

视频编解码——视频编解码器工作原理

文章目录
视频编码器基础认知
什么是视频编解码器
简单来说就是用于压缩或解压数字视频的软件或硬件
编码是信息从一种形式或格式转换为另一种形式的过程,解码是编码的反向。
适用于视频
- 编码是将视频、音频的原始格式的文件通过压缩技术转换成另一种格式(视频如h.264,h.265,m-jpeg等)。
- 解码是编码的反向过程。应用中,一般是将h.264,h.265格式数据解码成如YUV格式裸流交给显示器显示。
为什么需要视屏编解码器
需要在有限的带宽或存储空间下提升视频的质量。
简单计算一下,30帧,每像素24bit,分辨率480x240的视频,需要的带宽约为82.944Mbps。电视或互联网提供 HD/FullHD/4K 只能靠视频编解码器。
视频编码器与数字视频容器
初学者一个常见的错误是混淆数字视频编解码器和数字视频容器。
我们可以将容器视为包含视频(也很可能包含音频)元数据的包装格式,压缩过的视频可以看成是它承载的内容。
容器格式也被称为封装格式允许将多个数据流嵌入到单个文件中。
例如:可以放很多.txt的压缩包ZIP格式,和多媒体的播放格式如MP4和AVI。
通常,视频文件的格式定义其视频容器。例如,文件 video.mp4 可能是 MPEG-4 Part 14 容器,一个叫 video.mkv 的文件可能是 matroska。我们可以使用 ffmpeg 或 mediainfo 来完全确定编解码器和容器格式。
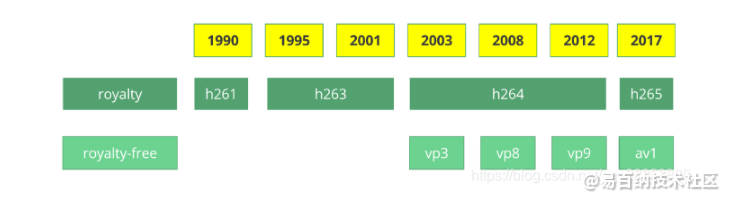
视频编码标准的历史
在我们跳进通用编解码器内部工作之前,让我们回头了解一些旧的视频编解码器。
视频编解码器 H.261 诞生在 1990(技术上是 1988),被设计为以 64 kbit/s 的数据速率工作。它已经使用如色度子采样、宏块,等等理念。在 1995 年,H.263 视频编解码器标准被发布,并继续延续到 2001 年。
在 2003 年 H.264/AVC 的第一版被完成。在同一年,一家叫做 TrueMotion 的公司发布了他们的免版税有损视频压缩的视频编解码器,称为 VP3。在 2008 年,Google 收购了这家公司,在同一年发布 VP8。在 2012 年 12 月,Google 发布了 VP9,市面上大约有 3/4 的浏览器(包括手机)支持。
AV1 是由 Google, Mozilla, Microsoft, Amazon, Netflix, AMD, ARM, NVidia, Intel, Cisco 等公司组成的开放媒体联盟(AOMedia)设计的一种新的视频编解码器,免版税,开源。第一版 0.1.0 参考编解码器发布于 2016 年 4 月 7 号。
通用编解码器
我们接下来要介绍通用视频编解码器背后的主要机制,大多数概念都很实用,并被现代编解码器如 VP9, AV1 和 HEVC 使用。
需要注意:我们将简化许多内容。有时我们会使用真实的例子(主要是 H.264)来演示技术。
1、图片分区
第一步是将帧分成几个分区,子分区甚至更多。
为何要分区?
有许多原因,比如,当我们分割图片时,我们可以更精确的处理预测,在微小移动的部分使用较小的分区,而在静态背景上使用较大的分区。
通常,编解码器将这些分区组织成切片(slices )或条带(tiles),宏(或编码树单元)和许多子分区。
这些分区的最大大小有所不同,HEVC 设置成 64x64,而 AVC 使用 16x16,但子分区可以达到 4x4 的大小。
回顾帧的分类。你也可以把这些概念应用到块,因此我们可以有 I 切片,B 切片,I 宏块等等。
查看分区
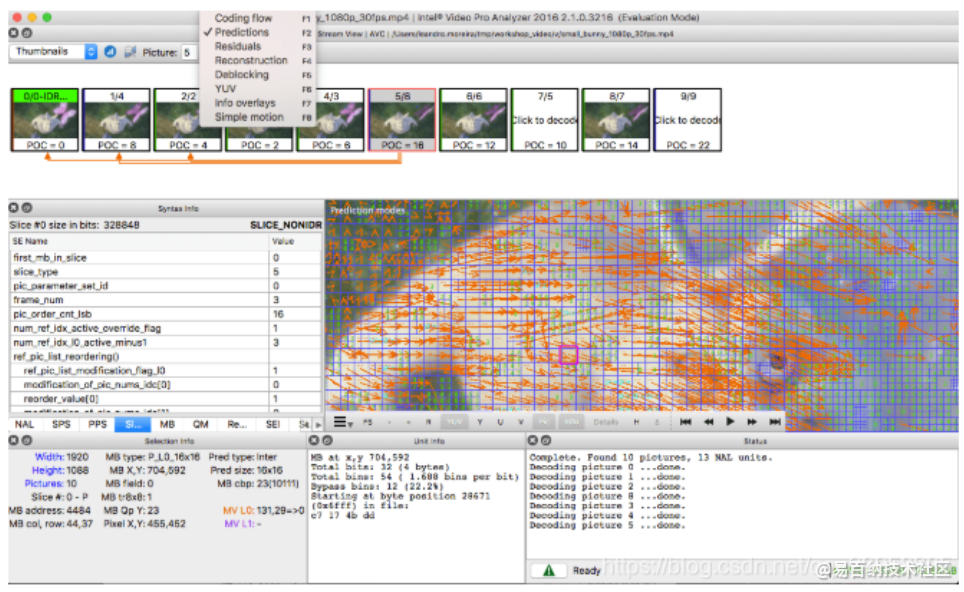
我们也可以使用 Intel® Video Pro Analyzer(需要付费,但也有只能查看前 10 帧的免费试用版)。
2、预测
一旦我们有了分区,就可以在它们之上做出预测。
视频编解码——消除视频冗余的方法及原理
- 对于帧间预测,我们需要发送运动向量和残差
- 对于帧内预测,我们需要发送预测方向和残差
3、转换
在我们得到残差块(预测分区-真实分区)之后,我们可以用一种方式变换它,这样我们就知道哪些像素我们应该丢弃,还依然能保持整体质量。这个确切的行为有几种变换方式。
尽管有其它的变换方式,但我们重点关注离散余弦变换(DCT)。DCT 的主要功能有:
- 将像素块转换为相同大小的频率系数块。
- 压缩能量,更容易消除空间冗余。
- 可逆的,也意味着你可以还原回像素。
2017 年 2 月 2 号,F. M. Bayer 和 R. J. Cintra 发表了他们的论文:图像压缩的 DCT 类变换只需要 14 个加法。
如果你不理解每个要点的好处,不用担心,我们会尝试进行一些实验,以便从中看到真正的价值。
我们来看下面的像素块(8x8):
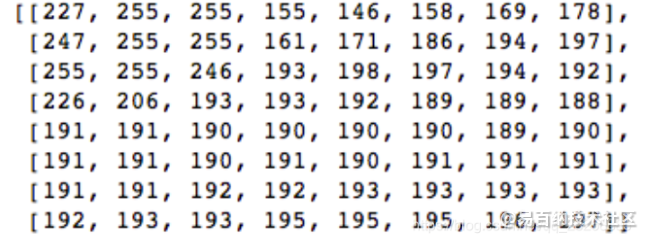
下面是其渲染的块图像(8x8):

