

目标检测:如何有效实现YOLOv8

本文是一篇实用指南,介绍了如何使用命令行界面和Python来对图像、视频和实时网络摄像头中的物体进行检测。
介绍
目标检测是计算机视觉的一个子领域,主要涉及在图像或视频中以一定的置信度识别和定位物体。识别出的物体通常带有一个边界框,提供了关于物体在场景中的性质和位置的信息。
自2015年YOLO(You Only Look Once)问世以来,它的系统以惊人的准确性和速度实现了实时目标检测,震惊了计算机视觉领域。自那时以来,YOLO已经进行了多次改进,提高了预测准确性和效率,最终推出了最新的成员:Ultralytics的YOLOv8。
YOLOv8有五个版本:nano(n)、small(s)、medium(m)、large(l)和extra large(x)。它们的改进分别可以通过它们在COCO val2017数据集上的平均精度(mAP)和延迟进行评估。

与以前的版本相比,YOLOv8不仅更快、更准确,而且实现这一性能所需的参数更少,而且还配备了直观易用的命令行界面(CLI)和Python软件包,为用户和开发人员提供更无缝的体验。
在本文中,我将演示如何使用CLI和Python来应用YOLOv8来检测静态图像、视频和实时网络摄像头中的物体。
安装
要开始使用YOLOv8,您只需要在终端中运行以下命令即可:
pip install ultralytics
这将通过ultralytics pip包安装YOLOv8。
图像检测
静态图像中的目标检测在各种领域(如监控、医学成像或零售分析)中已被证明是有用的。无论您选择在哪个领域应用您的检测系统,YOLOv8都使您可以轻松实现。下面是我们要对其进行目标检测的原始图像:一张拥挤城市中的交通照片。
为了运行YOLOv8,我们将研究CLI和Python两种实现方式。虽然在这种特定情况下我们将使用jpg图像,但YOLOv8支持各种不同的图像格式。
CLI
假设我们想在一张图片上运行超大型的YOLOv8x(我们将其命名为img.jpg),则可以在CLI中输入以下命令:
yolo detect predict model=yolov8x.pt source="img.jpg" save=True
在这里,我们指定以下参数:detect用于物体检测,predict用于执行预测任务,model用于选择模型版本,source用于提供我们图片的文件路径,save用于保存处理过的图片及其对象的边界框以及它们的预测类别和类别概率。
Python
在Python中,可以使用以下直观且低代码的解决方案实现完全相同的任务:
from ultralytics import YOLO
model = YOLO('yolov8x.pt')
results = model('img.jpg', save=True)
无论是使用CLI还是Python,在任一情况下,保存的处理后的图像如下所示:

我们可以清楚地看到它检测到的每个对象周围的边界框,以及它们对应的类标签和概率。
视频检测
在视频文件上执行对象检测与图像文件几乎相同,唯一的区别是源文件格式。与图像一样,YOLOv8支持各种不同的视频格式,可以作为模型的输入进行处理。在我们的情况下,我们将使用mp4文件。
让我们再次看一下CLI和Python实现。为了更快的计算,我们现在将使用YOLOv8m模型,而不是特别大的版本。
CLI
yolo detect predict model=yolov8m.pt source="vid.mp4" save=True
python
from ultralytics import YOLO
model = YOLO('yolov8m.pt')
results = model('vid.mp4', save=True)
首先,在进行物体检测之前,让我们检查一下我们的原始 vid.mp4 文件:
视频显示了一个繁忙的城市场景,包括汽车、公交车、卡车和骑自行车的人,以及右侧的一些人显然在等公交车。在使用 YOLOv8 的中等版本处理此文件后,我们得到了以下结果。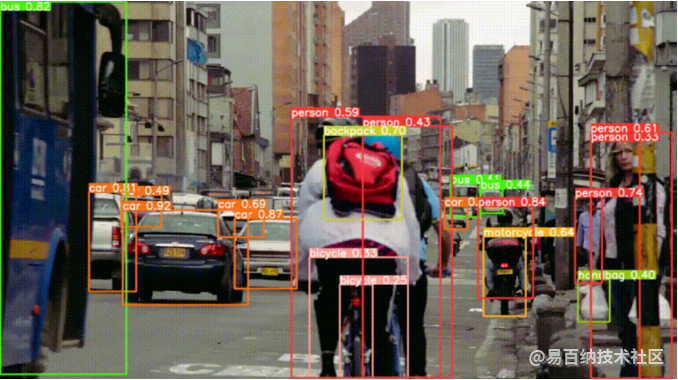
同样,我们可以看到 YOLOv8m 在准确捕捉场景中的对象方面做得非常好。它甚至可以检测到作为较大整体的一部分的较小的物体,例如骑自行车的人佩戴的背包。
实时检测
最后,让我们看一下在实时网络摄像头视频中检测对象所需的内容。为此,我将使用我的个人网络摄像头,就像之前一样,既有 CLI 方法,也有 Python 方法。为了减少延迟并减少视频中的滞后,我将使用轻量级的 YOLOv8 的纳米版本。
CLI
yolo detect predict model=yolov8n.pt source=0 show=True
这些参数大部分与我们上面看到的用于图像和视频文件的参数相同,唯一不同的是source参数,它允许我们指定要使用哪个视频源。在我的情况下,它是内置网络摄像头(0)。
python
from ultralytics import YOLO
model = YOLO('yolov8n.pt')
model.predict(source="0", show=True)
同样,我们可以使用超低代码的Python解决方案执行相同的任务。
这里有一张 YOLOv8n 在实时网络摄像头源上的示例图。

