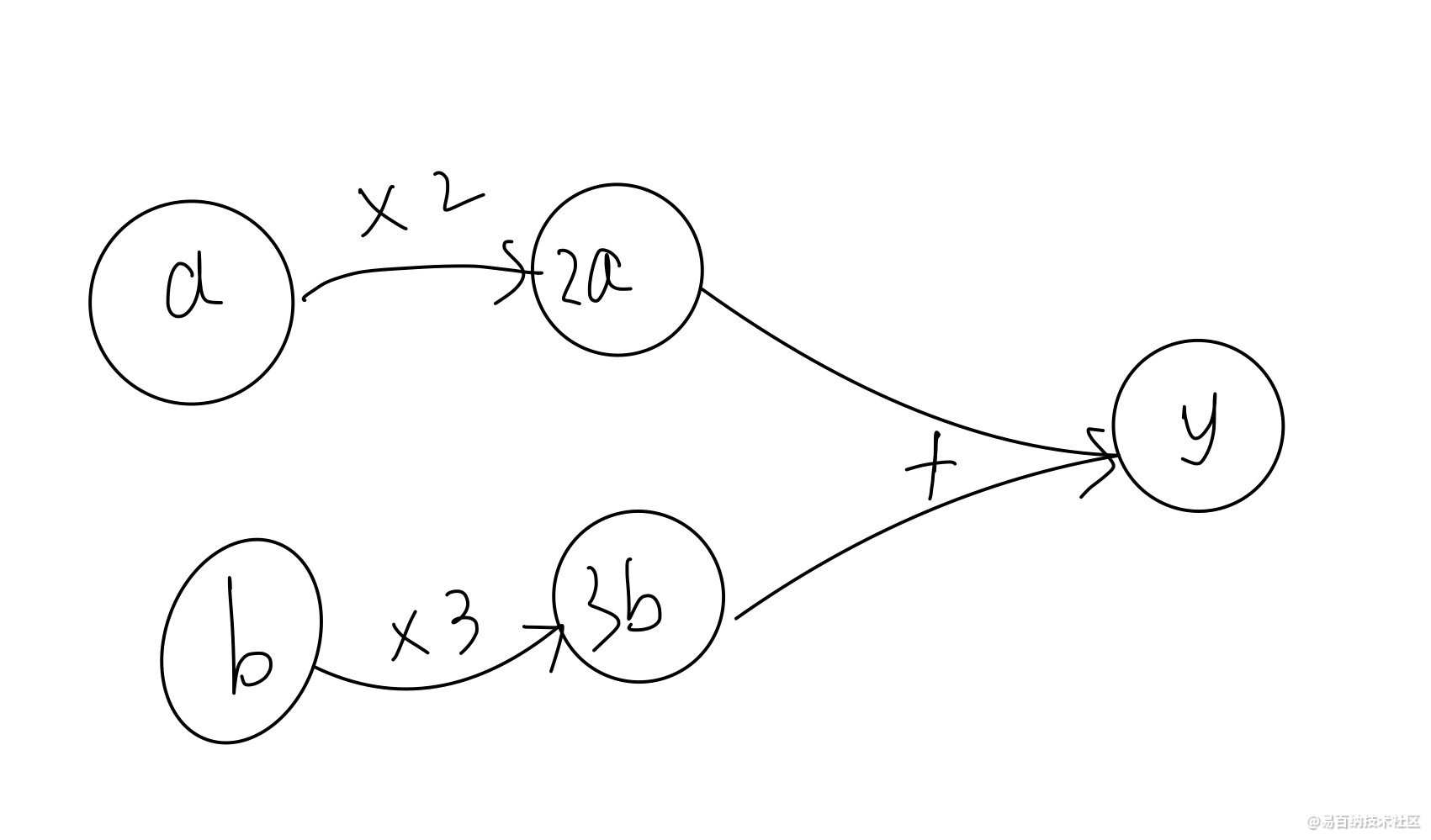
计算图是一种用于表示计算过程的数据结构,它有两个元素——节点和边。节点表示数据,边表示数据流动,即运算过程。如下图所示,该图结构用来描述y=2a+3b的计算过程。计算图在机器学习中被广泛使用,很好地帮助我们理解和调试神经网络。
前向传播过程与反向传播过程
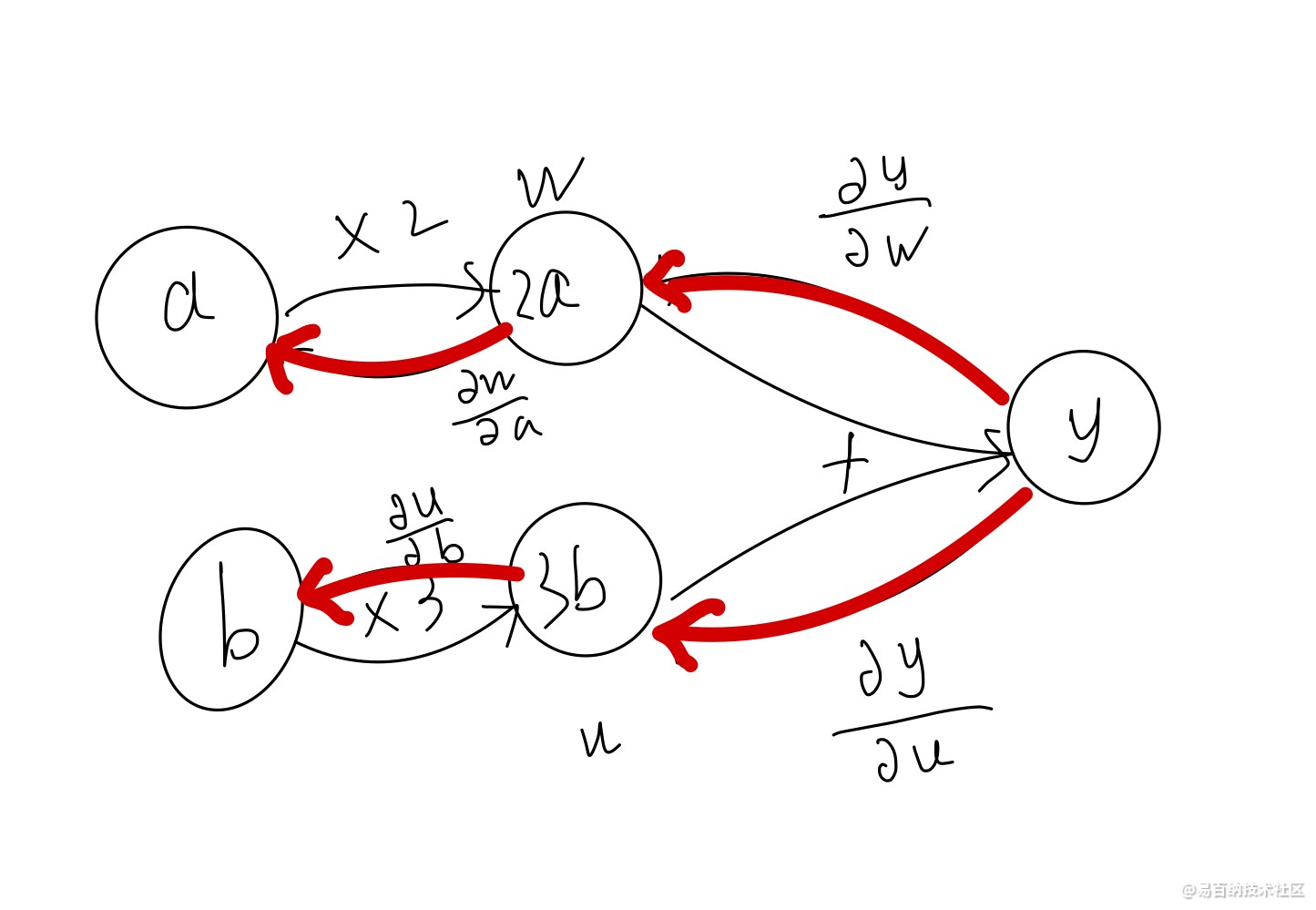
如下图所示,前向传播就是数据从输入节点开始,经各个运算一步一步到达输出节点的过程。反向传播就是输出反馈到各个节点的过程。在神经网络中,前向传播一般表示对结果的预测,反向传播是结果对各个节点的偏导数,用于修正各节点,优化模型参数。
动态图与静态图
在机器学习中,静态图和动态图是两种不同的计算图。静态图是一种预先定义的计算图,它在编译时生成神经网络的结构,然后执行相应的操作。这种机制使得静态图在编译时可以进行更大程度的优化,但这也意味着如果期望的程序与编译器实际执行之间存在更多的代沟。由于静态图的神经网络结构在编译时已经预先定义好,不需要重新构建,因此速度相对较快。
动态图则是在运行时动态地构建计算图,无需构建整个图就可以立即执行结果,这意味着程序将按照研发人员编写命令的顺序进行执行,使得调试更加容易,同时也使得将大脑中的想法转化为实际代码变得更加容易。利用动态图机制,我们能够更加快捷、直观地构建我们的深度学习网络。然而,动态图每次运行时都会重新构建网络结构,这可能会导致速度较慢。
诸多知名的机器学习库都基于计算图实现,例如,开源的python机器学习库PyTorch便使用动态图,Tensorflow便使用静态图。本文我用百度的paddle机器学习库分别使用静态图和动态图构建手写数字识别网络,更好地对比两种类型图的区别。
用静态图实现手写数字识别
一、获取训练数据
import paddle
import paddle.fluid as fluid
import numpy as np
train_set=paddle.dataset.mnist.train()
train_reader=paddle.batch(train_set,batch_size=16)
test_set=paddle.dataset.mnist.test()
test_reader=paddle.batch(test_set,batch_size=32)
二、模型设计与初始化
def net(input):
hidden1 = fluid.layers.fc(input=input, size=100, act='relu')
hidden2 = fluid.layers.fc(input=hidden1, size=100, act='relu')
prediction = fluid.layers.fc(input=hidden2, size=10, act='softmax')
return prediction
image = fluid.layers.data(name='image', shape=[1, 28, 28], dtype='float32')
label = fluid.layers.data(name='label', shape=[1], dtype='int64')
predict = net(image)
cost = fluid.layers.cross_entropy(input=predict, label=label)
avg_cost = fluid.layers.mean(cost)
acc = fluid.layers.accuracy(input=predict, label=label)
test_program = fluid.default_main_program().clone(for_test=True)
optimizer = fluid.optimizer.SGDOptimizer(learning_rate=0.001)