当我们对这个像素块应用 DCT 时, 得到如下系数块(8x8):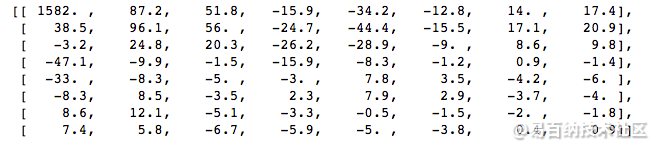
接着如果我们渲染这个系数块,就会得到这张图片: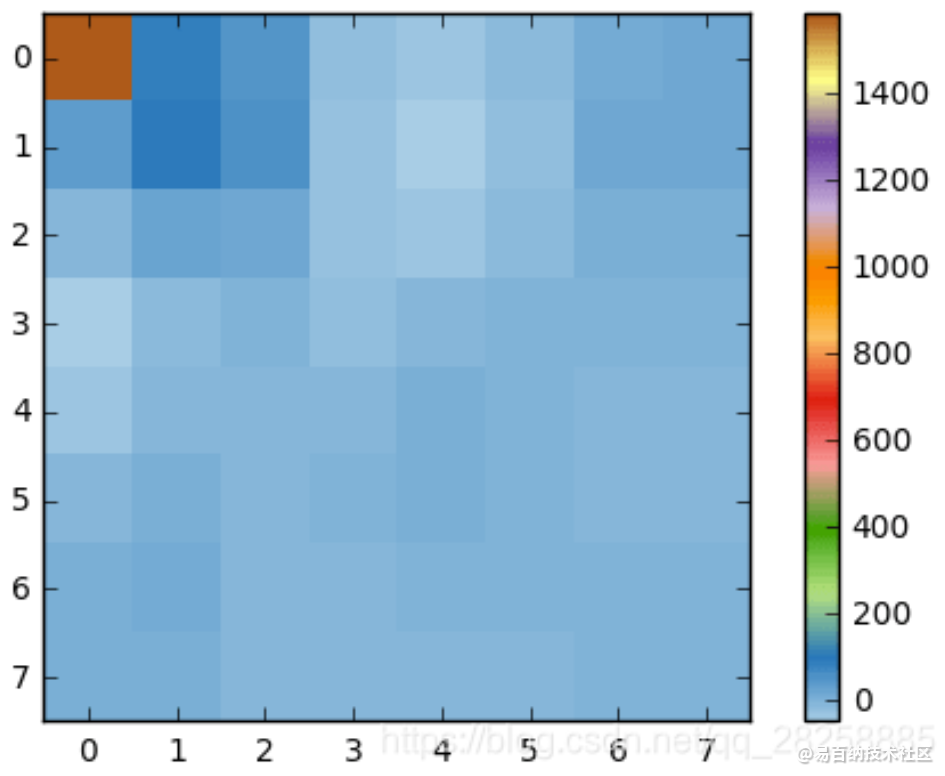
如你所见它看起来完全不像原图像,我们可能会注意到第一个系数与其它系数非常不同。第一个系数被称为直流分量,代表了输入数组中的所有样本,有点类似于平均值。
这个系数块有一个有趣的属性:高频部分和低频部分是分离的。
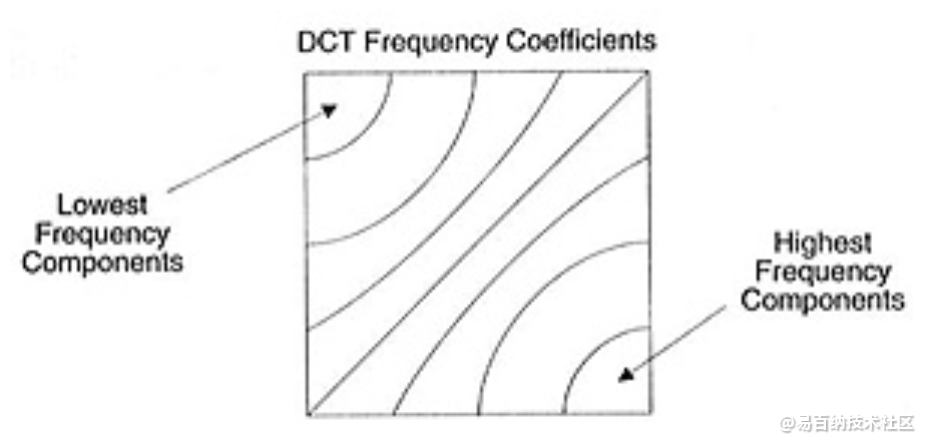
在一张图像中,大多数能量会集中在低频部分,所以如果我们将图像转换成频率系数,并丢掉高频系数,我们就能减少描述图像所需的数据量,而不会牺牲太多的图像质量。
频率是指信号变化的速度。
让我们通过实验学习这点,我们将使用 DCT 把原始图像转换为频率(系数块),然后丢掉最不重要的系数。
首先,我们将它转换为其频域。
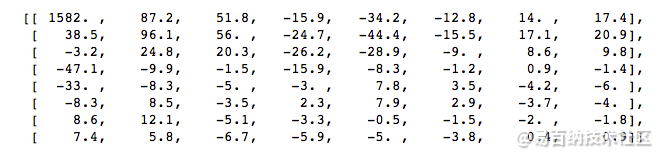
然后我们丢弃部分(67%)系数,主要是它的右下角部分。

