

一个非常实用的H264视频解码器开源项目

一、前言:
为了弄清楚H264整个解码流程,为此我专门按照H264标准文档 《T-REC-H.264-201704-S!!PDF-E.pdf》,用C++实现了一个H264裸码流视频解码器,代码工程地址为:
https://github.com/jfu222/h264_video_decoder_demo
自己之前在视频解码行当也干了个两三年,基本上都是用的开源的ffmpeg来解码各种视频,需要特别说明的是,早些年国内安防领域的视频码流真是百花齐放,也是填坑无数,苦了俺们这些搬砖的。好在现在基本上都是H264/H265码流了。另一方面,现在基于视频内容的深度学习又开始大流行,后来有一次出苦差,现场某一刑侦大佬说,你们现在这个算法识别速度太慢了,能不能不解码,就直接识别出视频中的运动目标?我当时是哑口无言滴,内心是复杂滴。哥也就是一个码砖的,设计大厦这种活,哥也做不来啊。。。。。。
后来我就到处找资料,发现H264视频编解码规范是在2003年就发布了第一版了,再瞅瞅ffmpeg里面的h264解码代码,最早也是2003年就开始写了,都过去十多年了,当时就立刻打消了自己写解码器的念头(莫错,知难而退了),人家ffmpeg都实现的这么好了,多翻翻里面的代码,然后自己再推演一下,摸清H264的解码脉络应该是绰绰有余了。事实证明,自己当时的想法图样图省泼了,NND,这ffmpeg里面的大部分核心代码都不是常人读得懂的,里面的注释是惜字如金,各种炫技的代码写法,我有读破代码的这功夫,早就自己写一个解码器了。
后来找来了《新一代视频压缩编码标准-H.264_AVC(第二版).pdf》,光看一遍都花了一两个月,主要是看不懂里面说的啥啊,现在再回头再看,里面说的啥基本上都能知道啥意思了。后来又找到了《T-REC-H.264-201704-S!!PDF-E.pdf》这个pdf,嗯,这个pdf才是H264的权威出处,问题是里面全是英文啊,哥的英文也就不说了(说了都是泪 /捂脸),那就慢慢啃吧,只要不是天书,还是有希望看懂的。
H264资料已经齐全了,接下来就是准备写代码了,网上我能找到的开源代码,也就是ffmpeg,x264,jm 这三个。这3个都是用C写的,那我就开始纠结了,用C++写好,还是用C写好,后来深思熟虑了一下,决定用C++,但是尽量保持里面的语法都是接近C的,禁止使用C++11,要把代码的主动权尽量掌握在自己手里,不要交给编译器。原计划三到六个月利用周末写完第一版,后来的实际情况是写了一年半(熬了无数个夜,发际线走了,啤酒肚来了)。
最后吐槽一下jm,里面的代码真是让人看了后抓狂。你有见过 imgpel *****imgUV_sub; 这种写法的变量?
二、进入正题:
H264编解码的整个过程基本上都是,解码残差 + 预测,这是整个解码流程的核心。下面列一下简单的解码步骤:
1、在H264中,所有图像都被分成一个一个16x16像素的正方形,这个正方形的名称叫做"宏块"(即macroblock)。宏块还可以再细分成:两个16x8矩形、两个8x16矩形、四个8x8正方形,这些比宏块小的块名字叫“子宏块”(即sub-macroblock)。宏块和子宏块的本质区别是:宏块的大小是固定死了的,永远是16x16大小,并且在一张图像中的分割方法是唯一的,而一个宏块中的子宏块就有很多种组合。这些组合就相当于构成了一幅H264图像的骨骼,骨架搭好了,就可以在上面敷上各种颜色的皮肤。另外一方面也说明了视频的原始分辨率都必须是16的倍数。