opts = optimizer.minimize(avg_cost)
use_cuda = False
place = fluid.CUDAPlace(0) if use_cuda else fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
fluid.default_startup_program()程序保存的是模型的初始化参数,这里便是静态图与动态图的主要区别,动态图没有初始化模型这一步骤,定义好网络之后,便可以直接进行训练等后续操作。
三、模型的训练与保存
feeder = fluid.DataFeeder(place=place, feed_list=[image, label])
EPOCH_NUM=2
model_save_dir = "/home/aistudio/work/hand.inference.model"
for pass_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_reader()):
train_cost, train_acc = exe.run(program=fluid.default_main_program(),
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
if batch_id % 200 == 0:
print('Pass:%d, Batch:%d, Cost:%0.5f, Accuracy:%0.5f' %
(pass_id, batch_id, train_cost[0], train_acc[0]))
test_accs = []
test_costs = []
for batch_id, data in enumerate(test_reader()):
test_cost, test_acc = exe.run(program=test_program,
feed=feeder.feed(data),
fetch_list=[avg_cost, acc])
test_accs.append(test_acc[0])
test_costs.append(test_cost[0])
test_cost = (sum(test_costs) / len(test_costs))
test_acc = (sum(test_accs) / len(test_accs))
print('Test:%d, Cost:%0.5f, Accuracy:%0.5f' % (pass_id, test_cost, test_acc))
fluid.io.save_inference_model(model_save_dir,
['image'],
[predict],
exe)
用动态图实现手写数字识别
一、获取训练数据
import paddle
import paddle.fluid as fluid
import numpy as np
train_set=paddle.dataset.mnist.train()
train_reader=paddle.batch(train_set,batch_size=16)
test_set=paddle.dataset.mnist.test()
test_reader=paddle.batch(test_set,batch_size=32)
二、模型设计
iimport paddle.fluid as fluid
from paddle.fluid.dygraph import Linear
class net(fluid.dygraph.Layer):
def __init__(self):
super(net,self).__init__()
name_scope=self.full_name()
self.hidden1=Linear(input_dim=28*28,output_dim=100,act='relu')