然后我们从丢弃的系数块重构图像(记住,这需要可逆),并与原始图像相比较。
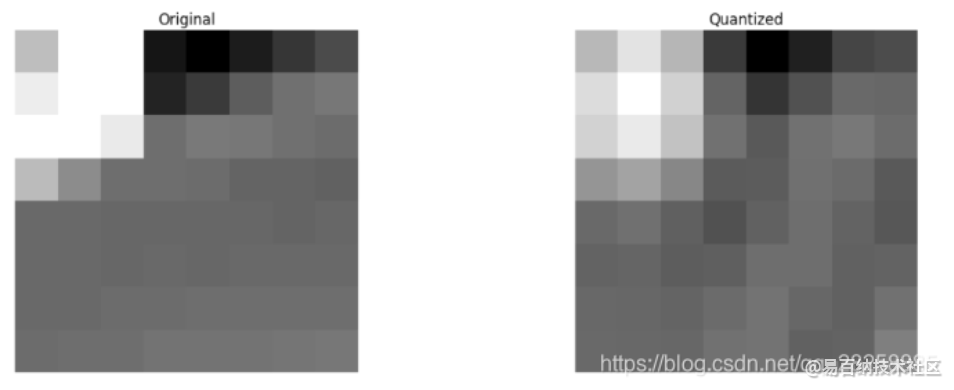
如我们所见它酷似原始图像,但它引入了许多与原来的不同,我们丢弃了67.1875%,但我们仍然得到至少类似于原来的东西。我们可以更加智能的丢弃系数去得到更好的图像质量,但这是下一个主题。
使用全部像素形成每个系数
重要的是要注意,每个系数并不直接映射到单个像素,但它是所有像素的加权和。这个神奇的图形展示了如何计算出第一和第二个系数,使用每个唯一的索引做权重。