2、宏块又被进一步分成帧宏块(frame macroblock)和场宏块(field macoblock)(如图1),特别需要注意的是,当提到帧/场宏块时,需要弄清楚的是哪一种宏块:顶帧宏块(top frame macroblock)、底帧宏块(bottom frame macroblock)、顶场宏块(top field macroblock)、底场宏块(bottom field macroblock)。即一个16x32像素块,可以分成上下两个16x16的宏块对,如果这个16x32像素块的上面连续16行构成一个宏块,下面连续16行构成一个宏块,那么这两个宏块就叫“一个帧宏块对”(frame macroblock pair)。如果这个16x32像素块从第零行开始,将16个偶数行的像素取出来,构成一个宏块,然后将16个奇数行像素取出来,构成一个宏块,那么这两个宏块就叫“一个场宏块对”(field macroblock pair)。凡是出现“场”(field)这个字的地方,其本质代表的是摄像机的隔行扫描采样。所以,如果一幅图像全部都是场宏块对组成的话,所有的顶场宏块组成的图像叫做一个顶场图像,所有的底场宏块组成的图像叫做一个底场图像,即一个顶场加一个底场组成一帧图像。同样的道理,一帧图像可以拆分成一个顶场和一个底场。我一开始以为这个场和场宏块是同一个意思,直到后来摔了n个跟头后才明白,压根就不是同一个东西。所以,如果H264中没有场的话,一切都是那么简单。
如果H264的句法元素 slice_data->mb_field_decoding_flag == 1,那么就表示当前宏块是一个场宏块,那么接下来的问题就是这是一个顶场宏块呢,还是一个底场宏块?要回答这个问题,就需要知道H264各种宏块的扫描顺序。
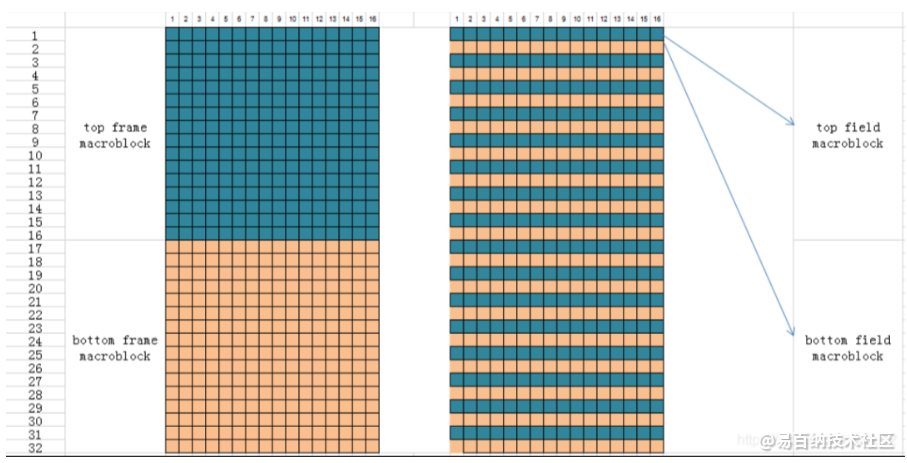
帧场宏块对
3、一幅图像的宏块划分好了后,接下来就是这些宏块的解码顺序了,H264中,每个宏块都有一个对应的CurrMbAddr正整数值,这个CurrMbAddr的值从0开始,后面的每个宏块依次加1。H264规定了扫描宏块的一个基本原则就是:从上到下,从左到右。比如上面提到的宏块对(图1),就是先解码顶宏块,再解码底宏块,而顶宏块的CurrMbAddr值都是偶数,底宏块的CurrMbAddr值都是奇数,本质就是,先解码一个16x32像素块,再解码该像素块右边紧挨着的16x32像素块(如图2)。
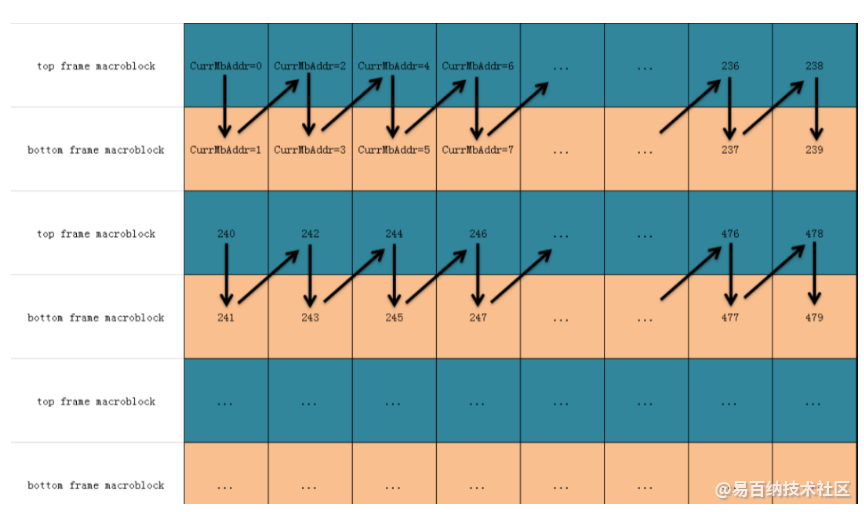
宏块对编解码扫描顺序
再比如一个16x16宏块被分成了16个4x4的子宏块,那么,这16个子宏块的扫描顺序就是如下图3所示:

4、对于H264的预测,说得直白一点就跟天气预报一样,从今天的天气情况,来预测一下明天下不下雨。H264的所有预测都是基于宏块预测的,就是说当前宏块的256个像素值或当前子宏块的像素值,都是根据它左边和上边已经解码完毕的宏块的相关句法元素值来预测得到的。为什么是左边和右边呢?因为根据从左到右,从上到下的原则,当前(子)宏块的左边和上边的相应(子)宏块都是已经解码完毕了的(对于图像最上面的第一行宏块来说,他们的上边宏块都是不存在的,这是在解码这些宏块之前就已经知道的事实,也可以理解成这些不存在的宏块都是已经解码完毕了的)。如图4所示,当前宏块用CurrMbAddr表示,他的左边和上边总共有4个宏块,分别是mbAddrA、mbAddrD、mbAddrB、mbAddrC。当然这些都是对于16x16宏块来说的,对于其他比如4x4、4x8、8x4、8x8、16x8、8x16尺寸的子宏块,获取它们的邻居宏块,H264中已经有整理好了的表格。对应于《T-REC-H.264-201704-S!!PDF-E.pdf》中的Table 6-3 – Specification of mbAddrN 和 Table 6-4 – Specification of mbAddrN and yM。