self.hidden2=Linear(input_dim=100,output_dim=100,act='relu')
self.fc=Linear(input_dim=100,output_dim=10,act='softmax')
def forward(self,x):
x = fluid.layers.reshape(x, [x.shape[0], -1])
x=self.hidden1(x)
x=self.hidden2(x)
y=self.fc(x)
return y
三、模型的训练与保存
with fluid.dygraph.guard():
model=net()
model.train()
opt=fluid.optimizer.SGDOptimizer(learning_rate=0.001,parameter_list=model.parameters())
epochs_num=2
for pass_num in range(epochs_num):
for batch_id,data in enumerate(train_reader()):
images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32)
labels=np.array([x[1] for x in data]).astype('int64')
labels=labels[:,np.newaxis]
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)
acc=fluid.layers.accuracy(predict,label)
if batch_id!=0 and batch_id%1000==0:
print("pass:{},batch_id:{},train_loss:{},train_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
avg_loss.backward()
opt.minimize(avg_loss)
model.clear_gradients()
for batch_id,data in enumerate(test_reader()):
images=np.array([x[0].reshape(1, 28, 28) for x in data],np.float32)
labels=np.array([x[1] for x in data]).astype('int64').reshape(-1,1)
image=fluid.dygraph.to_variable(images)
label=fluid.dygraph.to_variable(labels)
predict=model(image)
loss=fluid.layers.cross_entropy(predict,label)
avg_loss=fluid.layers.mean(loss)
acc=fluid.layers.accuracy(predict,label)
if batch_id!=0 and batch_id%300==0:
print("pass:{},batch_id:{},test_loss:{},test_acc:{}".format(pass_num,batch_id,avg_loss.numpy(),acc.numpy()))
fluid.save_dygraph(model.state_dict(),'mnist')
总结
通过对静态图和动态图概念的论述以及两个例子,可以很清晰地看到动态图与静态图的区别。静态图在定义好网络模型后,有一个参数初始化的过程,整个计算分为两步:初始化网络参数和进行模型运算,在初始化网络模型参数后,后续计算不用再初始化,程序运行效率高;而动态图在定义好网络参数后直接可以拿来就行数据运算,更符合我们的编程习惯,设计效率更高。



 微信扫码分享
微信扫码分享 QQ好友
QQ好友