4、量化
当我们丢弃一些系数时,在最后一步(变换),我们做了一些形式的量化。这一步,我们选择性地剔除信息(有损部分)或者简单来说,我们将量化系数以实现压缩。
我们如何量化一个系数块?一个简单的方法是均匀量化,我们取一个块并将其除以单个的值(10),并舍入值。
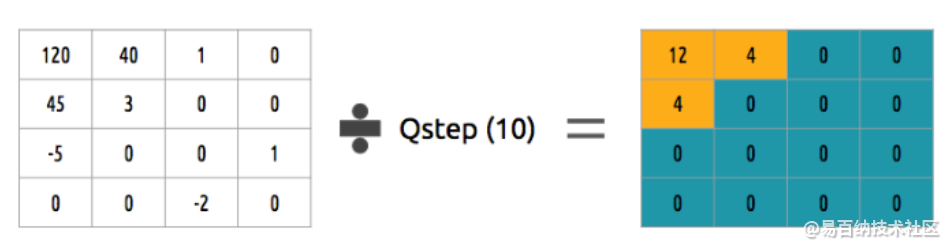
我们如何逆转(重新量化)这个系数块?我们可以通过乘以我们先前除以的相同的值(10)来做到。

这不是最好的方法,因为它没有考虑到每个系数的重要性,我们可以使用一个量化矩阵来代替单个值,这个矩阵可以利用 DCT 的属性,多量化右下部,而少(量化)左上部,JPEG 使用了类似的方法,你可以通过查看源码看看这个矩阵。
5、熵编码
在我们量化数据(图像块/切片/帧)之后,我们仍然可以以无损的方式来压缩它。有许多方法(算法)可用来压缩数据。我们将简单体验其中几个,你可以阅读这本很棒的书去深入理解:Understanding Compression: Data Compression for Modern Developers。
VLC编码
让我们假设我们有一个符号流:a, e, r 和 t,它们的概率(从0到1)由下表所示:
我们可以分配不同的二进制码,(最好是)小的码给最可能(出现的字符),大些的码给最少可能(出现的字符)。
让我们压缩 eat 流,假设我们为每个字符花费 8 bit,在没有做任何压缩时我们将花费 24 bit。但是在这种情况下,我们使用各自的代码来替换每个字符,我们就能节省空间。
第一步是编码字符 e 为 10,第二个字符是 a,追加(不是数学加法)后是 [10][0],最后是第三个字符 t,最终组成已压缩的比特流 [10][0][1110] 或 1001110,这只需 7 bit(比原来的空间少 3.4 倍)。
请注意每个代码必须是唯一的前缀码,Huffman 能帮你找到这些数字。虽然它有一些问题,但是视频编解码器仍然提供该方法,它也是很多应用程序的压缩算法。
编码器和解码器都必须知道这个(包含编码的)字符表,因此,你也需要传送这个表。
算术编码
让我们假设我们有一个符号流:a, e, r, s 和 t,它们的概率由下表所示。