H264中很多语法元素的值,都会基于相邻宏块来预测,比如,要解码“量化后的残差”,如果当前宏块是帧内预测模式的宏块,并且是cavlc残差,就需要事先知道当前宏块残差中有多少个非零系数值(non_zero_count_coeff),而这个non_zero_count_coeff值,就是利用已经解码的相邻宏块mbAddrA、mbAddrD、mbAddrB、mbAddrC的non_zero_count_coeff值来预测得到的,大致意思就是取mbAddrA和mbAddrB相应的non_zero_count_coeff值的平均值,即 nC = ( nA + nB + 1 ) / 2;相应的计算公式见《T-REC-H.264-201704-S!!PDF-E.pdf》中的 9.2.1 小节。
又比如,P帧或B帧的运动矢量预测也会用到当前宏块的相邻宏块的相应语法元素值。总而言之,H264的精髓就是榨干相邻宏块的所有信息,来得到当前宏块的信息,从而减少编码后的比特数量(即降低码率)。
什么是残差?通俗的讲,就是图像编码前的真实像素值减去对应位置的预测值,得到的差就叫残差。那么什么又是“对应位置的预测值”?这个预测值,说到底就是上面讲的利用已经解码完毕的相邻宏块的像素值,按照相应的预测模式值对应的计算方法,计算出来的。最简单的计算方法就是取左边和上边宏块的像素的平均值。那么什么又是“相应的预测模式值”?这个值一般是由编码器设置好了的,并且编码到h264码流中了的(即rem_intra4x4_pred_mode语法元素的值)。如果码流中没有出现这个语法元素,那么这个rem_intra4x4_pred_mode的值就又需要利用已经解码完毕的相邻宏块的rem_intra4x4_pred_mode值来计算得到,一般是取mbAddrA和mbAddrB中对应的rem_intra4x4_pred_mode值最小的那个值。
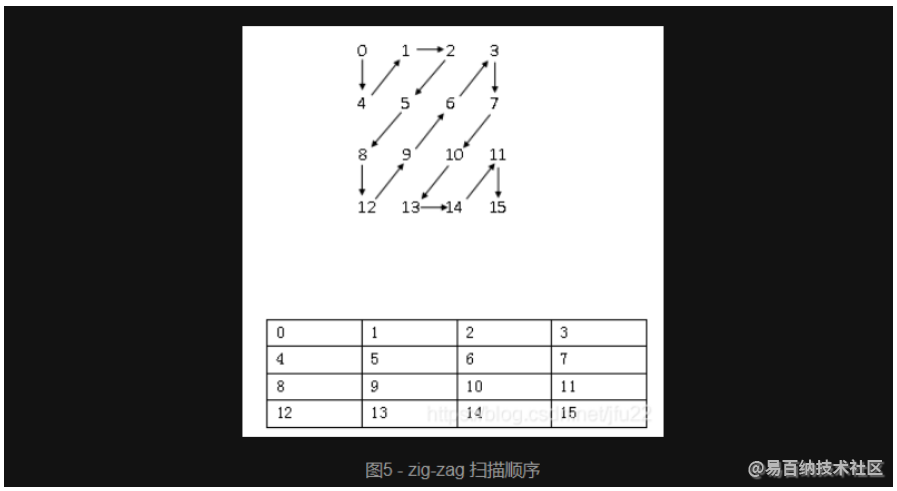
5、cavlc/cabac残差解码完后,就需要进行DCT反变换,而进行DCT反变换之前,需要反量化,而进行反量化之前,需要将依据解码完毕的残差值进行一次重新排列,需要重新排列的原因是,编码器编码时,将残差按 zig-zag 扫描(图5,是4x4子宏块的16个残差值的扫描顺序) 顺序排列了一遍,所以解码时,需要反向扫描回去(另外,ffmpeg的官网logo貌似就是zi-zag图形)。
反向扫描完了后就是反量化,为啥要反量化呢?因为残差经过DCT变换后的值范围太大了,或者为了省码流,需要进行类似四舍五入的操作,将某个范围内的值,全部映射到同一个值,这个过程就会损失掉一部分图像信息(即有损压缩),有的视频解码后画面很模糊,就可能跟这个量化得过了头有关。量化的本质就是残差DCT变换后的值除以了一个整数值,而这个整数值就是量化参数,这个量化参数在H264中,有专门的表格来存储的(见《T-REC-H.264-201704-S!!PDF-E.pdf》中的 8.5.9 小节)。