太棒了!尽管视频质量较低,光照条件不佳,YOLOv8仍然能够很好地捕捉到对象,甚至还能检测到背景中的一些物体,例如左侧的橄榄油和醋瓶以及右侧的水槽。
值得注意的是,尽管这些直观的CLI命令和低代码Python解决方案是快速开始对象检测任务的好方法,但它们在进行自定义配置时存在一定的局限性。例如,如果我们想要配置边界框的美学效果或执行简单的任务,例如计算和显示在任何给定时间检测到的对象数量,我们将不得不使用诸如cv2或supervision等包来编写自己的自定义实现。
实际上,上面的网络摄像头录像是使用以下Python代码记录的,以调整网络摄像头的分辨率和自定义定义边界框及其注释。(注:这主要是为了使上面的GIF更具表现力。上面显示的CLI和Python实现足以产生类似的结果。)
import cv2
import supervision as sv
from ultralytics import YOLO
def main():
# to save the video
writer= cv2.VideoWriter('webcam_yolo.mp4',
cv2.VideoWriter_fourcc(*'DIVX'),
7,
(1280, 720))
# define resolution
cap = cv2.VideoCapture(0)
cap.set(cv2.CAP_PROP_FRAME_WIDTH, 1280)
cap.set(cv2.CAP_PROP_FRAME_HEIGHT, 720)
# specify the model
model = YOLO("yolov8n.pt")
# customize the bounding box
box_annotator = sv.BoxAnnotator(
thickness=2,
text_thickness=2,
text_scale=1
)
while True:
ret, frame = cap.read()
result = model(frame, agnostic_nms=True)[0]
detections = sv.Detections.from_yolov8(result)
labels = [
f"{model.model.names[class_id]} {confidence:0.2f}"
for _, confidence, class_id, _
in detections
]
frame = box_annotator.annotate(
scene=frame,
detections=detections,
labels=labels
)
writer.write(frame)
cv2.imshow("yolov8", frame)
if (cv2.waitKey(30) == 27): # break with escape key
break
cap.release()
writer.release()
cv2.destroyAllWindows()
if __name__ == "__main__":
main()
虽然这些代码的细节超出了本文的范围,但以下是一个很好的参考,使用了类似的方法,如果您有兴趣提高自己的对象检测能力:
结论
YOLOv8不仅在准确性和速度方面优于其前身,而且还通过极易使用的CLI和低代码Python解决方案大大提高了用户体验。它还提供五种不同的模型版本,使用户有机会根据其个人需求和对延迟和准确性的容忍度进行选择。
无论您的目标是在静态图像、视频或现场网络摄像头上执行对象检测,YOLOv8都能够以无缝的方式完成。但是,如果您的应用程序需要自定义配置,则可能需要使用其他计算机视觉包,例如cv2和supervision。
- 分享
- 举报
 微信扫码分享
微信扫码分享 QQ好友
QQ好友
 暂无数据
暂无数据-
浏览量:10153次2024-02-02 17:13:35
-
浏览量:5318次2024-02-02 18:15:06
-
浏览量:1980次2023-12-15 17:15:27
-
2023-09-07 13:53:43
-
2024-12-10 11:13:53
-
浏览量:5880次2024-03-05 15:05:36
-
2024-12-10 10:34:18
-
浏览量:6468次2024-05-22 15:23:49
-
浏览量:2732次2023-12-14 17:15:07
-
浏览量:4006次2023-12-19 17:25:07
-
浏览量:4968次2024-11-13 14:14:36
-
2024-02-02 14:41:10
-
浏览量:4317次2023-11-25 17:47:33
-
浏览量:1999次2024-12-10 13:21:45
-
浏览量:4110次2024-02-28 16:15:25
-
浏览量:162次2026-04-14 13:57:02
-
浏览量:2185次2023-12-19 17:38:07
-
浏览量:1731次2023-12-11 16:56:37
-
浏览量:7501次2024-02-28 15:36:09



-
广告/SPAM
-
恶意灌水
-
违规内容
-
文不对题
-
重复发帖

哈撒ki

 微信支付
微信支付
举报类型
- 内容涉黄/赌/毒
- 内容侵权/抄袭
- 政治相关
- 涉嫌广告
- 侮辱谩骂
- 其他
详细说明
审核成功
审核失败



关注公众号
社区问题咨询:Ebaina-CN
定制需求咨询:xxqk158820
