

【深度学习】新的深度学习优化器探索(协同优化)
【深度学习】新的深度学习优化器探索(协同优化)

文章目录
1 RAdam VS Adam
2 自适应优化
3 LookAhead
3.1 “侵入式”优化器
3.2 LookAhead 中的参数:
4 RAdam 加 LookAhead 的一个实现:Ranger1 RAdam VS Adam
1,目的
想找到一个比较好的优化器,能够在收敛速度和收敛的效果上都比较好。
目前sgd收敛较好,但是慢。
adam收敛快,但是容易收敛到局部解。
常用解决adam收敛问题的方法是,自适应启动方法。
2,adam方法的问题
adam在训练的初期,学习率的方差较大。
根本原因是因为缺少数据,导致方差大。
学习率的方差大,本质上自适应率的方差大。
可以控制自适应率的方差来改变效果。
3,Radam,控制自适应率的方差
一堆数学公式估计出自适应率的最大值和变化过程。
提出了Radam的优化过程
它兼有Adam和SGD两者的优点,既能保证收敛速度快,也不容易掉入局部最优解,而且收敛结果对学习率的初始值非常不敏感。在较大学习率的情况下,RAdam效果甚至还优于SGD。
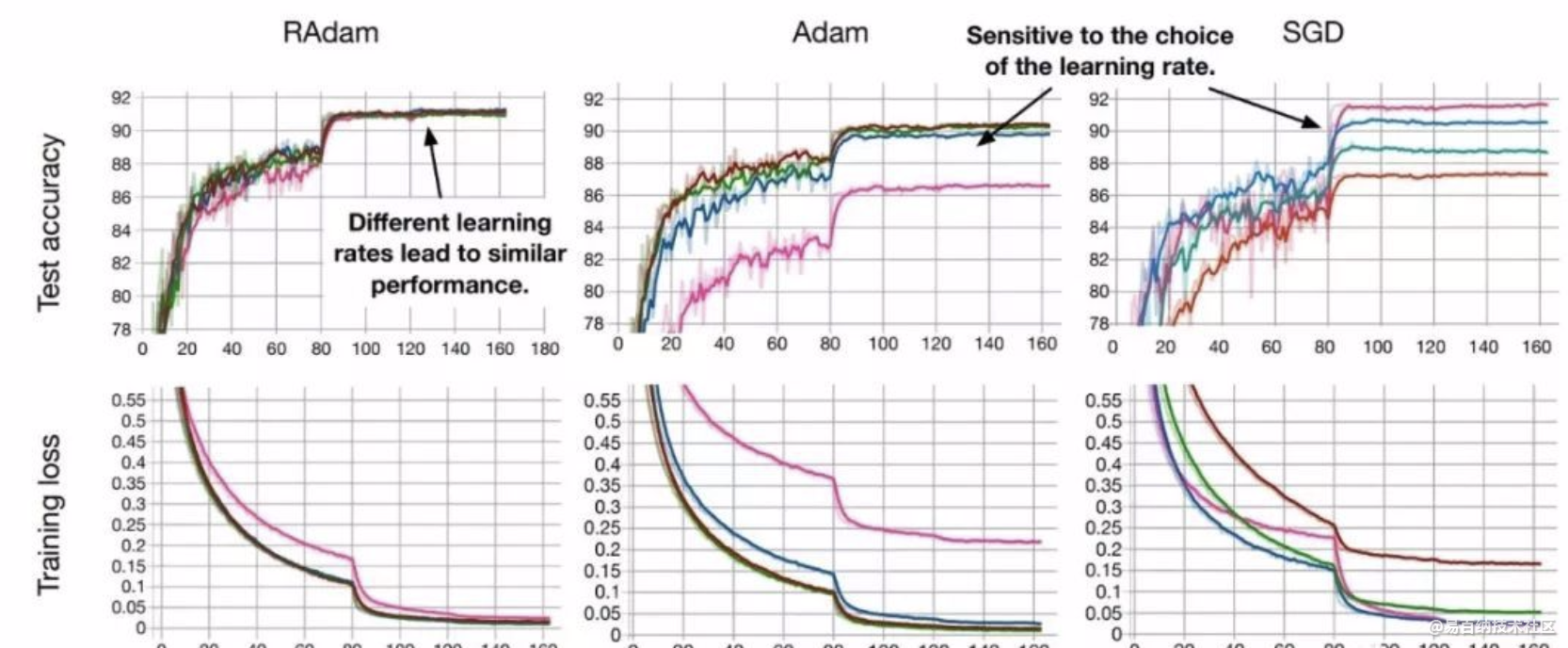
RAdam意思是“整流版的Adam”(Rectified Adam),它能根据方差分散度,动态地打开或者关闭自适应学习率,并且提供了一种不需要可调参数学习率预热的方法。
一位Medium网友Less Wright在测试完RAdam算法后,给予了很高的评价:
RAdam可以说是最先进的AI优化器,可以永远取代原来的Adam算法了。
目前论文作者已将RAdam开源,FastAI现在已经集成了RAdam,只需几行代码即可直接调用。
总结:RAdam可以说是AI最新state of the art优化器
正如你所看到的,RAdam提供了一个动态启发式方法来提供自动化的方差衰减,从而消除了在训练期间warmup所涉及手动调优的需要。
此外,RAdam对学习速率变化(最重要的超参数)具有更强的鲁棒性,并在各种数据集和各种AI体系结构中提供更好的训练精度和泛化。
简而言之,我强烈建议您将RAdam放到你的AI架构中,看看你有没有立即获得好处。我愿意提供退款保证,但因为它的成本是0.00美元…
PyTorch的官方github提供了RAdam的实现:https://github.com/LiyuanLucasLiu/RAdam。
FastAI用户可以很容易地使用RAdam如下:

导入RAdam,声明为一个局部函数(根据需要添加参数)

2 自适应优化
针对简单的SGD及Momentum存在的问题,2011年John Duchi等发布了AdaGrad优化算法(Adaptive Gradient,自适应梯度),它能够对每个不同的参数调整不同的学习率,对频繁变化的参数以更小的步长进行更新,而稀疏的参数以更大的步长进行更新。
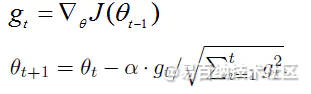
2014年12月,Kingma和Lei Ba两位学者提出了Adam优化器,结合AdaGrad和RMSProp两种优化算法的优点。对梯度的一阶矩估计(First Moment Estimation,即梯度的均值)和二阶矩估计(Second
Moment Estimation,即梯度的未中心化的方差)进行综合考虑,计算出更新步长。
主要包含以下几个显著的优点:
-
实现简单,计算高效,对内存需求少
-
参数的更新不受梯度的伸缩变换影响
-
超参数具有很好的解释性,且通常无需调整或仅需很少的微调
-
更新的步长能够被限制在大致的范围内(初始学习率)
-
能自然地实现步长退火过程(自动调整学习率)
-
很适合应用于大规模的数据及参数的场景
-
适用于不稳定目标函数
-
适用于梯度稀疏或梯度存在很大噪声的问题
普通更新
最简单的沿着负梯度方向改变参数(梯度指向的是上升方向,但要最小化损失函数)。假设有一个参数向量x及其梯度dx,那么最简单的更新的形式是:# 普通更新
x += - learning_rate * dx其中,learning_rate是一个超参数,它是一个固定常量。当在整个数据集上进行计算时,只要学习率足够低,总是能在损失函数上得到非负的进展。
动量(Momentum)更新该方法从物理角度上对于最优化问题得到的启发。损失值是山的高度(因此高度势能是 ,所以有 )。最优化过程可以看做是模拟参数向量(即质点)在地形上滚动的过程。因为作用于质点的力与梯度潜在能量( )有关,质点所受的力就是损失函数的(负)梯度。
v = mu * v - learning_rate * dx # 与速度融合
x += v # 与位置融合梯度下降:我们知道曲面上方向导数的最大值的方向就代表了梯度的方向,因此我们在做梯度下降的时候,应该是沿着梯度的反方向进行权重的更新,可以有效的找到全局的最优解。
3 LookAhead
它源于论文《Lookahead Optimizer: k steps forward, 1 step back》,是最近才提出来的优化器,有意思的是大牛Hinton和Adam的作者之一Jimmy Ba也出现在了论文作者列表当中,有这两个大神加持,这个优化器的出现便吸引了不少目光。
Lookahead的思路很朴素,准确来说它并不是一个优化器,而是一个使用现有优化器的方案。简单来说它就是下面三个步骤的循环执行:
1、备份模型现有的权重θ;
2、从θ出发,用指定优化器更新k步,得到新权重θ̃ ;
3、更新模型权重为θ←θ+α(θ̃ −θ)。3.1 “侵入式”优化器
上面实现优化器的方案是标准的,也就是按Keras的设计规范来做的,所以做起来很轻松。然而我曾经想要实现的一个优化器,却不能用这种方式来实现,经过阅读源码,得到了一种“侵入式”的写法,这种写法类似“外挂”的形式,可以实现我需要的功能,但不是标准的写法。
from keras.optimizers import Optimizer
from keras import backend as K
class InjectOptimizer(Optimizer):
"""定义注入式优化器的基类
需要传入模型,直接修改模型的训练函数,而不按常规流程使用优化器,所以称为“侵入式”
其实下面的大部分代码,都是直接抄自keras的源码:
https://github.com/keras-team/keras/blob/master/keras/engine/training.py#L497
也就是keras中的_make_train_function函数。
"""
def get_updates(self, loss, params):
return []
def get_grouped_updates(self, loss, params):
raise NotImplementedError
def inject(self, model):
"""传入模型做注入
"""
if not hasattr(model, 'train_function'):
raise RuntimeError('You must compile your model before using it.')
model._check_trainable_weights_consistency()
if model.train_function is None:
inputs = (model._feed_inputs +
model._feed_targets +
model._feed_sample_weights)
if model._uses_dynamic_learning_phase():
inputs += [K.learning_phase()]
with K.name_scope('training'):
train_functions = []
with K.name_scope(model.optimizer.__class__.__name__):
grouped_training_updates = self.get_grouped_updates(
params=model._collected_trainable_weights,
loss=model.total_loss)
for i, updates in enumerate(grouped_training_updates[1:]):
f = K.function(
inputs,
[model.total_loss],
updates=updates,
name='train_function_%s' % (i + 1),
**model._function_kwargs)
train_functions.append(f)