考虑到这个表,我们可以构建一个区间,区间包含了所有可能的字符,字符按出现概率排序。

让我们编码 eat 流,我们选择第一个字符 e 位于 0.3 到 0.6 (但不包括 0.6)的子区间,我们选择这个子区间,按照之前同等的比例再次分割。

让我们继续编码我们的流 eat,现在使第二个 a 字符位于 0.3 到 0.39 的区间里,接着再次用同样的方法编码最后的字符 t,得到最后的子区间 0.354 到 0.372。
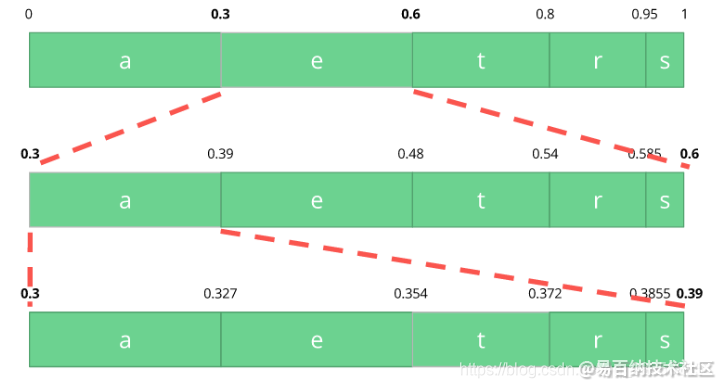
我们只需从最后的子区间 0.354 到 0.372 里选择一个数,让我们选择 0.36,不过我们可以选择这个子区间里的任何数。仅靠这个数,我们将可以恢复原始流 eat。就像我们在区间的区间里画了一根线来编码我们的流。
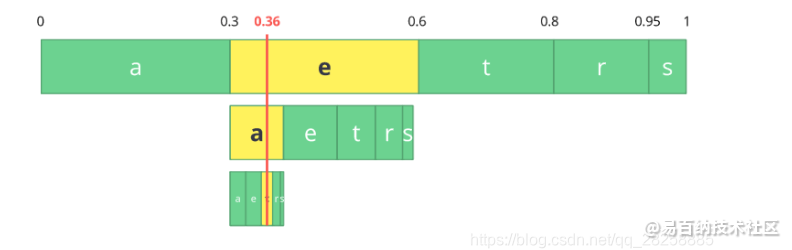
反向过程(又名解码)一样简单,用数字 0.36 和我们原始区间,我们可以进行同样的操作,不过现在是使用这个数字来还原被编码的流。
在第一个区间,我们发现数字落入了一个子区间,因此,这个子区间是我们的第一个字符,现在我们再次切分这个子区间,像之前一样做同样的过程。我们会注意到 0.36 落入了 a 的区间,然后我们重复这一过程直到得到最后一个字符 t(形成我们原始编码过的流 eat)。
编码器和解码器都必须知道字符概率表,因此,你也需要传送这个表。
非常巧妙,不是吗?人们能想出这样的解决方案实在是太聪明了,一些视频编解码器使用这项技术(或至少提供这一选择)。
关于无损压缩量化比特流的办法,这篇文章无疑缺少了很多细节、原因、权衡等等。作为一个开发者你应该学习更多。刚入门视频编码的人可以尝试使用不同的熵编码算法,如ANS。
6、比特流格式
完成所有这些步之后,我们需要将压缩过的帧和内容打包进去。需要明确告知解码器编码定义,如颜色深度,颜色空间,分辨率,预测信息(运动向量,帧内预测方向),配置,层级,帧率,帧类型,帧号等等更多信息。
- 译注:原文为 profile 和 level,没有通用的译名
接下来简单地学习 H.264 比特流。第一步是生成一个小的 H.264* 比特流,可以用 ffmpeg 来做。
./s/ffmpeg -i /files/i/minimal.png -pix_fmt yuv420p /files/v/minimal_yuv420.h264
- ffmpeg 默认将所有参数添加为 SEI NAL
这个命令会使用下面的图片作为帧,生成一个具有单个帧,64x64 和颜色空间为 yuv420 的原始 h264 比特流。

H.264 比特流
AVC (H.264) 标准规定信息将在宏帧(网络概念上的)内传输,称为 NAL(网络抽象层)。NAL 的主要目标是提供“网络友好”的视频呈现方式,该标准必须适用于电视(基于流),互联网(基于数据包)等。