反量化完了后,就是DCT反变换。这个反变换类似快速傅里叶变换(FFT)一样,有快速算法,类似蝶形运算。而蝶形运算的本质,即按照标准的变换定义,计算每一个变换后的值,都会重复进行某一个局部的加法和乘法运算,大可不必每次都算一次,可以用空间换时间的办法,把这些大量重复计算的地方用一个中间变量保存起来,后面就直接用中间变量计算了。
/*
H.264 _ MPEG-4 Part 10 White Paper.pdf Page15
Equation 2-3:
Y = Cf X XfT ⊗ Ef
/ \ / \ / \
| M0 | | 1 1 1 1/2 | | m0 |
| M1 | = | 1 1/2 -1 -1 | | m1 |
| M2 | | 1 -1/2 -1 1 | | m2 |
| M3 | | 1 -1 1 -1/2 | | m3 |
\ / \ / \ /
M0 = (m0 + m2) + (m1 + m3*(1/2))
M1 = (m0 - m2) + (m1*(1/2) - m3)
M2 = (m0 - m2) - (m1*(1/2) - m3)
M3 = (m0 + m2) - (m1 + m3*(1/2))
蝶形运算符:
m0 o---o---o (m0 + m2)=s02 o----o-----o (m0 + m2) + (m1 + m3*(1/2)) = M0 = s02 + s13
\ / \ /
X \ /
/ \ X
m2 o---o---o (m0 - m2)=d02 o---o--/-\--o (m0 - m2) + (m1*(1/2) - m3) = M1 = d02 + d13
\/ \/
/\ /\
m1 o---o---o (m1 + m3*(1/2))=s13 o---o--\-/--o (m0 + m2) - (m1 + m3*(1/2)) = M3 = s02 - s13
\ / X
X / \
/ \ / \
m3 o---o---o (m1*(1/2) - m3)=d13 o----o-----o (m0 - m2) - (m1*(1/2) - m3) = M2 = d02 - d13
*/6、DCT反变换后的值,再加上预测得到的像素值,结果就是环路滤波前的帧像素值,那么什么是“预测得到的像素值”?这里得分两种情况,第一种情况就是宏块的帧内预测(Intra prediction)得到的像素值,第二种情况是宏块的帧间预测(Inter prediction)得到的像素值。这里所谓的预测,其本质还是前面说的利用已经解码完毕的相邻宏块的像素值得到的。宏块的帧内预测比较简单,直接利用当前模块的mbAddrA、mbAddrB的像素值来预测计算得到。而对于帧间预测,就需要添加额外的信息来找到相应的用于预测的宏块(mbAddrForPred),这个mbAddrForPred一般不在本帧中,而是在本帧的参考帧(用 refIdxL0 或 refIdxL1 来表示)中。那么什么又是“本帧的参考帧”?这个参考帧其实就是指前面已经解码完毕的帧/场(注意:是帧或场,不是宏块),那么解码器又咋个晓得参考帧是前面解码完毕的哪一帧呢?这个就是一个比较复杂的问题了,通俗的来讲,要得到refIdxL0或refIdxL1,编码器可能已经将这个值编码到码流中了,解码相应的语法元素ref_idx_l0[]就可以得到,那么如果码流中没出现这个语法元素呢?还是老办法,利用相邻的宏块来预测得到这个语法元素值,因为一般来讲,相邻宏块的参考帧和当前宏块的参考帧都是同一帧,那么就没必要将这个值重复编码到码流中了。