# Gets loss and metrics. Updates weights at each call.
first_updates = (model.updates +
grouped_training_updates[0],
model.metrics_updates)
first_train = K.function(
inputs,
[model.total_loss] + model.metrics_tensors,
updates=first_updates,
name='train_function',
**model._function_kwargs)
def F(inputs):
R = first_train(inputs)
for f in train_functions:
f(inputs)
return R
model.train_function = F
class HeunOptimizer(InjectOptimizer):
"""Heun优化器
( https://en.wikipedia.org/wiki/Heun%27s_method )
"""
def __init__(self, lr, **kwargs):
super(HeunOptimizer, self).__init__(**kwargs)
with K.name_scope(self.__class__.__name__):
self.lr = K.variable(lr, name='lr')
def get_updates_1(self, loss, params, cache_grads):
updates = []
grads = self.get_gradients(loss, params)
for p, g, cg in zip(params, grads, cache_grads):
updates.append(K.update(cg, g))
updates.append(K.update(p, p - self.lr * g))
return updates
def get_updates_2(self, loss, params, cache_grads):
updates = []
grads = self.get_gradients(loss, params)
for p, g, cg in zip(params, grads, cache_grads):
updates.append(K.update(p, p - 0.5 * self.lr * (g - cg)))
return updates
def get_grouped_updates(self, loss, params):
cache_grads = [K.zeros(K.int_shape(p)) for p in params]
return [
self.get_updates_1(loss, params, cache_grads),
self.get_updates_2(loss, params, cache_grads)
]
用法是:
opt = HeunOptimizer(0.1)
model.compile(loss='mse', optimizer=opt)
opt.inject(model) # 必须执行这步
model.fit(x_train, y_train, epochs=100, batch_size=32)用法就很简单了:
model.compile(optimizer=Adam(1e-3), loss='mse') # 用你想用的优化器
lookahead = Lookahead(k=5, alpha=0.5) # 初始化Lookahead
lookahead.inject(model) # 插入到模型中至于效果,原论文中做了不少实验,有些有轻微提高(cifar10和cifar100那两个),有些提升还比较明显(LSTM做语言模型那个),我自己简单实验了一下,结果是没什么变化。我一直觉得优化器是一个很玄乎的存在,有时候非得SGD才能达到最优效果,有时候又非得Adam才能收敛得下去,总之不能指望单靠换一个优化器就能大幅度提升模型效果。Lookahead的出现,也就是让我们多一种选择罢了,训练时间充足的读者,多去尝试一下就好。
该研究表明这种更新机制能够有效地降低方差。研究者发现 Lookahead 对次优超参数没那么敏感,因此它对大规模调参的需求没有那么强。此外,使用 Lookahead 及其内部优化器(如 SGD 或 Adam),还能实现更快的收敛速度,因此计算开销也比较小。
研究者在多个实验中评估 Lookahead 的效果。比如在 CIFAR 和 ImageNet 数据集上训练分类器,并发现使用 Lookahead 后 ResNet-50 和 ResNet-152 架构都实现了更快速的收敛。
研究者还在 Penn Treebank 数据集上训练 LSTM 语言模型,在 WMT 2014 English-to-German 数据集上训练基于 Transformer 的神经机器翻译模型。在所有任务中,使用 Lookahead 算法能够实现更快的收敛、更好的泛化性能,且模型对超参数改变的鲁棒性更强。
这些实验表明 Lookahead 对内部循环优化器、fast weight 更新次数以及 slow weights 学习率的改变具备鲁棒性。
Lookahead Optimizer 怎么做
Lookahead 迭代地更新两组权重:slow weights φ 和 fast weights θ,前者在后者每更新 k 次后更新一次。Lookahead 将任意标准优化算法 A 作为内部优化器来更新 fast weights。
使用优化器 A 经过 k 次内部优化器更新后,Lookahead 通过在权重空间 θ − φ 中执行线性插值的方式更新 slow weights,方向为最后一个 fast weights。
slow weights 每更新一次,fast weights 将被重置为目前的 slow weights 值。Lookahead 的伪代码见下图 Algorithm 1。