同步标记用来定义 NAL 单元的边界。每个同步标记的值固定为 0x00 0x00 0x01 ,最开头的标记例外,它的值是 0x00 0x00 0x00 0x01 。如果我们在生成的 h264 比特流上运行 hexdump,我们可以在文件的开头识别至少三个 NAL。
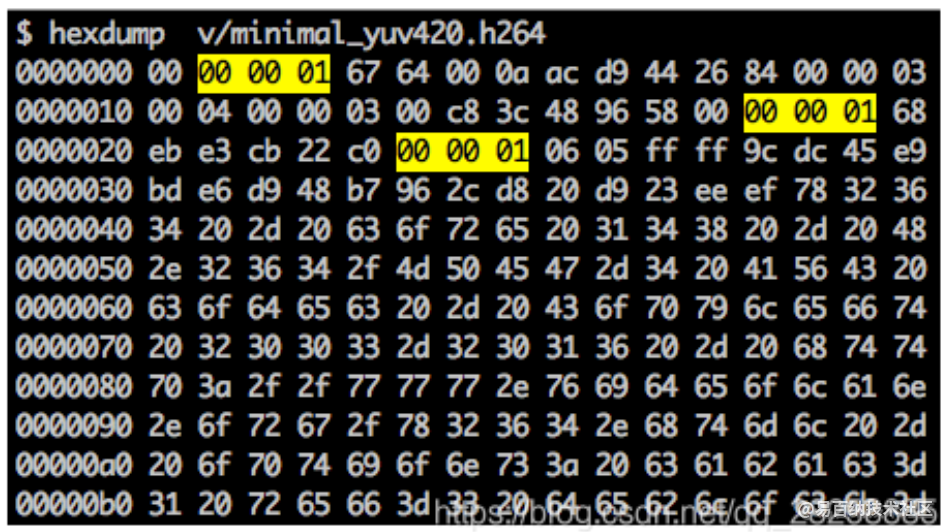
我们之前说过,解码器需要知道不仅仅是图片数据,还有视频的详细信息,如:帧、颜色、使用的参数等。每个 NAL 的第一位定义了其分类和类型。
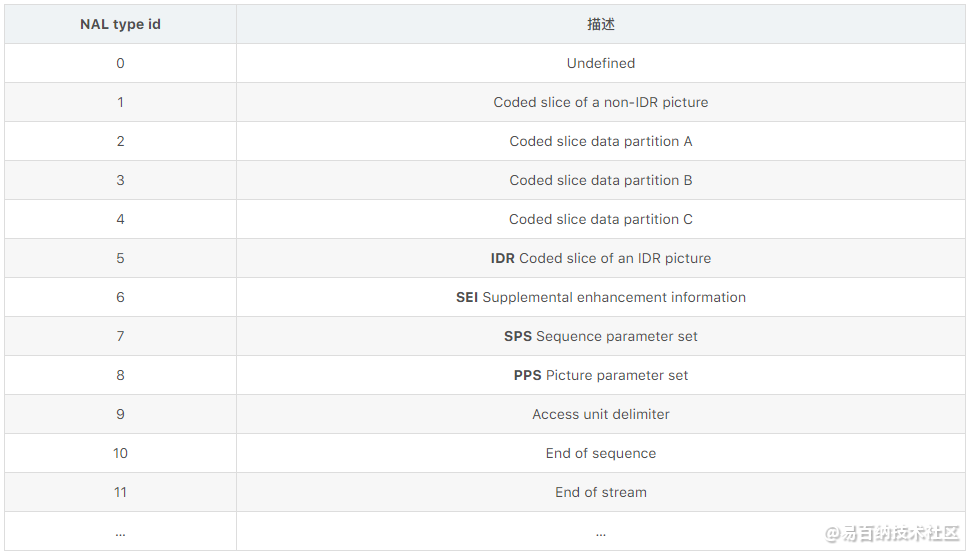
通常,比特流的第一个 NAL 是 SPS,这个类型的 NAL 负责传达通用编码参数,如配置,层级,分辨率等。
如果我们跳过第一个同步标记,就可以通过解码第一个字节来了解第一个 NAL 的类型。
例如同步标记之后的第一个字节是 01100111,第一位(0)是 forbidden_zero_bit 字段,接下来的两位(11)告诉我们是 nal_ref_idc 字段,其表示该 NAL 是否是参考字段,其余 5 位(00111)告诉我们是 nal_unit_type 字段,在这个例子里是 NAL 单元 SPS (7)。
SPS NAL 的第 2 位 (binary=01100100, hex=0x64, dec=100) 是 profile_idc 字段,显示编码器使用的配置,在这个例子里,我们使用受限高配置,一种没有 B(双向预测) 切片支持的高配置。
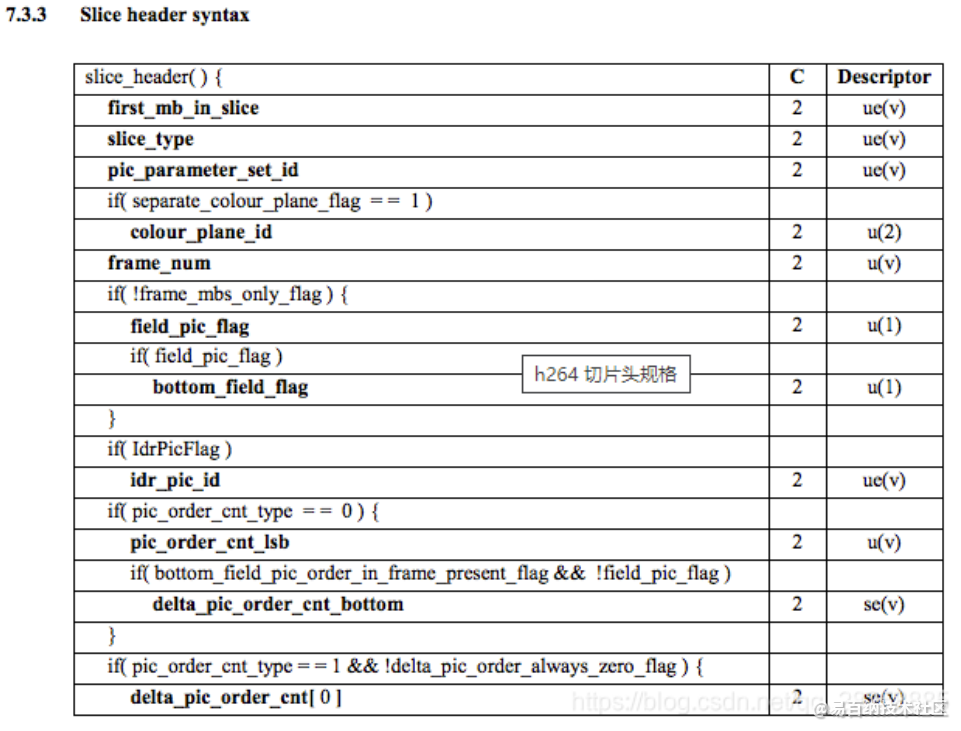
当我们阅读 SPS NAL 的 H.264 比特流规范时,会为参数名称,分类和描述找到许多值,例如,看看字段 pic_width_in_mbs_minus_1 和 pic_height_in_map_units_minus_1。