找到当前待解码宏块的参考帧后,下一步就需要确定,用于预测的宏块(mbAddrForPred)在参考帧中的哪一个位置,要找到这个位置,就要先找到当前帧的当前宏块,在参考帧中对应的位置,然后再基于这个位置,加上一个偏移量,得到的结果位置就是mbAddrForPred。那么这个“偏移量”是哪里来的呢?这个偏移量就叫运动矢量,是一个二维矢量Mv0[0,1],分别表示x横向偏移量和y纵向偏移。这个运动矢量,同样可能是由编码器编到码流里面了,解码mvd_l0[]语法元素就可以得到,如果码流中没有出现这个语法元素,那就默认为0。同样的,这个运动矢量还是需要再利用当前宏块相邻宏块预测得到(即mvpL0[]),那么最终的运动矢量就是,mvL0[0,1] = mvpL0[0,1] + mvd_l0[0,1],如果预测模式是双向预测的B宏块,还需要找到参考帧 refIdxL1,计算出mvL1[0,1] = mvpL1[0,1] + mvd_l1[0,1]。
将当前宏块的每一个位置,在mbAddrForPred中,找到对应位置的像素值,然后利用这个像素值以及周围“井”字型的像素值,共20个像素值,进行四分之一像素插值,最后相应位置的插值结果就是上面说的“预测得到的像素值”,如果是双向预测,会得到两个这样的预测值,一般情况下,是取这两个值的平均值,做为最终的预测值。
//8.4.2.2.1 Luma sample interpolation process
//亮度像素值插值过程
//Figure 8-4
//
// 口 口 A aa B 口 口
// 口 口 C bb D 口 口
// E F G a b c H I J
// d e f g
// cc dd h i j k m ee ff
// n p q r
// K L M s N P Q
// 口 口 R gg S 口 口
// 口 口 T hh U 口 口7、DCT反变换后的值,再加上预测得到的像素值,结果就是环路滤波前的帧像素值,那么什么是“环路滤波”?因H264中人为划分宏块,导致解码后,会出现块效应,就是解码后的图像看起来是一块一块的,需要将这些块与块之间的边界做一次平滑滤波(环路滤波)。平滑滤波后的整个帧的像素值,就是最终的像素值。
8、一帧图像解码完了后,只有显示到屏幕上,才能显示出解码器的价值。有两种方案,一种是将解码后的每一帧数据保存到磁盘。另一种是直接在播放器中播放出来。这两种方案,都有各自的使用场合。需要说明的是,H264解码出来的一般都是YUV420P格式的像素值,像 BMP/PNG/JPG以及视频播放器,需要的是RGB值,所以还需要先将YUV数据转换成RGB值。
下面是我专门写的一个SDH264Player播放器截图,目的是方便研究H264的解码过程。
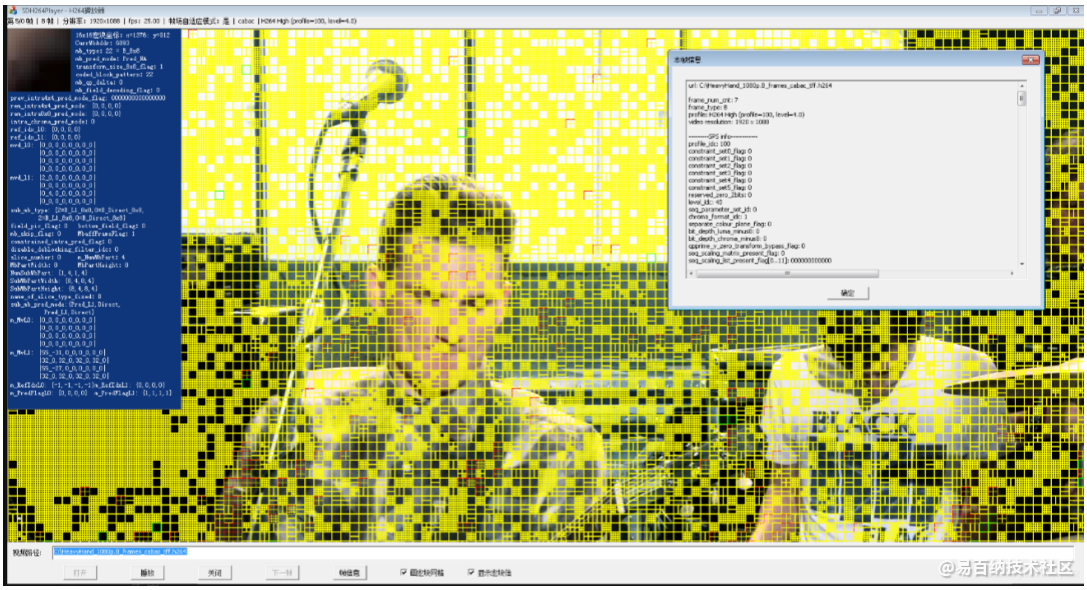
三、尾声:
- 上面只是简单罗列了一下H264的解码基本步骤,更复杂的得去啃相关的书籍了。
- 另外需要纠正的是,以前我一直以为B帧是不能做参考的,现在看来这个认知是错误的。事实上,据我看到的一些码流视频,I帧,P帧,B帧都可能被编码器用作参考帧。
- 还有一点,P帧,B帧,里面的宏块是可能包含帧内预测宏块的。所以,对于P帧,和B帧的定义,其实还需要更深一层的理解。
- 在h264_video_decoder_demo工程中,主要的精力放在H264的完整解码流程,重心没放在解码速度和内存控制上,因此,还是有很多的优化空间的,并且目前我自己测试的H264裸码流视频数量也不多,顶多十多个,bug是存在的,后续有时间再慢慢琢磨要不要优化一下。这些优化工作够掉很多头发的。