其中最优化器 A 可能是 Adam 或 SGD 等最优化器,内部的 for 循环会用常规方法更新 fast weights θ,且每次更新的起始点都是从当前的 slow weights φ 开始。最终模型使用的参数也是慢更新那一套,因此快更新相当于做了一系列实验,然后慢更新再根据实验结果选一个比较好的方向,这有点类似 Nesterov Momentum 的思想。
看上去这只是一个小技巧?
3.2 LookAhead 中的参数:
k - 它控制快优化器的权重和 LookAhead 中的慢优化器的权重协同更新的间隔。默认值一般是 5 或者 6,不过 LookAhead 论文里最大也用过 20。
alpha - 它控制根据快慢优化器权重之差的多少比例来更新快优化器的权重。默认值是 0.5,LookAhead 论文作者 Hinton 等人在论文里给出了一个强有力的证明,表示 0.5 可能就是理想值。不过大家也可以做自己的尝试。
他们也在论文中指出,未来一个可能的改进方向是根据训练进行到不同的阶段,规划使用不同的 k 和 alpha 的值。
4 RAdam 加 LookAhead 的一个实现:Ranger
在解释过 LookAhead 的工作原理以后我们可以看出来,其中的那个快优化器可以选用任意一个现有的优化器。在 LookAhead 论文中他们使用的是最初的 Adam,毕竟那时候 RAdam 还没有发布呢。

那么显然,要实现 RAdam 加 LookAhead,只需要把原来的 LookAhead 中的 Adam 优化器替换成 RAdam 就可以了。
在 FastAI 中,合并 RAdam 和 LookAhead 的代码是一件非常容易的事情,他使用的 LookAhead 代码来自 LonePatient,RAdam 则来自论文作者们的官方代码。Less Wright 把合并后的这个新优化器称作 Ranger(其中的前两个字母 RA 来自 RAdam,Ranger 整个单词的意思“突击队员”则很好地体现出了 LookAhead 能出色地探索损失空间的特点)。
Ranger 的代码开源在 https://github.com/lessw2020/Ranger-Deep-Learning-Optimizer?source=post_page-----2dc83f79a48d----------------------
使用方法:
把 ranger.py 拷贝到工作目录下
import ranger
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:3884次2021-05-26 15:42:50
-
浏览量:4274次2021-05-28 16:59:07
-
浏览量:3935次2021-05-18 15:15:50
-
浏览量:5700次2021-06-11 12:41:01
-
浏览量:4178次2021-04-20 15:50:27
-
浏览量:267次2023-07-25 11:57:50
-
浏览量:49573次2021-07-28 14:21:08
-
浏览量:5630次2021-07-28 14:21:28
-
浏览量:6739次2021-04-29 12:46:50
-
浏览量:10390次2021-06-25 15:00:55
-
浏览量:6927次2021-06-15 10:28:29
-
浏览量:5846次2021-06-07 11:48:50
-
浏览量:3838次2021-04-19 14:54:23
-
浏览量:5966次2021-05-04 20:17:10
-
浏览量:6905次2021-05-19 16:25:40
-
浏览量:303次2023-08-22 15:12:16
-
浏览量:4147次2021-04-09 16:28:04
-
浏览量:3866次2021-04-14 16:23:03
-
浏览量:1150次2023-02-13 10:31:50

这把我C
完整的教程https://fizzz.blog.csdn.net。该网站都是残缺




-
241篇
-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
这把我C

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