ue(v): 无符号整形 Exp-Golomb-coded
如果我们对这些字段的值进行一些计算,将最终得出分辨率。我们可以使用值为 119( (119 + 1) macroblock_size = 120 16 = 1920)的 pic_width_in_mbs_minus_1 表示 1920 x 1080,再次为了减少空间,我们使用 119 来代替编码 1920。
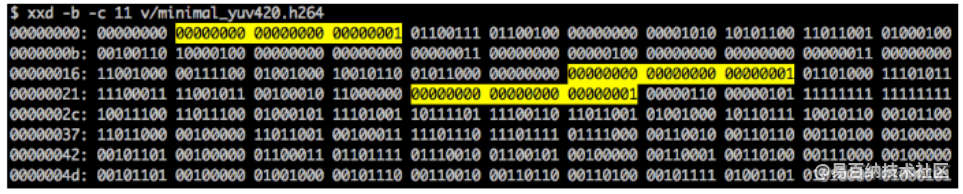
如果我们再次使用二进制视图检查我们创建的视频 (ex: xxd -b -c 11 v/minimal_yuv420.h264),可以跳到帧自身上一个 NAL。
我们可以看到最开始的 6 个字节:01100101 10001000 10000100 00000000 00100001 11111111。我们已经知道第一个字节告诉我们 NAL 的类型,在这个例子里, (00101) 是 IDR 切片 (5),可以进一步检查它:
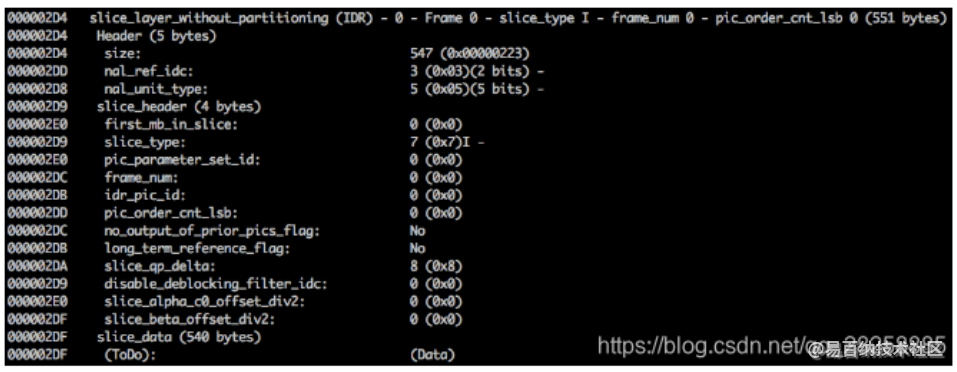
对照规范,我们能解码切片的类型(slice_type),帧号(frame_num)等重要字段。
为了获得一些字段(ue(v), me(v), se(v) 或 te(v))的值,我们需要称为 Exponential-Golomb 的特定解码器来解码它。当存在很多默认值时,这个方法编码变量值特别高效。
这个视频里 slice_type 和 frame_num 的值是 7(I 切片)和 0(第一帧)
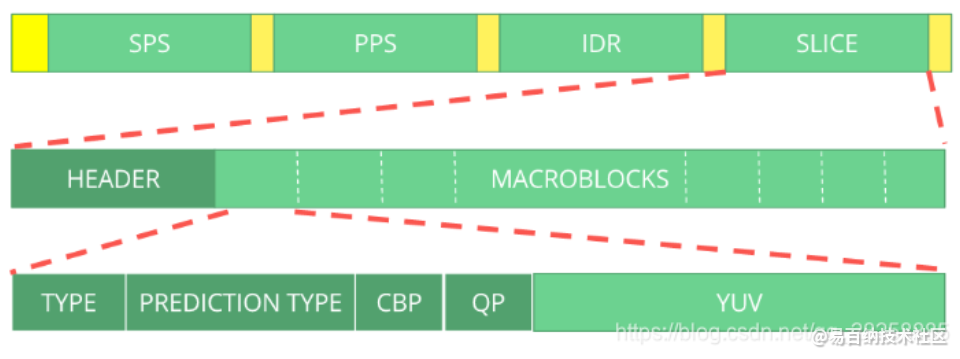
我们可以将比特流视为一个协议,如果你想学习更多关于比特流的内容,请参考 ITU H.264 规范。这个宏观图展示了图片数据(压缩过的 YUV)所在的位置。
我们可以探究其它比特流,如 VP9 比特流,H.265(HEVC)或是我们的新朋友 AV1 比特流,他们很相似吗?不,但只要学习了其中之一,学习其他的就简单多了。
检查H.264比特流
我们可以生成一个单帧视频,使用 mediainfo 检查它的 H.264 比特流。事实上,你甚至可以查看解析 h264(AVC) 视频流的源代码。
我们也可使用 Intel® Video Pro Analyzer,需要付费,但也有只能查看前 10 帧的免费试用版,这已经够达成学习目的了。
总结