- 对于h264_video_decoder_demo工程的解码速度的优化,可以参照ffmpeg的方法,在ffmpeg中大量使用了Intel的MMX和SSE指令集,即单指令多数据指令集。相当于一条指令开了多个线程来并行解码,解码速度当然是单指令单数据指令集的4到8倍。这种技术是很诱人的。英伟达的显卡貌似就是这种技术的集大成者。
- 对于h264_video_decoder_demo工程使用的内存过高的优化,在编写过程中,为了更加专注解码过程本身(其实是想偷懒),我基本上是用32位int来定义一个变量,这样的话,像有很多H264语法元素,只有0和1两个取值,只需要一个比特位就够了。另外,每个宏块基本上有很多个256个元素的数组,这些数组元素的取值范围本身只在-126到127范围内,所以只需要一个char型变量就足够了,内存可以降低三分之一。
- 如果要写一个工业级的H264解码器,可以把ffmpeg中关于H264的大部分核心代码和设计框架抄过来,自己再改一下就可以了。不过这个工作量,想想就够刺激滴。
- 本来想到H265来自于H264,既然H264解码器都能写出来,那么写一个H265解码器还不是月月钟的事,后来大致瞄了一下《T-REC-H.265-201802-I!!PDF-E.pdf》这个文档,渐渐打消了这个念头,咱还想多留几缕头发。另一方面,从我目前观察的ffmpeg的H265解码性能,是不如H264的。
- 前面提到的 “是否可以不解码H264码流,就能知道码流里面有哪些运动目标吗?” 目前我的回答是,理论上是可以的,但这个理论上的可以,其实就相当于另外一种形式的解码。所以最终的理想方案是,如果能在摄像头编码时,就把视频中的运动物体信息编码到码流里面,这才一劳永逸的事情。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:1486次2023-10-30 15:15:38
-
浏览量:1420次2023-10-23 17:56:00
-
浏览量:4932次2021-08-26 14:50:36
-
浏览量:5235次2021-04-27 16:33:22
-
浏览量:6077次2021-04-27 16:33:54
-
浏览量:2892次2024-01-26 15:15:36
-
浏览量:1410次2023-06-30 10:11:29
-
浏览量:1421次2023-06-30 09:18:17
-
浏览量:1302次2023-06-12 14:34:57
-
浏览量:3661次2018-05-07 16:22:35
-
浏览量:2189次2023-06-12 14:34:40
-
浏览量:3439次2024-02-27 17:03:43
-
浏览量:6620次2020-08-20 14:18:11
-
浏览量:2866次2020-05-22 19:32:20
-
浏览量:2385次2023-12-26 16:33:04
-
浏览量:16356次2023-12-27 20:28:48
-
浏览量:2999次2023-11-01 10:56:09
-
浏览量:3726次2019-11-09 19:10:44
-
2023-06-12 14:35:32




-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖
txp

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