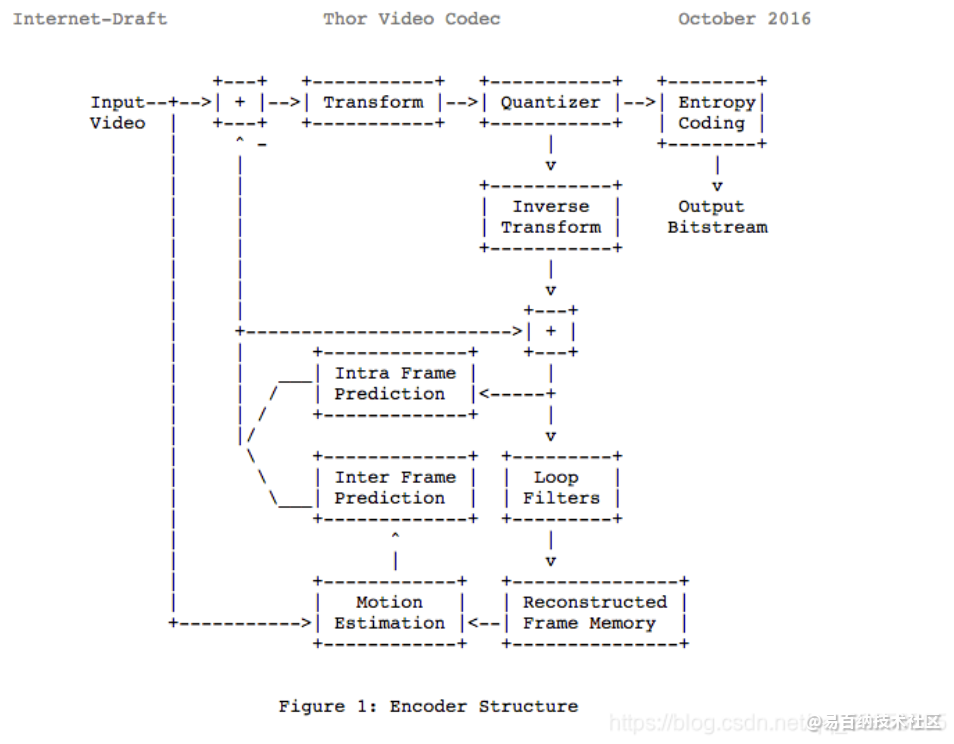
我们可以看到我们学了许多使用相同模型的现代编解码器。事实上,让我们看看 Thor 视频编解码器框图,它包含所有我们学过的步骤。你现在应该能更好地理解数字视频领域内的创新和论文。
之前我们计算过我们需要 139GB 来保存一个一小时,720p 分辨率和30fps的视频文件,如果我们使用在这里学过的技术,如帧间和帧内预测,转换,量化,熵编码和其它我们能实现——假设我们每像素花费 0.031 bit——同样观感质量的视频,对比 139GB 的存储,只需 367.82MB。
使用的视频是每像素使用 0.031 bit。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:2807次2020-01-07 10:55:38
-
浏览量:3657次2018-05-07 16:22:35
-
浏览量:2878次2020-08-17 11:44:38
-
浏览量:4869次2022-03-24 09:00:18
-
浏览量:3263次2020-08-26 17:38:24
-
浏览量:5314次2021-09-09 13:48:45
-
浏览量:2468次2023-11-01 11:26:42
-
浏览量:6612次2020-08-20 14:18:11
-
浏览量:3434次2024-02-27 17:03:43
-
浏览量:4639次2023-11-17 09:00:06
-
浏览量:4613次2020-08-26 17:39:57
-
浏览量:5233次2021-04-27 16:33:22
-
浏览量:3713次2020-08-10 09:24:28
-
浏览量:3250次2020-08-12 09:32:32
-
浏览量:1483次2023-10-30 15:15:38
-
浏览量:2968次2023-10-24 18:27:46
-
浏览量:3838次2021-07-13 15:22:50
-
浏览量:3724次2019-11-09 19:10:44
-
浏览量:5097次2021-12-10 20:21:00









-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

一休摸鱼

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
